Как один из примеров эффективного решения технологической задачи для 1С — использовать ElasticSearch для хранения истории изменений объектов информационной базы.
ElasticSearch разрабатывается крайне успешным стартапом в Калифорнии с 2012 года — https://www.elastic.co/.
Позволяет загрузить в единое хранилище данных разнородную информацию в JSON-формате, а затем производить выборки детальной и агрегированной информации.
Это не реляционная база данных. Взаимосвязей между разнородными объектами нет, поэтому сфера применений для учетных задач ограничена, но многие технологические задачи можно решать весьма эффективно.
Основные преимущества для пользователей 1С при хранении истории изменений объектов в ElasticSearch:
1) Не требуется сложного конфигурирования и установки ElasticSearch. Только скачать и распаковать архив, а затем запустить bat-файл (работает поверх JAVA).
2) Вся информация хранится во внешнем, по отношению к информационным базам 1С, хранилище данных. Основная база данных не перегружается «балластом».
3) ElasticSearch индексирует ВСЮ загружаемую информацию. Практически любая небольшая выборка данных с любыми условиями будет выполняться за миллисекунды.
4) При изменении структуры метаданных в 1С не требуется проводить реструктуризацию в ElasticSearch. Удаленные поля будут доступны в предыдущей информации, новые — в новой.
Особенности, которые важно учитывать:
Например:
1) все поступающие строковые поля ElasticSearch автоматически разбивает на слова и индексирует отдельно. т.е. теоретически можно искать информацию по всему массиву разнородных объектов просто указав ключевое слово. На практике это выливается в некоторые проблемы, например, с GUID. Переданные для поиска GUID система разбивает на части по символу «-» и выдает совсем нерелевантный результат. Чтобы этого не происходило нужно отключить «анализ» поля перед записью первых объектов отправив команду на типизацию таких полей для данного вида объектов.
В данном примере мне этого делать не хотелось, поэтому для ключевых полей, по которым происходит выборка версий, из GUID’а удалены тире, что сделало его монолитным «словом». Это решает задачу выборки данных для отчета по версиям. Если нужны иные варианты выборок, то нужно предусмотреть эту особенность.
2) Если объект сериализовать в XML, то платформа в атрибутах указывает тип значения для каждого ссылочного реквизита, в итоге обратная десериализация проблем не вызывает. Аналогичный механизм для JSON появится только в платформе 8.3.7 — http://v8.1c.ru/o7/202601json/index.htm.
В итоге для однозначной идентификации значения в реквизитах объектов мне показалось удачным использовать функцию ЗначениеВСтрокуВнутр.
3) ElasticSearch не поддерживает версии объектов. Поэтому каждую версию нужно хранить как уникальный объект, а логически наборы версий объединять по дополнительному полю.
Отмечу, что выложенный пример конфигурации не является полноценным решением, а лишь демонстрирует способ применения механизма, хотя и вполне применим для продуктивной системы.
Разработано и протестировано на 8.2 и 8.3.
Для сериализациидесериализации в JSON используется разработка Александра Переверзева //infostart.ru/public/119601/
Принципиальная схема работы:
1) В подписке на событие «ПриЗаписи» выполняется сериализация объекта в JSON.
2) Добавляется служебная информация типа даты изменения и автора версии.
3) Данные синхронно записываются в ElasticSearch до окончания транзакции. Т.е. при отмене транзакции версия останется. Это можно решить, переделав механизм на асинхронный: при изменении объекта фиксировать сам факт, а в отдельном фоновом задании выполнять сериализацию в JSON и отправку данных. У обоих вариантов свои плюсы и минусы.
4) В отчете по версиям система выбирает 10 последних версий объекта и отображает их реквизиты. Каждый результат поиска также возвращает общее количество найденных объектов, поэтому всегда можно получить программно все объекты.
Для запуска механизма на своей базе необходимо:
1) Установить на целевой машине JAVA и прописать переменную JAVA_HOME.
2) Скачать и запустить ElasticSearch.
3) Объединить целевую конфигурацию с файлом Elastic.cf (2 общих модуля, 2 константы, 2 подписки на события, 2 обработки).
4) скорректировать подписки на события — указать только те объекты, которые необходимо версионировать. Можно оставить как есть (все объекты), но в крупных базах с интенсивной работой, скорее всего, будут проблемы с быстродействием.
5) В режиме Предприятия заполнить константы.
АдресИнстанса — имя компьютера и порт с ElasticSearch (для локальной машины — localhost:9200).
ПрефиксБазы- произвольный идентификатор текущей ИБ латинскими строчными буквамицифрами (чтобы данные нескольких баз не перемешивались), например, «buh1».
Попробовать записать любой версионируемый объект и удостовериться через обработку «ElasticSearch_ПросмотрВерсий», что данные записались в ElasticSearch и выдаются обратно.
