<?php // Полная загрузка сервисных книжек, создан 2026-01-05 12:44:55
global $wpdb2;
global $failure;
global $file_hist;
///// echo '<H2><b>Старт загрузки</b></H2><br>';
$failure=FALSE;
//подключаемся к базе
$wpdb2 = include_once 'connection.php'; ; // подключаемся к MySQL
// если не удалось подключиться, и нужно оборвать PHP с сообщением об этой ошибке
if (!empty($wpdb2->error))
{
///// echo '<H2><b>Ошибка подключения к БД, завершение.</b></H2><br>';
$failure=TRUE;
wp_die( $wpdb2->error );
}
$m_size_file=0;
$m_mtime_file=0;
$m_comment='';
/////проверка существования файлов выгрузки из 1С
////файл выгрузки сервисных книжек
$file_hist = ABSPATH.'/_1c_alfa_exchange/AA_hist.csv';
if (!file_exists($file_hist))
{
///// echo '<H2><b>Файл обмена с сервисными книжками не существует.</b></H2><br>';
$m_comment='Файл обмена с сервисными книжками не существует';
$failure=TRUE;
}
/////инициируем таблицу лога
/////если не существует файла то возврат и ничего не делаем
if ($failure){
///включает защиту от SQL инъекций и данные можно передавать как есть, например: $_GET['foo']
///// echo '<H2><b>Попытка вставить запись в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>$m_comment));
wp_die();
///// echo '<H2><b>Возврат в начало.</b></H2><br>';
return $failure;
}
/////проверка лога загрузки, что бы не загружать тоже самое
$masiv_data_file=stat($file_hist); ////передаем в массив свойство файла
$m_size_file=$masiv_data_file[7]; ////получаем размер файла
$m_mtime_file=$masiv_data_file[9]; ////получаем дату модификации файла
////создаем запрос на получение последней удачной загрузки
////выбираем по штампу времени создания (редактирования) файла загрузки AA_hist.csv, $m_mtime_file
///// echo '<H2><b>Размер файла: '.$m_size_file.'</b></H2><br>';
///// echo '<H2><b>Штамп времени файла: '.$m_mtime_file.'</b></H2><br>';
///// echo '<H2><b>Формирование запроса на выборку из лога</b></H2><br>';
////препарируем запрос
$text_zaprosa=$wpdb2->prepare("SELECT * FROM `vin_logs` WHERE `last_mtime_upload` = %s", $m_mtime_file);
$results=$wpdb2->get_results($text_zaprosa);
if ($results)
{ foreach ( $results as $r)
{
////если штамп времени и размер файла совпадают, возврат
if (($r->last_mtime_upload==$m_mtime_file) && ($r->last_size_upload==$m_size_file))
{////echo '<H2><b>Возврат в начало, т.к. найдена запись в логе.</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>'Загрузка отменена, новых данных нет, т.к. найдена запись в логе.'));
wp_die();
return $failure;
}
}
}
////если данные новые, пишем в лог запись о начале загрузки
/////echo '<H2><b>Попытка вставить запись о начале загрузки в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>0, 'last_size_upload'=>$m_size_file, 'comment'=>'Начало загрузки'));
////очищаем таблицу
$clear_tbl_zap=$wpdb2->prepare("TRUNCATE TABLE %s", 'vin_history');
$clear_tbl_zap_repl=str_replace("'","`",$clear_tbl_zap);
$results=$wpdb2->query($clear_tbl_zap_repl);
///// echo '<H2><b>Очистка таблицы сервисных книжек</b></H2><br>';
if (empty($results))
{
///// echo '<H2><b>Ошибка очистки таблицы книжек, завершение.</b></H2><br>';
//// если очистка не удалась, возврат
$failure=TRUE;
wp_die();
return $failure;
}
////загружаем данные
$table='vin_history'; // Имя таблицы для импорта
//$file_hist Имя CSV файла, откуда берется информация // (путь от корня web-сервера)
$delim=';'; // Разделитель полей в CSV файле
$enclosed='"'; // Кавычки для содержимого полей
$escaped='\
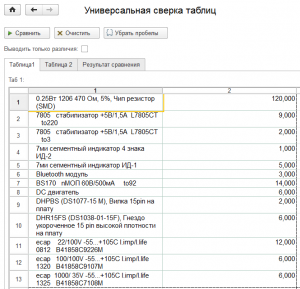








А строки обязательно должны идти в одинаковом порядке для обоих файлов? Или система ищет строку первой таблицы во всех строках второй?
Порядок строк не имеет значения.
Каждый ключ 1-й таблицы ищется в 1 столбце всей 2-й таблицы.
Стоит упомянуть, про механизм сравнения файлов и чем он хуже представленной публикации
Для сравнения файлов имеет значение порядок строк.
Сравнение файлов обращает внимание на различие шрифтов/цвета (если из совсем разных систем копипастим данные — это может сильно мешать).
Сравнение файлов выделяет всю строку, если не нашло её по нужному порядку, хотя она присутствует ниже.
Сравнение файлов таблиц не игнорирует пустое пространство (см скриншот).
Рад, что для сверки таблиц есть и такая возможность.
Дело нужное !
Тоже в своё время создал подобный инструмент.
У меня был прототип на 1С : 7.7 : с выбором начальных строк, колонок для сверки (в какой — Наименование, в какой — значение)
Собственно, вскоре сделал подобное и для v8. Своё уже.
Потом, по пожеланиям форумчан, добавил возможность сверять наименования по нескольким близстоящим колонкам.
Результат можно увидеть :
В принципе, похожие разработки !
Желаю этой разработке успеха !