

1. Постановка задачи
Пусть имеется две таблицы значений, имеющих одинаковый состав и типы колонок. Требуется сравнить эти таблицы с целью определения различий, имеющихся между ними.
Домысливая условия задачи самыми распространенными обстоятельствами, дополнительно установим, что:
- Разный порядок одних и тех же строк в двух таблицах не делает таблицы различными (в задачах, где порядок строк существенен, всегда можно добавить колонку с номером строки, чтобы заметить их перестановку);
- В одной таблице не может быть двух одинаковых строк (а если такое есть, то всегда можно произвести свертку по всем колонкам с подсчетом одинаковых строк в добавленной колонке – это упростит интерпретацию результатов сравнения).
- Таблицы сравниваются путем непосредственного сравнения значений их элементов или ссылок. Если элементы таблиц содержат коллекции, то сравниваются только ссылки на коллекции без попыток определить равенство их содержания.
Второе уточнение автоматически приводит к тому, что в таблице всегда будут одна или более колонок, значение (комбинация значений) в которых будут уникальными и могут служить идентификатором строки. Такую колонку (набор колонок) можно называть ключом: простым в случае одной колонки или составным в более сложном случае. А еще лучше, по аналогии с регистрами, упомянутые колонки называть измерениями таблицы, а оставшиеся – ресурсами.
Выделение колонок-измерений позволяет при сравнении таблиц установить не только факт удаления или добавления строки, но и факт изменения строки, если в том же наборе измерений изменились ресурсы.
Например, при сравнении таблиц значений, полученных по оборотно-сальдовой ведомости счета учета сырья и материалов, измерениями будут колонки, содержащие номенклатуру и склад, а ресурсами – остатки и обороты счета. А при сравнении табличных частей «Товары» измерениями будут номенклатура, характеристика и серия, а ресурсами – все остальные реквизиты этой табличной части. И тогда путем сравнения версий табличных частей можно будет сказать, что такая-то номенклатура была удалена или добавлена, а такая-то – изменена.
При постановке задачи также определим форму представления результатов сравнения. Это наиболее уязвимое для критики решение. Поскольку от него зависит результат соревнования методов. Одна форма может быть удобной для одного метода, вторая для другого, третья для третьего, а практика в силу разнообразия задач и ситуаций ответу не помогает.
После долгих колебаний было принято следующее решение: результатом сравнения двух таблиц Таблица0 и Таблица1 должна быть таблица «Разница» той же структуры, что и сравниваемые таблицы. «Разница» должна содержать отличающиеся строки двух таблиц (удаленные, добавленные, измененные). При этом в дополнительном столбце «Знак» должна стоять отметка: 0 – если строка имеется в Таблице0 и 1 – если строка имеется в Таблице1. Это можно интерпретировать как 0 – строка удалена, 1 – добавлена, или 0 – строка до изменения, 1 – после. Кроме того (внимание!), строки с одинаковыми значениями измерений должны быть расположены друг под другом, что реализует удобный для визуального контроля способ «связывания» строк до и после изменения.
Например, если сравнить предлагаемым способом таблицу «7 класс» с таблицей «8 класс», то должна получиться таблица «Разница».
| 7 класс | 8 класс | Разница | ||||||
| Предмет | Оценка | Предмет | Оценка | Предмет | Оценка | Знак | ||
| Пение | 5 | Литература | 5 | Пение | 5 | 0 | ||
| Литература | 5 | Алгебра | 4 | Алгебра | 5 | 0 | ||
| Алгебра | 5 | Физика | 5 | Алгебра | 4 | 1 | ||
| Физика | 5 | Химия | 4 | Химия | 4 | 1 |
Ну и последнее. Не так часто, но все же встречаются случаи, когда сравнению подвергаются уже упорядоченные по ключевым полям таблицы. Добавим это условие к задаче, чтобы расширить набор тестируемых алгоритмов методом, который специально заточен под этот случай.
2.Критерии оценки и методика испытаний
Главным критерием оценки естественно выбрать время выполнения сравнения. Дополнительным критерием может служить простота функции сравнения. Время выполнения сравнения можно замерить специально созданной для этого обработкой. Простоту функций предлагается оценивать субъективно.