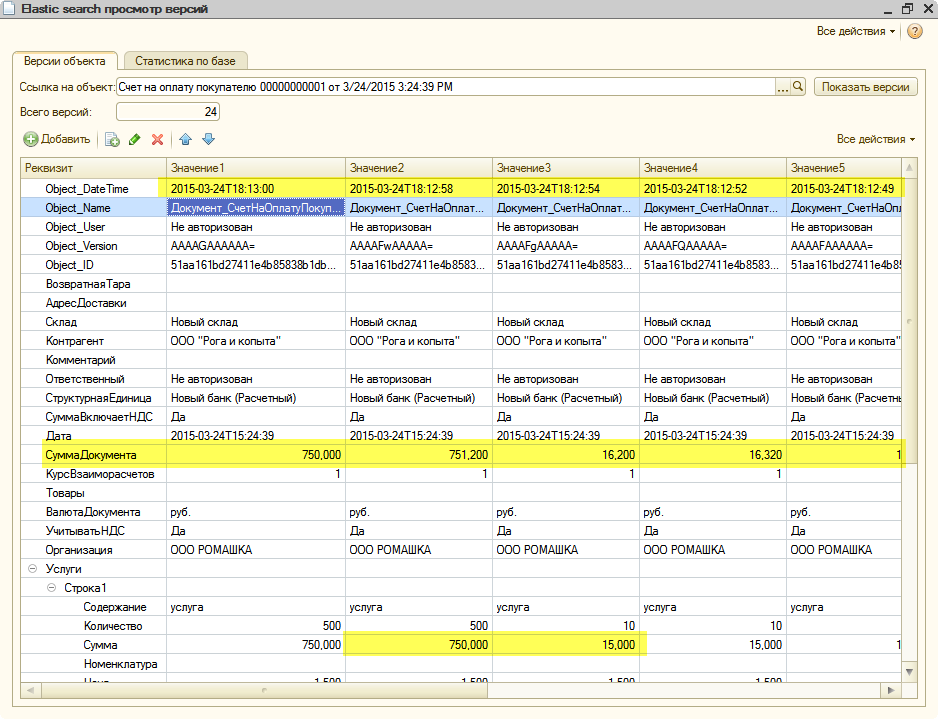
Список версий по документу:
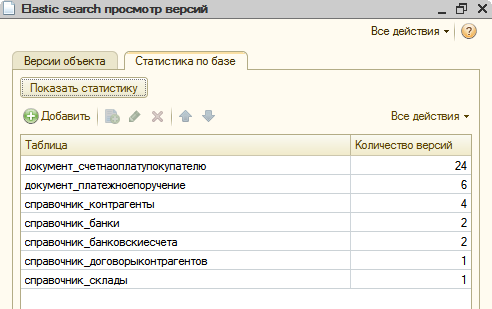
Статистика по версиям в базе ElasticSearch:
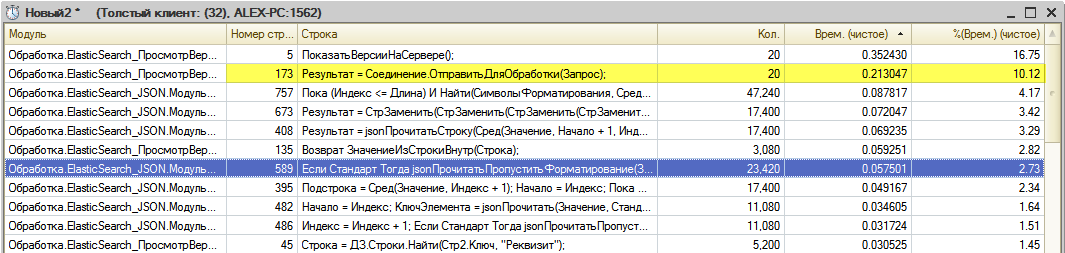
По поводу быстродействия — я не тестировал именно журнал изменений объектов на больших данных. Но анализ объемного технологического журнала показал, что скорость выборки 10-20 событий из индекса с парой тысяч записей и с 20’000’000 записей примерно одинакова.
Судя по замеру в данном примере — на выполнение 20 запросов, каждый из которых возвращает 23Кб JSON, потребовалось 0,2 секунды.
P.S. На подходе два аналогичных механизма для технологического журнала и журнала регистрации.
Планирую сделать на базе своих существующих разработок:
Периодическая загрузка событий из журналов регистрации в базу MS SQL Server (с исходниками)
Загрузка файлов технологического журнала в базу MS SQL (с исходниками)
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Интересно, в общем-то )
ЗЫ. Open sourCe все-таки 😉
Производительность — управляемость, в отличии от полнотекстового поиска 1с, шардинг по нескольким серверам.
Для логов, советую kinbana или graphite использовать, для отображения данных, очень удобно.
