


Задача возникла при попытках поиска элементов справочника номенклатуры для обновления значений реквизитов. Суть проблемы заключалась в неуникальности реквизитов для поиска (артикул, например) в пределах всего справочника, что приводило к ложной подстановке обновляемых реквизитов.
В итоге, в качестве решения проблемы разработана модель сравнения наименования найденного элемента справочника с наименованием элемента, необходимого для обновления реквизитов. Таким образом, мы отсеиваем полностью несовпадающие по наименованию элементы справочника при неуникальных остальных реквизитах, по которым мы пытаемся спозиционироваться на элемент.
Существуют масса алгоритмов определения степени сходства 2-х текстов, после изучения которых, был выработан следующий алгоритм:
- Вычисляем длины наименований
- Принимаем за эталон наибольшую длину (для организации цикла)
- Принимаем наименование с наибольшей длиной за эталонную строку
- Попарно вычисляем число вхождений в обоих наименованиях каждого символа из эталонной строки
- Удаляем из наименований символы, для которых произведён поиск
- Складываем общее количество вхождений для каждого наименования
- После цикла вычисляем степень сходства по формуле (результат в процентах):
Здесь, "Вхождение1" — общее число вхождений каждого символа эталонной строки в первое наименование, "Вхождение2" — общее число вхождений каждого символа эталонной строки во второе наименование.
Перед вычислением по формуле, в условном операторе, необходимо определить какое из наименований имеет наибольшее число вхождений.
Ниже представлен полученный код для платформы 1С Предприятие 7.7. Принимаются предложения по оптимизации.
//возвращает процент сходства 2-х наименований
Функция СходствоНаименований(Знач Наим1="",Знач Наим2="")
Наим1 = СокрЛП(Наим1);
Наим2 = СокрЛП(Наим2);
Наим1 = СтрЗаменить(Наим1," ",""); //Удаляем двойные пробелы
Наим1 = СтрЗаменить(Наим1," ",""); //Удаляет одинарные пробелы
Наим2 = СтрЗаменить(Наим2," ","");
Наим2 = СтрЗаменить(Наим2," ","");
//проверяем значения на схожесть
Длина1 = СтрДлина(Наим1);
Длина2 = СтрДлина(Наим2);
Если Длина1 > Длина2 Тогда
Длина = Длина1;
Стр = Наим1;
Иначе
Длина = Длина2;
Стр = Наим2;
КонецЕсли;
Сч = 0; Вхождение1 = 0; Вхождение2 = 0;
Пока (Стр<>"") Цикл
Символ = Лев(Стр,1);
Вхождение1 = Вхождение1+СтрЧислоВхождений(Наим1,Символ);
Вхождение2 = Вхождение2+СтрЧислоВхождений(Наим2,Символ);
Наим1 = СтрЗаменить(Наим1,Символ,"");
Наим2 = СтрЗаменить(Наим2,Символ,"");
Стр = Прав(Стр,СтрДлина(Стр)-1);
КонецЦикла;
Возврат ?(Вхождение1>Вхождение2,Окр((Вхождение2/Вхождение1)*100,3,1),Окр((Вхождение1/Вхождение2)*100,3,1));
КонецФункции //СходствоНаименований()
Выявленные преимущества алгоритма:
- Время исполнения кода на очень хорошем уровне (меньше 0.0001 сек.)
- Переносимось алгоритма (не нужно подключать внешние компоненты)
- Выходной показатель (процент степени сходства) соответствует различию входных данных
Выявленные недостатки:
- Чувствительность алгоритма к сильному различию в количестве символов 2-х наименований (показатель степени сходства быстро снижается)
- При простой перестановке символов в разных наименованиях результат будет 100% сходства, что неверно.
