
Пользователи стали жаловаться, что «Отчет отдела» не проводится по причине ошибки со ставкой НДС.
Разбор проблемы в отладчике показывает, что некоторые позиции номенклатуры документа в регистре «ОстаткиНоменклатуры» имеют ссылку партии номенклатуры типа <Объект не найден>
При перепроведении документа — регистратора проблема уходит. Первое время, пока эта проблема возникала не часто, её так и решали перепроведением документов.
С течением времени, эта проблема стала возникать довольно часто, и назрела необходимость решить её радикально.
Рабочая/тестовая среда:
- Windows Server 2008 R2 Enterprise
- MS SQL Server 2008 R2
- 1С:Предприятие 8.2 (8.2.18.109)
- Конфигурация: Штрих-М: Торговое предприятие, редакция 5.1 (5.1.5.8)
Инструментарий:
- SQL server profiler
- SQL Query
- Консоль запросов 1С
- Обработка «Структура хранения БД»
- SQL сервер 2008: обслуживание, анализ производительности
- SQL Server 2012 Diagnostic Information Queries
Анализ кода
Детальный анализ Общего модуля проведения документов показал, что таблица партий для движений формируется ссылками новых, еще не сохраненных, объектов:

Далее, в отдельной процедуре вновь созданные объекты сохраняются.
Логично предположить, что проблема может иметь место на этапе сохранения вновь созданных объектов справочника Партии Номенклатуры. Осмелюсь предположить, что проблема связана с эскалацией блокировок до уровня таблицы.
Настройка тестовой среды
При помощи обработки Структура хранения БД определяем целевую таблицу SQL
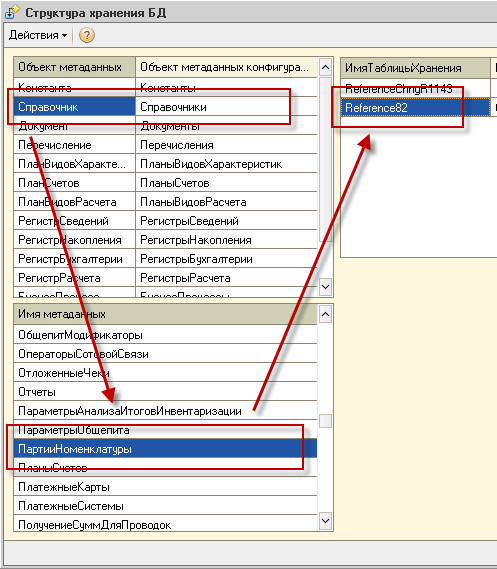
Определяем ID объекта:
USE [trade_debug] Select * from Sys.objects WHERE Sys.objects.name = '_Reference82'

Далее настраиваем трассировку SQL server profiler:
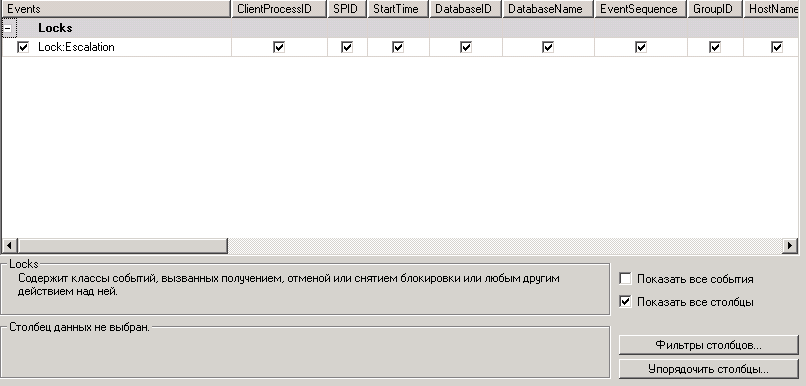
Устанавливаем фильтр:
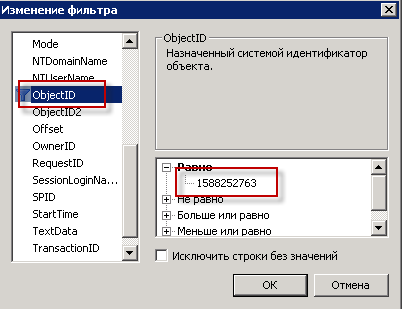
Моделирование ситуации
Не буду подробно останавливаться на всех неудачных попытках смоделировать ситуацию. Расскажу лишь о последней, успешной попытке.