Если есть более или менее четкая структура, то можно настроить, что-бы не разбивал в индексе по словам, ну или в поиске по uuid обрамлять в кавычки, тогда должен искать полный uuid.
Очень лыбопытное решение. Радует опенсорс. Думаю многие смогут проверить каково это — жить с историей версий объектов.
Если уж нужно делать синхронно, то есть, как минимум, обработчик ПослеЗаписи который выполняется вне транзакции.
(6) yukon, не в том контексте интерес
зы в любом случае лучше делать ассинхронно…иначе увеличивается время транзакции
(6) yukon,
Такой обработчик есть только для управляемых форм. т.е. тогда будет работать только при интерактивном изменении данных.
(0) я так понимаю следующим ты попробуешь LogStash, Kibana ? И тогда добро пожаловать в наш мир.
(8) ИМХО Нужно юзать механизм заданий, которые и будут выполняться вне текущей транзакции.
Т.е. создаешь новое задание (РС или справочник), заносишь нужную инфу и завершаешь транзакцию.
и крутится фоновое задание, которое следит за заданиями, формирует из них очередь (при необходимости), запускаю нужное количество агентов (фоновое задание-обработчик), задание выполняется на агенте и в случае успешной записи выполняет удаление ранее сделанной записи (из РС или справочника).
удобно и довольно мощно.
Мы такую систему юзаем и нам хорошо 🙂
(9) Kibana уже попробовал. Для построения самого разного рода графиков подходит отлично. Но для более глубокого анализа данных мне показалось удобнее писать свои запросы к Elastic, пусть хоть и на 1С.
LogStash — в процессе. Может к разбору технологического журнала получится подключить..
(10) artbear,
Да, я согласен.
Смущает только один момент — если версионировать до окончания транзакции, то нет необходимости читать или записывать какие-либо данные. Объект уже в памяти.
При асинхронном версионировании — сначала записать факт изменения в регистр, затем прочитать эти события, прочитать объект из базы и отправить версию в Elastic, затем сделать отметку о том, что обработка данного события завершена.
Имхо, оба варианта имеют право на жизнь.
Все же считаю использование ElasticSearch — стрельбой из пушки по воробьям. Поисковый движок для версионирования по моему слишком
А можно поподробнее прокомментировать вот это: «при изменении объекта фиксировать сам факт, а в отдельном фоновом задании выполнять сериализацию в JSON и отправку данных» ?
(14) Dach, в РС записывать всю информацию, но не пересылать в ElasticSearch.
от сериализации в данном случае не уйти…но таким образом сокращаем время транзакции.
В фоновом задании просто берем пачку новых объектов и передаем в ElasticSearch…после корректной передачи — удаляем из РС запись
(13) minimajack, ну для логов же их используют, а там вообще простые текстовые файлы на N-гиг.
Тем более, что в данном примере elasticsearch не настраивали на игнорирование разбивку на составляющие некоторых данных (таких как uuid)
(16) pumbaE, я говорю именно про хранение версий.
Во первых поиск на 99% будет выполнятся по гуидам
Во вторых интересует именно различия — а не поиск чего то — где то
В третьих проверил подобный вариант с — сериализация XML быстрее, от стандартного механизма «Версионрования» практически не отличается
(2)Ты комментарий то как написал? Из какой операционной системы? А если надо просмотреть офисный документ, ты что используешь? А еще ты пишешь на сайте который находится в интернете, который таки придумали американцы, развили до текущего состояния американцы и контролируют(icann) тоже представь себе американцы.
(18) webester, ну зачем кормить тролля…
Добрый день. Возникли сложности при внедрении данного функционала, в связи с этим хочу уточнить несколько моментов:
1. Скажите, какое значение мне нужно заполнить в графе АдресИнстанса — имя компьютера и порт с ElasticSearch? Работаю по SQL.
2. Установить на целевой машине JAVA и прописать переменную JAVA_HOME. JAVA стоит на машине, а переменную где прописать. И если не затруднить, может укажите ссылку на конкретную JAVA.
(21) reflexcompani,
1) Для константы «ElasticSearch_АдресИнстанса» надо указать хост и порт на котором расположен запущенный ElasticSearch.
Например, «localhost:9200» — это если ElasticSearch установлен на той же машине, где будет исполнятся код.
Если это другая машина — должно быть указано сетевое имя или IP-адрес вместо localhost. Ну и в firewall этот порт должен быть открыт.
2)
скачать JAVA —
Интересно
Внешнее хранилище — интересно! Но тезис о полном восстановлении предыдущего состояния… это по моему слишком для учетной системы.