Результаты экспериментов
Эксперимент 1:
- Наименование1 = "A0900001N Угольник 1"х1"
- Наименование2 = "CJ 65 V3 Лобзик"
- Результат = 13.636%
Эксперимент 2:
- Наименование1 = "Cъемник рулевых тяг и шаровых опор TOYA"
- Наименование2 = "Cъемник рулевых тяг и шаровых опор 2-х позиционный, зев 20 мм"
- Результат = 56.863%
Эксперимент 3:
- Наименование1 = "MF 800 VE миксер Felisatti"
- Наименование2 = "MF1200/VE2 миксер Felisatti"
- Результат = 84.000%
Возможное решение описанных выше недостатков
Метод написан на базе платформы 1С:8 пользователем DrBlack
Функция ПолучитьПроцентСходстваНаименований_2(Знач НаимСравн="", МассивСлов, ОбщДлинаСлов)
СуммаСовпадений = 0;
Для Каждого ТекСлово Из МассивСлов Цикл
Если СтроковыеФункцииКлиентСервер.ТолькоЦифрыВСтроке(ТекСлово) Тогда
СчНачало = СтрДлина(ТекСлово);
Иначе
СчНачало = Макс(3, СтрДлина(ТекСлово)-4);
КонецЕсли;
МаксСовпадений = 0;
Для Сч = СчНачало По СтрДлина(ТекСлово) Цикл
ТекОтрезокЛево = Лев(ТекСлово, Сч);
ТекОтрезокПрав = Прав(ТекСлово, Сч);
МаксСовпадений = Макс(МаксСовпадений, ?(СтрЧислоВхождений(НаимСравн, ТекОтрезокЛево)>0, Сч, 0), ?(СтрЧислоВхождений(НаимСравн, ТекОтрезокПрав)>0, Сч, 0));
КонецЦикла;
СуммаСовпадений = СуммаСовпадений + МаксСовпадений;
КонецЦикла;
ПроцентСовпадения = Окр(Мин(ОбщДлинаСлов, СуммаСовпадений) / ОбщДлинаСлов * 100, 3, 1);
Возврат ПроцентСовпадения;
КонецФункции
Входные параметры:
НаимСравн — строка, с которой надо сравнить
МассивСлов — эталонная строка, заранее разбитая на составляющие
ОбщДлинаСлов — общая длинна слов в МассивСлов для вычисления коэф. схожести
Суть данного метода — устранить недостатки метода из топика.
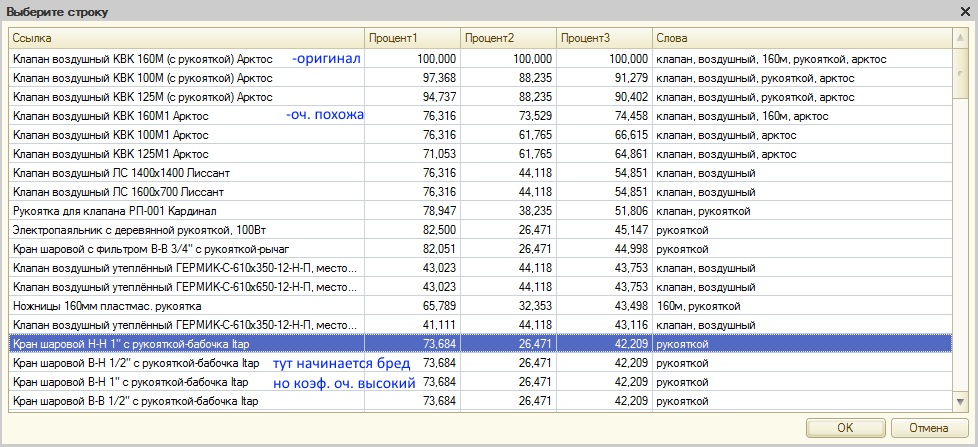
Описание колонок на скрине:
Процент1 — сравнение методом из топика
Процент2 — сравнение методом пользователя DrBlack по вхождению слов (не короче 4х символов)
Процент3 — усредненный коэф (Процент1 + Процент2 х 2) / 3
СПАСИБО ЗА ВНИМАНИЕ!
[Обновление, 15.10.19] Добавлены обработки для 1С7.7 и 1С8.х, реализующие задачу при помощи алгоритмов из публикации.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Без толковой внешней компоненты, реализующей нечеткое сравнение, толку от подобной обработки мало.
Как будете оценивать степень сходства у «Cъемник рулевых тяг» и «Cьёмник руливых тяг» ?
Посмотрите, например, на
(1) vcv, для такого сравнения, алгоритм даст результат около 100% (а точнее 97%). Что, собственно, и требуется для реализации.
Не стояла задача организации нечеткого сравнения. Поскольку обработка происходит для большого объема данных, результат должен выдаваться за минимальное количество времени. Полученный процент существенно вносит ясность в различие, что достаточно для принятия решения.