После ряда безуспешных попыток добиться укрупнения блокировок, я вспомнил о доработанной обработке восстановления последовательности документов, которая периодически крутится у нас в фоне.
Итак, запускаем настроенную на нашу таблицу трассировку и выполняем обработку восстановления последовательности… и, вуаля — наши эскалации:

Изучение причин
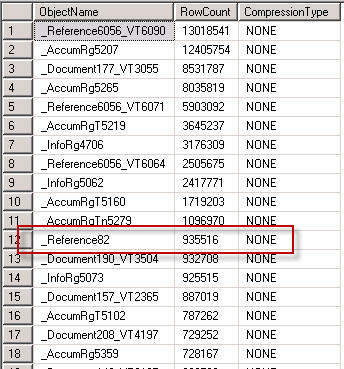
Посмотрим размеры таблицы:
-- Get Table names, row counts, and compression status for clustered index or heap (Table Sizes) SELECT OBJECT_NAME(object_id) AS [ObjectName], SUM(Rows) AS [RowCount], data_compression_desc AS [CompressionType] FROM sys.partitions WITH (NOLOCK) WHERE index_id < 2 --ignore the partitions from the non-clustered index if any AND OBJECT_NAME(object_id) NOT LIKE N'sys%' AND OBJECT_NAME(object_id) NOT LIKE N'queue_%' AND OBJECT_NAME(object_id) NOT LIKE N'filestream_tombstone%' AND OBJECT_NAME(object_id) NOT LIKE N'fulltext%' AND OBJECT_NAME(object_id) NOT LIKE N'ifts_comp_fragment%' AND OBJECT_NAME(object_id) NOT LIKE N'filetable_updates%' AND OBJECT_NAME(object_id) NOT LIKE N'xml_index_nodes%' GROUP BY object_id, data_compression_desc ORDER BY SUM(Rows) DESC OPTION (RECOMPILE); -- Gives you an idea of table sizes, and possible data compression opportunities
Основными причинами эскалации блокировок на уровне SQL server могут быть:
- нехватка памяти
- недостаток индексации таблицы
- нерегулярное обновление статистик
- фрагментация индексов
- процедурный кэш
Большинство причин относится к регламентным процедурам, которые регулярно у нас выполняются. Но не будем слепо их отметать.
Что с памятью:
-- Good basic information about OS memory amounts and state (System Memory) SELECT total_physical_memory_kb/1024 AS [Physical Memory (MB)], available_physical_memory_kb/1024 AS [Available Memory (MB)], total_page_file_kb/1024 AS [Total Page File (MB)], available_page_file_kb/1024 AS [Available Page File (MB)], system_cache_kb/1024 AS [System Cache (MB)], system_memory_state_desc AS [System Memory State] FROM sys.dm_os_sys_memory WITH (NOLOCK) OPTION (RECOMPILE); -- You want to see "Available physical memory is high" -- This indicates that you are not under external memory pressure
С памятью все в порядке:

Недостающие индексы
SELECT TOP 10 [Total Cost] = ROUND(avg_total_user_cost * avg_user_impact * (user_seeks + user_scans),0), avg_user_impact, TableName = statement, [EqualityUsage] = equality_columns, [InequalityUsage] = inequality_columns, [Include Cloumns] = included_columns FROM sys.dm_db_missing_index_groups g INNER JOIN sys.dm_db_missing_index_group_stats s ON s.group_handle = g.index_group_handle INNER JOIN sys.dm_db_missing_index_details d ON d.index_handle = g.index_handle WHERE database_id = DB_ID() ORDER BY [Total Cost] DESC;
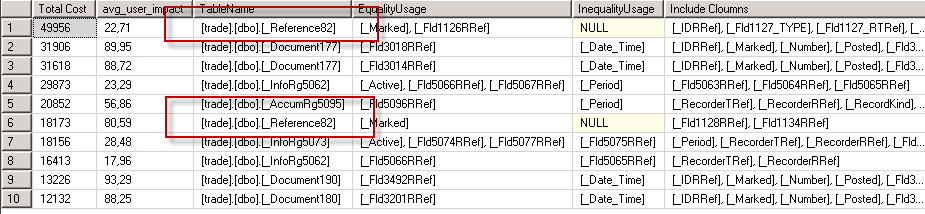
Исходя из текущих данных, не могу сказать, что необходимо бросаться создавать эти индексы (Total cost невелик)
Скорее всего эти данные за небольшой период, можно продолжить наблюдения.