Обработка, созданная для испытаний, генерирует таблицу значений с заданным числом строк и столбцов и заданным количеством измерений. Тип данных элементов выбирается из ограниченного списка примитивных типов: строка, число и дата, также можно задать длину значения. Значения элементов таблицы формируются случайным образом. Путем изменения первой таблицы формируется вторая. Количество изменений задается в процентном отношении к числу строк первой таблицы тремя различными показателями: процент удалений, изменений и добавлений. Также задается число повторений для определения среднего времени работы метода. Все тестируемые методы запускаются один за другим на одних и тех же тестовых таблицах. Используемая при тестировании обработка прикреплена к данной публикации, чтобы результаты можно было перепроверить на другом оборудовании и в другом программном окружении.
3.Краткое описание сравниваемых методов
Всего для детального тестирования было отобрано семь различных методов:
3.1. Свертка и сортировка
Суть метода заключается в объединении таблиц путем дописывания в цикле по одной строке из первой таблицы ко второй. Затем делается добавление дополнительного столбца «Счёт» для последующего подсчета одинаковых строк. Подсчет делается сверткой по всем столбцам. Так определяются одинаковые и разные строки в первой и второй таблице. Те строки, которые встретились в объединенной таблице по одной, переписываются в таблицу разниц, которая затем сортируется по измерениям, чтобы строки до и после изменений оказались рядом. Вот код данной функции
Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт
ВсеКолонки = "";
Для Каждого Колонка Из Таблица0.Колонки Цикл
ВсеКолонки = ВсеКолонки + ", " + Колонка.Имя
КонецЦикла;
ВсеКолонки = Сред(ВсеКолонки, 2);
Таблица = Таблица1.Скопировать();
Таблица.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число"));
Таблица.ЗаполнитьЗначения(1, "Знак");
Для Каждого Строка Из Таблица0 Цикл ЗаполнитьЗначенияСвойств(Таблица.Добавить(), Строка) КонецЦикла;
Таблица.Колонки.Добавить("Счёт");
Таблица.ЗаполнитьЗначения(1, "Счёт");
Таблица.Свернуть(ВсеКолонки, "Знак, Счёт");
Ответ = Таблица.Скопировать(Новый Структура("Счёт", 1), ВсеКолонки + ", Знак");
Ответ.Сортировать(Измерения);
Возврат Ответ
КонецФункции
3.2 Трюк, свертка и сортировка
Данная функция является небольшой модификацией предыдущей функции за счет того, что дописывание первой таблицы ко второй идет не по строкам, а по столбцам. Это в определенном диапазоне условий ускоряет операцию объединения таблиц
Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт
ВсеКолонки = "";
Для Каждого Колонка Из Таблица0.Колонки Цикл
ВсеКолонки = ВсеКолонки + ", " + Колонка.Имя
КонецЦикла;
ВсеКолонки = Сред(ВсеКолонки, 2);
Таблица = Таблица1.Скопировать();
Таблица.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число"));
Таблица.ЗаполнитьЗначения(1, "Знак");
Для ё = 1 По Таблица0.Количество() Цикл Таблица.Вставить(0) КонецЦикла;
Для ё = 0 По Таблица0.Колонки.Количество() - 1 Цикл Таблица.ЗагрузитьКолонку(Таблица0.ВыгрузитьКолонку(ё), ё) КонецЦикла;
Таблица.Колонки.Добавить("Счёт");
Таблица.ЗаполнитьЗначения(1, "Счёт");
Таблица.Свернуть(ВсеКолонки, "Знак, Счёт");
Ответ = Таблица.Скопировать(Новый Структура("Счёт", 1), ВсеКолонки + ", Знак");
Ответ.Сортировать(Измерения);
Возврат Ответ
КонецФункции
3.3. Соединение по индексу
Данная функция построена на простой и ясной идее. В цикле перебираются строки первой таблицы. Для каждой строки делается попытка найти строку во второй таблице, соответствующую ей по значению измерений, с помощью метода «НайтиСтроки». Ресурсы найденных строк затем сравниваются на предмет наличия расхождений, найденная строка во второй таблице помечается нулем, чтобы затем отобрать непомеченные «единичные» строки как отсутствующие в первой таблице. Чтобы метод НайтиСтроки работал быстро, для второй таблицы создается один индекс по всей совокупности измерений.
Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт
Отбор = Новый Структура(Измерения);
Ресурсы = Новый Массив;
Для ИндексКолонки = 0 По Таблица0.Колонки.Количество() - 1 Цикл
Если НЕ Отбор.Свойство(Таблица0.Колонки[ИндексКолонки].Имя) Тогда
Ресурсы.Добавить(ИндексКолонки)
КонецЕсли
КонецЦикла;
Таблица1.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число"));
Таблица1.ЗаполнитьЗначения(1, "Знак");
НовыйИндекс = Таблица1.Индексы.Добавить(Измерения);
Разница = Таблица1.СкопироватьКолонки();
Для Каждого Строка0 Из Таблица0 Цикл
ЗаполнитьЗначенияСвойств(Отбор, Строка0);
Строки1 = Таблица1.НайтиСтроки(Отбор);
Если Строки1.Количество() = 0 Тогда
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка0)
Иначе
Строка1 = Строки1[0];
Для Каждого Ресурс Из Ресурсы Цикл
Если Строка0[Ресурс] <> Строка1[Ресурс] Тогда
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка0);
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1);
Прервать
КонецЕсли
КонецЦикла;
Строка1.Знак = 0
КонецЕсли
КонецЦикла;
Для Каждого Строка1 Из Таблица1.НайтиСтроки(Новый Структура("Знак", 1)) Цикл
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1);
КонецЦикла;
Таблица1.Колонки.Удалить("Знак");
Таблица1.Индексы.Удалить(НовыйИндекс);
Возврат Разница
КонецФункции
3.4. Соединение по соответствию
Данная функция алгоритмически повторяет предыдущую, за исключением того, что вместо обычного индекса используется «самодельный» индекс на основе соответствия. Для этого вторая таблица предварительно обходится, в результате чего ссылки на ее строки запоминаются в дереве поиска, построенном на основе соответствия
Функция РазницаТаблицЗначений_(Таблица0, Таблица1, СтрокаИзмерений) Экспорт
Таблица1.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число"));
Таблица1.ЗаполнитьЗначения(1, "Знак");
СтруктураИзмерений = Новый Структура(СтрокаИзмерений);
Измерения = Новый Массив;
Ресурсы = Новый Массив;
Для Индекс = 0 По Таблица0.Колонки.Количество() - 1 Цикл
ИмяКолонки = Таблица0.Колонки[Индекс].Имя;
Если СтруктураИзмерений.Свойство(ИмяКолонки) Тогда
Измерения.Добавить(Индекс)
Иначе
Ресурсы.Добавить(Индекс)
КонецЕсли
КонецЦикла;
ИзмерениеПлюс = Измерения[Измерения.Количество() - 1];
Измерения.Удалить(Измерения.Количество() - 1);
ХэшМап = Новый Соответствие;
Для Каждого Строка1 Из Таблица1 Цикл
Корень = ХэшМап;
Для Каждого Измерение Из Измерения Цикл
ЧастьКлюча = Строка1[Измерение];
Ветка = Корень[ЧастьКлюча];
Если Ветка = Неопределено Тогда
Ветка = Новый Соответствие;
Корень[ЧастьКлюча] = Ветка
КонецЕсли;
Корень = Ветка
КонецЦикла;
ЧастьКлюча = Строка1[ИзмерениеПлюс];
Корень[ЧастьКлюча] = Строка1
КонецЦикла;
Измерения.Добавить(ИзмерениеПлюс);
Разница = Таблица1.СкопироватьКолонки();
Для Каждого Строка0 Из Таблица0 Цикл
Корень = ХэшМап;
Для Каждого Измерение Из Измерения Цикл
ЧастьКлюча = Строка0[Измерение];
Ветка = Корень[ЧастьКлюча];
Если Ветка = Неопределено Тогда
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка0);
Прервать
КонецЕсли;
Корень = Ветка
КонецЦикла;
Если Ветка <> Неопределено Тогда
Для Каждого Ресурс Из Ресурсы Цикл
Если Строка0[Ресурс] <> Ветка[Ресурс] Тогда
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка0);
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Ветка);
Прервать
КонецЕсли
КонецЦикла;
Ветка.Знак = 0
КонецЕсли
КонецЦикла;
Для Каждого Строка1 Из Таблица1.НайтиСтроки(Новый Структура("Знак", 1)) Цикл
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1);
КонецЦикла;
Таблица1.Колонки.Удалить("Знак");
Возврат Разница
КонецФункции
3.5. Слияние
Эта функция предполагает отсортированность сравниваемых таблиц по ключевым измерениям. В ходе ее работы строки двух таблиц читаются по очереди, сравниваясь между собой так, чтобы в итоге на выходе получалась слитая упорядоченная таблица без одинаковых строк.