Поэтому ваша критика несущественна. Но все-равно спасибо за отзыв!
идея хорошая 🙂
(0) Больше того, что-то сомнительно, что ищете действительно «Сходство», а не нечто другое. Поясню на примере:
Первое наименование: «АБВГДЕЖЗИЙКЛМН»
Второе наименование: «НМЛКЙИЗЖЕДГВБА»
(одно отличается от другого просто тем, что записано наоборот).
Для каждого символа будет найдено ровно одно вхождение.
Что, 100% сходство?
(4) kapustinag, Точно, «кран» и «нарк» близнецы-братья со 100% совпадением %)
(4) kapustinag, вы правы, есть недостаток алгоритма в этом плане. Но поскольку простая перестановка символов в строке приводит к потере смысла наименования (строка становится случайным набором символов), то этот момент тоже несущественен. Никто не будет создавать наименование с непонятным набором символов, который случайно совпадёт с другим наименованием по частоте вхождений символов.
Ваши предложения по доработке?
Посмотрите на ВК отсюда:
Она может найти схожесть между такими наименованиями как «Водка Посольская» и «Vodka Posolskaja»
Присоединяюсь к (1) и (4). Такое надо в ВК выносить, на 1С слишком муторно все будет
(7) JohnyDeath, к сожалению, не будут удовлетворены требования производительности.
Спасибо за ссылку на публикацию.
Приведённый алгоритм тоже имеет право на существование и успешно доказал свою применимость.
(8) В том-то и дело, что границы применимости данного алгоритма не сформулированы. Пытался вчитаться в начальные абзацы статьи, но… не вышло у меня. И фразы вроде » процент существенно вносит ясность в различие» — мне не помогли.
Ясно только, что это не «нечеткое сравнение», как сказано в (2).
Хотелось бы формулировок в виде «из записей с одинаковым артикулом отсеивали те, которые содержат совсем непохожие наименования, а те, что остались, предлагали для ручного выбора».
Кстати, без ВК обходились в .
(9) gaglo, поиск решения такой простейшей задачи всегда остаётся актуальным, поскольку идеальных решений не существует. Меня заинтересовала разработка самого быстрого алгоритма, который удовлетворит поставленным задачам. И данный алгоритм во всём удовлетворил моему техническому заданию. Поэтому я его и представил на суд сообществу.
К сожалению, ни один из критикантов не предложил способов улучшения метода без существенного усложнения, кроме как взять готовый ВК. Поэтому вижу свою затею в публикации статьи пустой!
П.С. Я старался доходчиво объяснить применимость метода, но, видимо, очень по-простому не умею.
То, что результатом сравнения будет ерунда уже писали выше.
Также непонятно зачем нужна 1-я строчка в
Наим1 = СтрЗаменить(Наим1,» «,»»);
Одной второй недостаточно?
ИМХО правильно было бы сравнивать не вхождение символов а целых слов. Здесь тоже куча подводных камней в виде окончаний, опечаток и пр. Вот для сравнения отдельных слов предложенный алгоритм худо бедно подошел бы, только надо добавить контроль позиции символов в проверяемых словах при сравнении.
То, что «алгоритм быстрый» малоценно, т.к. на выходе чушь. Выдаваемые проценты — цифра ни о чем. Что там автор получил подсчитав количество одинаковых буковок в 2х строчках для меня загадка.
(11) loekyn, первая строка удаляет двойной пробел, вторая одинарный. Замена одинарного пробела на пустой символ в некоторых случаях не отрабатывает замену двойного. Если не верите, можете самолично провести эксперимент.
На выходе не чушь, а объективные данные, которые помогли решить проблемы. Смотрите раздел «Результаты экспериментов».
(10)
Сильно подозреваю, что использование ВК будет работать быстрее, чем посимвольное перебирание строк на языке 1С.
Ну прямо «критикантов»! Вы взялись за задачу, которая нормального решения без ВК не имеет. Без ВК получается или хреново, или тормозно. Тормозно, конечно, относительно возможных объёмов. Вот у меня порядка 20 тысяч номенклатурных позиций. Средняя длина наименований порядка 40-50 символов. Слабо представляю, что бы по такому объёму искать схожие наименования посимвольным перебором.