Проверим эффективность текущих индексов таблицы:
-- Possible Bad NC Indexes (writes > reads)(Bad NC Indexes) SELECT OBJECT_NAME(s.[object_id]) AS [Table Name], i.name AS [Index Name], i.index_id, i.is_disabled, i.is_hypothetical, i.has_filter, i.fill_factor, user_updates AS [Total Writes], user_seeks + user_scans + user_lookups AS [Total Reads], user_updates - (user_seeks + user_scans + user_lookups) AS [Difference] FROM sys.dm_db_index_usage_stats AS s WITH (NOLOCK) INNER JOIN sys.indexes AS i WITH (NOLOCK) ON s.[object_id] = i.[object_id] AND i.index_id = s.index_id WHERE OBJECTPROPERTY(s.[object_id],'IsUserTable') = 1 AND s.database_id = DB_ID() AND user_updates > (user_seeks + user_scans + user_lookups) AND i.index_id > 1 and OBJECT_NAME(s.[object_id]) like '%ence82%' ORDER BY [Difference] DESC, [Total Writes] DESC, [Total Reads] ASC OPTION (RECOMPILE); -- Look for indexes with high numbers of writes and zero or very low numbers of reads -- Consider your complete workload, and how long your instance has been running -- Investigate further before dropping an index!

Исходя из этой таблицы, могу сказать, что индекс, созданный по рекомендации SQL (ADD_BY_JAN) для этой таблицы значительно эффективнее нативных 1С-ных.
Проверим фрагментацию индексов:
SELECT TOP 100 DatbaseName = DB_NAME(), TableName = OBJECT_NAME(s.[object_id]), IndexName = i.name, i.type_desc, [Fragmentation %] = ROUND(avg_fragmentation_in_percent,2), page_count, partition_number, 'alter index [' + i.name + '] on [' + sh.name + '].['+ OBJECT_NAME(s.[object_id]) + '] REBUILD' + case when p.data_space_id is not null then ' PARTITION = '+convert(varchar(100),partition_number) else '' end + ' with(maxdop = 4, SORT_IN_TEMPDB = on)' [sql] FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s INNER JOIN sys.indexes as i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id left join sys.partition_schemes as p on i.data_space_id = p.data_space_id left join sys.objects o on s.[object_id] = o.[object_id] left join sys.schemas as sh on sh.[schema_id] = o.[schema_id] WHERE s.database_id = DB_ID() AND i.name IS NOT NULL AND OBJECTPROPERTY(s.[object_id], 'IsMsShipped') = 0 and page_count > 100 and --avg_fragmentation_in_percent > 10 and OBJECT_NAME(s.[object_id]) like '%ence82%' ORDER BY 4, page_count

Фрагментация незначительная
Обновление статистик проводится регулярно:
-- When were Statistics last updated on all indexes? (Statistics Update) SELECT o.name, i.name AS [Index Name], STATS_DATE(i.[object_id], i.index_id) AS [Statistics Date], s.auto_created, s.no_recompute, s.user_created, st.row_count, st.used_page_count FROM sys.objects AS o WITH (NOLOCK) INNER JOIN sys.indexes AS i WITH (NOLOCK) ON o.[object_id] = i.[object_id] INNER JOIN sys.stats AS s WITH (NOLOCK) ON i.[object_id] = s.[object_id] AND i.index_id = s.stats_id INNER JOIN sys.dm_db_partition_stats AS st WITH (NOLOCK) ON o.[object_id] = st.[object_id] AND i.[index_id] = st.[index_id] WHERE o.[type] = 'U' and o.name like '%ence82%' ORDER BY STATS_DATE(i.[object_id], i.index_id) ASC OPTION (RECOMPILE); -- Helps discover possible problems with out-of-date statistics -- Also gives you an idea which indexes are the most active

Процедурный кэш также очищается регулярно.
Таким образом, в данном случае, описанные причины не влияют на эскалацию блокировок.