Функция РазницаТаблицЗначений_(Таблица0, Таблица1, СтрокаИзмерений) Экспорт
Таблица1.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число"));
Таблица1.ЗаполнитьЗначения(1, "Знак");
Разница = Таблица1.СкопироватьКолонки();
СтруктураИзмерений = Новый Структура(СтрокаИзмерений);
Измерения = Новый Массив;
Ресурсы = Новый Массив;
Для Индекс = 0 По Таблица0.Колонки.Количество() - 1 Цикл
ИмяКолонки = Таблица0.Колонки[Индекс].Имя;
Если СтруктураИзмерений.Свойство(ИмяКолонки) Тогда
Измерения.Добавить(Индекс)
Иначе
Ресурсы.Добавить(Индекс)
КонецЕсли
КонецЦикла;
Сравнение = Новый СравнениеЗначений;
Индекс1 = Таблица0.Количество() - 1; Индекс2 = Таблица1.Количество() - 1;
Строка1 = Таблица0[Индекс1]; Строка2 = Таблица1[Индекс2];
Пока Истина Цикл
Для Каждого Измерение Из Измерения Цикл
РезультатСравнения = Сравнение.Сравнить(Строка1[Измерение], Строка2[Измерение]);
Если РезультатСравнения <> 0 Тогда
Прервать
КонецЕсли
КонецЦикла;
Если РезультатСравнения = 0 Тогда
Для Каждого Ресурс Из Ресурсы Цикл
Если Строка1[Ресурс] <> Строка2[Ресурс] Тогда
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1);
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка2);
Прервать
КонецЕсли
КонецЦикла;
Индекс1 = Индекс1 - 1;
Индекс2 = Индекс2 - 1;
Если Мин(Индекс1, Индекс2) < 0 Тогда
Прервать
КонецЕсли;
Строка1 = Таблица0[Индекс1];
Строка2 = Таблица1[Индекс2];
ИначеЕсли РезультатСравнения > 0 Тогда
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1);
Индекс1 = Индекс1 - 1;
Если Индекс1 < 0 Тогда
Прервать
КонецЕсли;
Строка1 = Таблица0[Индекс1]
Иначе
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка2);
Индекс2 = Индекс2 - 1;
Если Индекс2 < 0 Тогда
Прервать
КонецЕсли;
Строка2 = Таблица1[Индекс2]
КонецЕсли
КонецЦикла;
Пока Индекс1 >= 0 Цикл
Строка1 = Таблица0[Индекс1];
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1);
Индекс1 = Индекс1 - 1
КонецЦикла;
Пока Индекс2 >= 0 Цикл
Строка2 = Таблица1[Индекс2];
ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка2);
Индекс2 = Индекс2 - 1
КонецЦикла;
Таблица1.Колонки.Удалить("Знак");
Возврат Разница
КонецФункции
3.6. Запрос — полное соединение
Функция основана на передаче в запрос двух таблиц, где они соединяются по равенству значений в измерениях. Небольшое усложнение связано с последующей «разверткой» в две строки строк, отличающихся по ресурсам.