В 90% случаев требуется именно сведения об изменениях! Соответственно, только перед записью приходится анализировать различия записанного и нового объекта… Но смена порядка строк в ТЧ так же выдается за изменение большинством систем Верификации! Лично я решал проблему сверткой ТЧ «Товары» и анализировал свернутые Количества и Суммы. Выявляя добавленный и выведенный ассортимент.
Правда, в моей реализации писалось в ЖР и не зависимо от завершения транзакции. Откидывать ошибочные записи приходилось по анализу штатных записей ЖР.
Но для задач расследований, этого вполне достаточно было.
Добрый день! У меня выходит такое сообщение ElasticSearch_ПросмотрВерсий.ПоказатьВерсииНаСервере (IndexMissingException[[versions_BU] missing] )
(25) Elena_Q,
Судя по всему, отсутствует индекс с таким именем. Посмотрите отладчиком как отправляется запрос в ES и какой возвращается результат. Вероятно, при каждой попытке записи версии в базу возникает ошибка, поэтому индекс в ES и не создался.
Чтобы посмотреть статистику по индексам в ES — откройте вот эту ссылку (только не в IE)
Спасибо за ответ. Посмотрю
Возвращает:
{
«_shards» : {
«total» : 0,
«successful» : 0,
«failed» : 0
},
«_all» : {
«primaries» : { },
«total» : { }
},
«indices» : { }
}
это значит ничего не отправляется?
(28) Elena_Q,
Да, значит в базе ES ничего нет.
Посмотрите отладчиком результат ответа при попытке отправки HTTP-запроса в ES — там должна быть видна ошибка.
Искал механизм на замену стандартному… действительно в специализированную БД лучше бы сохранять XML-ки/JSON-ки
… стало грустно что люди ещё так делают…
Собственно погрустнело ещё больше…
(30) пиши в регистр, потом асинхроно переноси в отдельное хранилище — тут имхо проблемы нет подкорректировать.
У меня на распределенных базах так шардинг был настроек, в каждой точке свой elasticsearch, в центральном кластере все логи собираются. Плюс на машинках с java еще и logstash подключаен для журнала регистрации, который так же в elasticsearch скидывается.
{«error»:{«root_cause»:[{«type»:»illegal_argument_exception»,»reason»:»Fielddata is disabled on text fields by default. Set fielddata=true on [Object_Version] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory.»}],»type»:»search_phase_execution_exception»,»reason»:»all shards failed»,»phase»:»query»,»grouped»:true,»failed_shards»:[{«shard»:0,»index»:»versions_tok»,»node»:»1SikbqSxRE-jyaQTSIOjOQ»,»reason»:{«type»:»illegal_argument_exception»,»reason»:»Fielddata is disabled on text fields by default. Set fielddata=true on [Object_Version] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory.»}}],»caused_by»:{«type»:»illegal_argument_exception»,»reason»:»Fielddata is disabled on text fields by default. Set fielddata=true on [Object_Version] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory.»}},»status»:400}
У меня вот такую ошибку выдает.
(32) Устранить проблему поможет данный скрипт. Проще всего его выполнить в git bash, ну или установить curl отдельно, если гитом не пользуетесь.
Префикс базы у менят «w1», его поменяйте на свой. Также и адрес эластика, я оставил по-умолчанию, смените, если надо, ‘localhost:9200’ на свой.
Кстати, префикс не может содержать заглавных букв, запросы вылетают с ошибкой.
curl -XPUT ‘localhost:9200/versions_w1/_mapping/Object_ID?update_all_types’ -H ‘Content-Type: application/json’ -d’
{
«properties»: {
«Object_ID»: {
«type»: «text»,
«fielddata»: true
}
}
}
‘
curl -XPUT ‘localhost:9200/versions_w1/_mapping/Object_DateTime?update_all_types’ -H ‘Content-Type: application/json’ -d’
{
«properties»: {
«Object_DateTime»: {
«type»: «date»,
«fielddata»: true
}
}
}
‘
curl -XPUT ‘localhost:9200/versions_w1/_mapping/Object_Name?update_all_types’ -H ‘Content-Type: application/json’ -d’
{
«properties»: {
«Object_Name»: {
«type»: «text»,
«fielddata»: true
}
}
}
‘
curl -XPUT ‘localhost:9200/versions_w1/_mapping/Object_User?update_all_types’ -H ‘Content-Type: application/json’ -d’
{
«properties»: {
«Object_User»: {
«type»: «text»,
«fielddata»: true
}
}
}
‘
curl -XPUT ‘localhost:9200/versions_w1/_mapping/Object_Version?update_all_types’ -H ‘Content-Type: application/json’ -d’
{
«properties»: {
«Object_Version»: {
«type»: «text»,
«fielddata»: true
}
}
}
‘
Мой предыдущий пост актуален для версии 5.6.3.
Похоже, за 2,5 года с момента публикации, в эластике многое изменилось концептуально, т.к. по инструкции автора не взлетает моментально.