LOCK_ESCALATION
В SQL server 2008 существует возможность управлять эскалацией блокировок. По умолчанию для таблиц установлено значение TABLE. Мы можем отключить эскалацию. Отключение эскалации чревато дополнительной нагрузкой на память, но с памятью у нас все в порядке, поэтому отключаем её:
USE [trade_debug] ALTER TABLE _Reference82 SET (LOCK_ESCALATION = DISABLE)
Проверить режим эскалации блокировок можно с помощью скрипта:
USE [trade_debug] SELECT lock_escalation, lock_escalation_desc, name FROM sys.tables WHERE lock_escalation_desc='DISABLE'
После отключения эскалации на тестовой базе запускаем ранее настроенную трассировку в профайлере и обработку восстановления последовательности. Трассировка не показала эскалаций для данной таблицы.
В последнее время (до изменений на рабочей базе) жалобы на проблемы с проведением поступали 2-3 раза в неделю. На рабочей после отключения эскалации две недели — полет нормальный. Периодически провожу мониторинг на наличие Партии Номенклатуры <Объект не найден>
ВЫБРАТЬ ОстаткиНоменклатуры.Регистратор, ОстаткиНоменклатуры.Номенклатура, ОстаткиНоменклатуры.Номенклатура.Код, ОстаткиНоменклатуры.Партия ИЗ РегистрНакопления.ОстаткиНоменклатуры КАК ОстаткиНоменклатуры ГДЕ ОстаткиНоменклатуры.Партия.Код ЕСТЬ NULL
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Хм. А мне мнилось, что средствами 1С получить эскалацию на таблице справочников в СУБД не удастся..
После ряда безуспешных попыток добиться укрупнения блокировок, я вспомнил о доработанной обработке восстановления последовательности документов, которая периодически крутится у нас в фоне.
Итак, запускаем настроенную на нашу таблицу трассировку и выполняем обработку восстановления последовательности… и, вуаля — наши эскалации:
Чего ж такого делается в этой обработке восстановления доработанной? )
Ну я думаю следует попробовать управляемые блокировки.
(1) ничего необычного — проведение документов
(2) возможно, но не уверен
Какое-то очень неочевидное предположение. Механизм эскалации если и влияет, то только вместе с другой (серьёзной) программной или архитектурной ошибкой. Мне лично понятно как эскалация может привести к сильному снижению производительности, но непонятно, как (при отсутствии явных ошибок в коде) к неконсистентности в данных.
И, да, анализ причин эскалиции можно сильно упростить. При настройках по умолчанию основной кейс для эскалации «мы выбираем или модифицируем в одной транзакции больше 5000 строк одной таблицы» (это если уровень изоляции на данной таблице REPEATABLE_READ или SERIALIZABLE). Очевидно, что главный претендент на эскалации большие документы (много строк или проводок) или ежемесячные/еженедельные/ежедневные документы. Ищется и подтверждается относительно элементарно (трасса/журнал регистрации). Некостыльное лечение — управляемые блокировки (ксотыльное — запрет на уровне SQL).
Это вообще не так. Механизм эскалации на русском объяснен тут:
Основная причина эскалаций — либо не попадаем в индекс, из-за этого скан, из-за этого блокируем больше, чем ожидали, либо тупо в транзакции много данных. Обслуживанием можно чуть-чуть придавить первую причину, но тоже надеяться не нужно.
Еще.
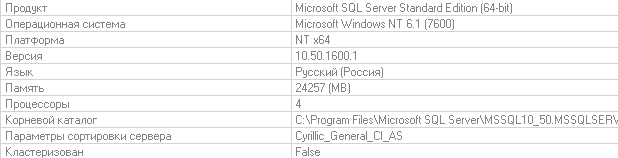
1. Вы говорите, что с обслуживанием всё хорошо. Это не так. Сразу первая картинка — версия SQL 10.50.1600. Т.е. голый без сервис-паков. Простите, но уже их 3 штуки и CU сколько-то.
2. Память тоже анализируете неправильно. (Контрольный «нулевой» вопрос: какой page life expectancy и как он меняется в динамике)
3. Индексы анализируете неправильно (большое количество чтений точно не сигнал, что индекс удачный)
В общем, новичкам читать эту статью — только в качестве сборника ссылок и тренажёра «кто больше неточностей» найдёт.
(4) спасибо за ваше внимание к теме, предположение неочевидное, но подтвержденное экспериментально
регламентные процедуры, да выполняются регулярно, про сервис-паки такого не говорил
осмелюсь спросить, какой должен быть сигнал, что индекс удачный?