Функция СтрЧасти(Строка, Разделитель) Экспорт
ПозицияРазделителя = Найти(Строка, Разделитель);
Если ПозицияРазделителя = 0 Тогда
Ответ = Новый Массив;
Ответ.Добавить(Строка);
Иначе
Ответ = СтрЧасти(Сред(Строка, ПозицияРазделителя + СтрДлина(Разделитель)), Разделитель);
Ответ.Вставить(0, Сред(Строка, 1, ПозицияРазделителя - 1))
КонецЕсли;
Возврат Ответ
КонецФункции
Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт
Запрос = Новый Запрос(
"ВЫБРАТЬ
| 0 КАК Знак{}, Т.Поле{}
|ПОМЕСТИТЬ Т0
|ИЗ
| &Таблица0 КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| 1 КАК Знак{}, Т.Поле{}
|ПОМЕСТИТЬ Т1
|ИЗ
| &Таблица1 КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| 0 КАК Знак
|ПОМЕСТИТЬ Знаки
|
|ОБЪЕДИНИТЬ
|
|ВЫБРАТЬ
| 1
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ{}
| ВЫБОР Знаки.Знак
| КОГДА 0
| ТОГДА Т0.Поле
| ИНАЧЕ Т1.Поле
| КОНЕЦ КАК Поле,{}
| Знаки.Знак
|ИЗ
| Т0 КАК Т0
| ПОЛНОЕ СОЕДИНЕНИЕ Т1 КАК Т1
| ПО (ИСТИНА)
| {} И Т0.Поле = Т1.Поле{},
| Знаки КАК Знаки
|ГДЕ
| ({}Т0.Поле ЕСТЬ NULL И Знаки.Знак = 1
| ИЛИ Т1.Поле ЕСТЬ NULL И Знаки.Знак = 0
| {} ИЛИ Т0.Поле <> Т1.Поле{})
|
|УПОРЯДОЧИТЬ ПО
| {}Поле"
);
СтруктураИзмерений = Новый Структура(Измерения);
Секции = СтрЧасти(Запрос.Текст, "{}");
Запрос.Текст = Секции[0];
Для Каждого Колонка Из Таблица1.Колонки Цикл
Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции[1], "Поле", Колонка.Имя)
КонецЦикла;
Запрос.Текст = Запрос.Текст + Секции[2];
Для Каждого Колонка Из Таблица1.Колонки Цикл
Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции[3], "Поле", Колонка.Имя)
КонецЦикла;
Запрос.Текст = Запрос.Текст + Секции[4];
Для Каждого Колонка Из Таблица1.Колонки Цикл
Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции[5], "Поле", Колонка.Имя)
КонецЦикла;
Запрос.Текст = Запрос.Текст + Секции[6];
Для Каждого Элемент Из СтруктураИзмерений Цикл
Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции[7], "Поле", Элемент.Ключ)
КонецЦикла;
Запрос.Текст = Запрос.Текст + Секции[8];
Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции[9], "Поле", Таблица1.Колонки[0].Имя);
Для Каждого Колонка Из Таблица1.Колонки Цикл
Если НЕ СтруктураИзмерений.Свойство(Колонка.Имя) Тогда
Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции[10], "Поле", Колонка.Имя)
КонецЕсли
КонецЦикла;
Запрос.Текст = Запрос.Текст + Секции[11];
Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции[12], "Поле", Измерения);
Запрос.УстановитьПараметр("Таблица0", Таблица0);
Запрос.УстановитьПараметр("Таблица1", Таблица1);
Возврат Запрос.Выполнить().Выгрузить()
КонецФункции
3.7. Запрос — группировка
Эта функция построена ровно на той же идее, что и функция 3.1, только реализована внутри запроса
Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт
Запрос = Новый Запрос(
"ВЫБРАТЬ
| 0 КАК Знак,
| Т.Поле
|ПОМЕСТИТЬ Т0
|ИЗ
| &Таблица0 КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| 1 КАК Знак,
| Т.Поле
|ПОМЕСТИТЬ Т1
|ИЗ
| &Таблица1 КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| Т.Знак,
| Т.Поле
|ПОМЕСТИТЬ Т
|ИЗ
| Т0 КАК Т
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| Т.Знак,
| Т.Поле
|ИЗ
| Т1 КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| СУММА(Т.Знак) КАК Знак,
| Т.Поле
|ИЗ
| Т КАК Т
|
|СГРУППИРОВАТЬ ПО
| Т.Поле
|
|ИМЕЮЩИЕ
| КОЛИЧЕСТВО(*) = 1
|
|УПОРЯДОЧИТЬ ПО
| Поле//"
);
ВсеКолонки = "";
Для Каждого Колонка Из Таблица1.Колонки Цикл
ВсеКолонки = ВсеКолонки + ", Т." + Колонка.Имя
КонецЦикла;
Запрос.Текст = СтрЗаменить(Запрос.Текст, "Т.Поле", Сред(ВсеКолонки, 2));
Запрос.Текст = СтрЗаменить(Запрос.Текст, "Поле//", Измерения);
Запрос.УстановитьПараметр("Таблица0", Таблица0);
Запрос.УстановитьПараметр("Таблица1", Таблица1);
Возврат Запрос.Выполнить().Выгрузить()
КонецФункции
Все приведенные здесь функции были достаточно тщательно оттюнингованы для достижения максимального быстродействия. С учетом опыта, полученного в ходе совместного тюнинга на форуме функций для одномерного случая. Однако это было сделано не так тщательно как там, поэтому, возможно, из некоторых функций можно выжать еще немного быстродействия.