Если никак нельзя ВК…
Попробуйте заменять в наименовании буквы на фонетически сходные. Например, в наименовании «Водка Посольская» заменять В на Ф, О на А, З на С и так далее. Символы вроде Ь Ъ совсем убирать. Все знаки препинания заменять на пробелы. Заменять сходно написанные латинские буквы на русские. Строки, естественно, привести к единому регистру. Получившуюся строку поделить по словам.
Два списка слов из двух строк уже сравнивать.
Когда-то стояла задача найти в справочниках «одинаковые» адреса торговых точек. Код приводить не буду. Распишу простым язком алгоритм, который использовал для сравнения строк.
1. Обрезать пробелы слева и справа и привести обе строки в верхний регистр.
2. Убрать мусор (точки, запятые, скобки)
3. Найти самую длинную совпадающую последовательность символов. Запомнить её длину и вырезать из сравниваемых строк.
4. Из оставшегося опять найти самую длинную последовательность символов и ёё длину приплюсовать к результату пункта 3.
Так до тех пор пока не останутся одиночные символы.
5. Вычислить отношение полученного результата к максимуму длин двух строк.
Получаем показатель от 0 до 100% насколько адреса совпадают.
P.S. В алгоритме нужно ограничить минимальную длину последовательности получаемую в пунктах 3 и 4 (опытным путем от 2х до 4х символов), а то получим сумму из единичек по всем символам.
(13) vcv,
Работа с ВК по производительности в РАЗЫ дольше, чем простым перебором символов. Откройте отладчик и проверьте 2 куска кода, выполняющих аналогичную задачу, но один из которых использует ВК.
Вы это утверждаете, потому что сами представления не имеете как это сделать.
Наконец хоть какой то совет. Благодарю.
(14) Vortigaunt, класс! Надо попробовать.
(10) хотите способ улучшения алгоритма, их есть у меня.
Вам необходимо учитывать не только наличие символа со сравниваемой строкой но и позицию символа в строке, т.е чем ближе стоят друг к другу, тем больше добавляем вес данного совпадения, чем они дальше тем меньше. Так-же не помешает сравнивать не только посимвольно но и анализируя совпадение цепочки символов, чем больше цепочка символов с одинаковыми значениями тем коэфицент выше..
А вообще вы взялись за не простую задачу… если бы все было так просто, то я бы уже давно себе свой яндексогугл сделал =)
С уважением Ваш критикан =)
хм… не успел дочитать в (14) все уже описали подробней.
(17) vasiliy_b, такая идея давно в голове была. Тут могут возникнуть проблемы, если не удалить все мешающие символы (пробелы, запятые, точки, скобки, проценты и т.д.), а также если в каком то наименовании при опечатке поставили 2 одинаковых символа вместо одного. И тогда, так называемый весовой коэффициент, только ухудшит положение дел.
Спасибо за дельный совет! 🙂
П.С. Никто и не говорит, что задача простая. Она только кажется таковой. Но и попытки решить задачу не могут быть тщетными, если приложить к этому должные усилия. Собрать по крупицам идеи и синтезировать алгоритм.
В моей практике требовалось найти похожее (получить список похожих) из некоего справочника. Заполнялось некое соответствие 2х справочников…
1. Исходный образец разбивался на слова и грузился во временную таблицу.
2. Запросом считалось количество совпадений с весовым коэффициентом 1 (хотя можно использовать длину слова).
3. Максимальное число получалось при совпадении целой фразы Наименования.
4. На выходе найденные элементы сортировались по убыванию веса.
Если первый элемент из найденного списка имел значительно больший вес перед вторым, то подставлялось совпадение. Иначе список использовался для ручного выбора из списка. Именно этот алгоритм можно дополнить совпадением символов.
Но основная задача не просто сравнить, а найти безошибочно точное соответствие эталона в неком списке.
При посимвольном сравнении практически невозможно выбрать правильный вариант: Ищем «Пентиум II» среди «Пентиум II», «Пентиум III» и «Пентиум-4». Разность весового показателя будет слишком мала для принятия решения.
Использование ВК замедляет запуск поиска (требуется предварительная подготовка и передача списка в котором будет поиск), но сам поиск на несколько порядков быстрее (следствие откомпилированного процессорного кода ВК).
Лет пять назад была такая же проблема в результате ВК по быстродействию лучше всего.