Относительно PLE
SEL ECT [object_name],
[counter_name],
[cntr_value]
FR OM sys.dm_os_performance_counters
WHERE [object_name] LIKE ‘%Manager%’
AND [counter_name] = ‘Page life expectancy’
12400 — 12700
Первопричина, как я понял, все таки в ошибочной реализации — нет логической целостности этапов записи новых элементов справочника партий с записью документа.
Именно это и приводит к появлению битых ссылок.
Эскалация, в данном случае, это причина сбоев при записи партий. Вылечив только её (до следующей реструктуризации справочника), основная проблема осталась не решена — партии могут перестать записываться и по какой то другой причине и вы опять получите битые ссылки.
вот и непонятно, как подтверждённое. Если там не было дедлоков и таймаутов и кривого кода, то мне непенятен механизм как эскалации влияют на целостность. А если там таймауты и дедлоки, то вы их могли просто отодвинуть.
(7) буду продолжать наблюдения
нехватка памяти
недостаток индексации таблицы
нерегулярное обновление статистик
фрагментация индексов
процедурный кэш
Экскалация происходит при записи в транзакции вполне конкретного количества записей хорошо известных как для СУБД (с небольшим разбросом, зависит только от памяти), так и для 1С 8.2 и 8.3.
(1)AlX0id,
В чем проблема то? Начинаем транзакцию, записываем 20000 элементов для 8.2 (60000 для 8.3 (могу ошибится, не помню точно)) и завершаем транзакцию. Что собственно и происходит у автора, когда записываются документы с табличными частями более чем 20000 строк.
(4) speshuric,
По моему явная ошибка хорошо показана в статье, запись элементов справочника партии вынесена непойми куда))
Эскалация блокировок ПРИНЦИПИАЛЬНО не может быть первопричиной нарушения целостности данных.
Если эскалация блокировок приводит к нарушению целостности данных — налицо явная архитектурная ошибка.
(9) qwinter,
Ни разу не будет эскалации. На СУБД, по крайней мере. Судя по цифрам, вы говорите об управляемых блокировках — там будет. В 8.3 — со 100000 эскалация на упр. блокировках.
Если внимательно прочитать статью — эскалация происходит на таблице СПРАВОЧНИКА. На СУБД.
Моя ошибка в (1) была в том, что я предположил, что у автора управляемые блокировки %) А в автоматическом режиме и на чтении будет эскалация — попробовал у себя, при магическом числе 6154 в SELECTе — начинается эскалация на SQL 2012. При чем при включении флага 1224 — исчезает.. С чем связан именно такой порог было бы очень интересно узнать ) В документации по SQL — только про 5000 написано..
(12) AlX0id,
Естественно!! у автора на каждую строчку тч записывается элемент справочника.
(13) ребята, эскалацию на справочнике мне удалось добиться только при массовом перепроведении документов
при записи в транзакции — только блокировки, причем образования ссылок объект не найден так и не удалось добиться…. очень тонкий момент, отловить его не удалось
конфа старая. измененная — об управляемых блокировках речь не идет, тем более таблица справочника
там не на каждую строчку идет запись…..: Если СтрокаПартия = Неопределено
Писал я по 10 000 элементов почти одновременно в трех сессиях без транзакции — никаких проблем.
(13) qwinter, (14)
Хоть по 300000 операций записи в одной транзакции.. если памяти хватит — но проблем, эскалации в СУБД не будет. 1С не умеет писать справочники пачками, а при наложении блокировок по одной — они не эскалируются в СУБД.
(12) AlX0id,
:
5000+1250 (пессиместичный вариант) = 6250
(16) speshuric,
Как бы все равно не очень очевидно )
Получается, что при наложении от 5000 до 6250 блокировок в одной инструкции — есть шанс того, что будет эскалация, а свыше 6250 — 100%. При условии, что это новые блокировки, конечно.
(2) новые конфы штриха с управляемыми блокировками, попробую либо перейти на свежие релизы либо внедрить управляемые блокировки в старый релиз и дополню статью результатами перехода
(7) при трассировке видно, что сначала идет несколько эскалаций подряд, затем дедлок
снимая эскалации — избавляемся от дедлока…. пока работает
будем посмотреть дальше
(2) не пойму, почему управляемые блокировки преподносятся как панацея….