Забыл автора теории подобного поиска, но суть сравнения состоит в том что:кроме «Попарно вычисляем число вхождений в обоих наименованиях каждого символа из эталонной строки» надо еще сравнивать сочетание 2-х символов в каждой строке с последующим смещением на 1 символ, для улучшения та же операция но уже по 3 символа, правда тормозит страшно.
Этот алг. реализован в ВК от сюда
Посмотрите также сюда
Сделано на strmatch
Сама вк и ее исходники выложены на портале
Ищет весьма качественно особенно в длинных наименованиях в тч учитывает фонетические совпадения
Заявляю ответственно ибо на этой вк держится куча сравнилок и грузилок прайсов
На ее основе автоматизировано несколько контор
От фармации с мегапрайсами в пятнадцать тысяч наименований
От сетки ларьков по продаже дисков и чехлов
Магазин детских игрушек
Контора по торговле бытовой техникой
Это то что помню навскидку
Если к результатам работы данной вк подключить чуток эмпирики в соотвествии со специализацией наименований то результат считаю превосходен
Также был заказ по радиодеталям
А там осложнено это тем что наименования у них короткие и буквенноцифровые и все похоже на все
Добавление эмпирики позволило получить очень неплохие результаты
(21) CheBurator, исходники ВК разве выложены? если не затруднит, то покажите где
Погляжу как основу как алгоритм нечеткого поиска.
(24) kostyaomsk, если не затруднит, когда будет готов ваш алгоритм, выложите его здесь в комментариях. У нас тут активное обсуждение и мозговой штурм 🙂
добавлю свои пять копеек.все зависит от постановки задачи. если задача найти схожие по звучанию, написанию это одно, про это писали выше. есть куча алгоритмов. по написанию есть метод n-грамм. есть куча других алгоритмов. и вообще можно взять sphinx и посмотреть его (я его кстати пробовал в 1С использовать, там есть квази-MySQL база, через которую можно запросы на неком подмножестве диалекта посылать, но отказался поскольку там есть требование иметь ключ как id — int или int64 ,что довольно затратно к каждой таблице делать еще таблицы из id в guid. хотя sphinx хорош скоростью обновления индексов). но если задача стоит сложного сравнения/поиска фраз , которые ничего общего по звучанию могут не иметь , например — «клейкая лента» и «скотч», то тут имхо нужно создавать поиск по онтологиям, создавать словарные базы, базы сокращений, базы семантик, парсить каждую фразу в дерево, а потом сравнивать деревья по весам ветвей. я не стал настолько углубляться в эту тему. не было смысла. видел только какие-то иностранные коммерческие системы в гугле, которые продаются за кучу денег, как они работают, не знаю)
Стрматч также хорош тем что там можно задавать веса цифр что повышает процент похожести
Это хорошо канает на всяких емкостях и литражах где надо чтобы равно было 200 мл и 0.2 л
Мало ли кому пригодится, по этому выложу свой код:
Показать
Входные параметры:
НаимСравн — строка, с которой надо сравнить
МассивСлов — эталонная строка, заранее разбитая на составляющие
ОбщДлинаСлов — общая длинна слов в МассивСлов для вычисления коэф. схожести
Суть данного метода — устранить недостатки метода из топика.
Описание колонок на скрине:
Процент1 — сравнение методом из топика
Процент2 — сравнение моим методом по вхождению слов (не короче 4х символов)
Процент3 — усредненный коэф (Процент1 + Процент2 х 2) / 3
(28) DrBlack, спасибо за ваш комментарий.
(29) да незашто 🙂
Тестировал дальше, в общем похоже победа полная, результат интересный, файл прикрепил
И обновите статью, а то те кто будут искать, могут не дочитать до конца, а проблема-то решена… 😉
Уж простите за поднятие старой темы, но другого алгоритма анализа схожести не нашел.
Не понял необходимость параметра ОбщДлинаСлов, какое число туда нужно помещать? Почему этот параметр нельзя вычислить перед перебором слов из массива? Или это средняя длина слов в массиве?
(31) Ну это суммарная длина строки по всем словам из массива. Можно это значение рассчитать внутри метода, чтобы избавить от параметра.
[Обновление, 15.10.19] Добавлена обработка для 1С7.7, реализующая задачу при помощи алгоритмов из публикации.
(32) Любые операции со строками затратны по времени, по этому лучше рассчитать заранее и передавать параметром