4. Результаты тестирования
4.1 Влияние числа строк
Исследуем зависимость времени сравнения от числа строк в таблицах. Для этого используем следующие значения параметров тестирования. Число строк — 20000, 40000, 60000, 80000, 100000, число колонок — 10, число ключевых колонок — 1, тип данных — строка, длина строки — 10, процент удалений, изменений, добавлений — 5, число повторов теста — 2. Получим следующую зависимость, которую удобнее представить в виде графика.

Эта зависимость для большинства методов практически линейна! Так и должно быть. Время работы метода НайтиСтроки при наличии индекса не зависит от числа строк, поэтому соединение по индексу выполняется за линейное время. То же самое при использовании соответствия и слияния. При полном соединении в запросе для соединения таблиц равного размера скорее всего используется хэш-матч.
Нелинейность времени сортировки относительно небольшого количества отличающихся строк чуть-чуть отклоняет от прямой зависимость для свертки. Хуже дела у метода с использованием объединения копированием колонок — именно этот способ копирования вносит существенную нелинейность вдобавок к небольшой нелинейности сортировки. Из-за этого выгода применения «трюка» объединения таблиц на числе строк более 60000 теряется.
4.2 Влияние длины значений
Теперь исследуем зависимость времени от длины значений типа строка. Число строк положим равным 50000. Остальные параметры такие же, как в 4.1. Результат представим в виде столбиковой диаграммы. Она лучше показывает соотношение времени работы разных методов и позволяет выделить лидера, которым в большинстве случаев яыляется метод свертки.

Видно, что зависимость времени от метода при изменении длины строки практически не меняется. Растет только время выполнения запросов.
Чтобы повысить информативность этой диаграммы в отношении запросных методов, здесь выделено в отдельные измерения время ввода таблиц в запрос. Для этого создана функция-пустышка, выполняющая только ввод таблиц в запрос и не выполняющая больше никакой другой работы. Большое время на ввод таблиц показывает, что запросной технике очень трудно конкурировать с методами-лидерами. Во многих случаях лидеры уже закончили работу к тому времени, когда исходные данные только оказались в запросе.
4.3 Влияние типов данных
Следующий интересный вопрос — отношение методов к типам данных. Его показывает следующая диаграмма. Здесь также число строк 50000, длина строкового и числового значения — 10. Остальное как в 4.1.

Из нее видно, что типданных сильнее всего сказывается на времени запросных методов. Для чисел лучше подходит группировка. И очень хорошо запросами обрабатываются даты.
4.3 Влияние числа колонок
Еще одна зависимость — это зависимость времени сравнения от числа колонок. Ее показывает следующая диаграмма. Число строк здесь 50000, тип данных — строка длины 10, процент добавлений, искажений и удалений по 5. Одна ключевая колонка.

Видно, что число колонок не сильно меняет сравнительную скорость методов. В наибольшей степени увеличение числа колонок замедляет работу запросов.
4.4 Влияние числа измерений
Более интересна зависимость от числа ключевых колонок, приведенная ниже. Число строк здесь 50000, тип данных — строка длины 10, процент добавлений, искажений и удалений по 5. Всего колонок 10.

Видно, что метод на основе соответствия, ранее показывавший неплохие результаты, теперь оказывается в аутсайдерах. Также ухудшается слияние. А вот поиск по индексу улучшается — за счет того, что сравнивать остается меньшее число колонок.
4.5 Влияние разницы размеров таблиц
Теперь обратим внимание на несимметричность методов 1 — 4 (свертки и соединения) относительно размеров сравниваемых таблиц. Всем этим методам выгоднее, чтобы первая таблица была меньше! Это подтверждает следующая таблица, которая показывает время сравнения двух таблиц 50000 и 40000 строк в разном порядке.

На приведенной диаграмме заметен любопытный артефакт. При данном количестве строк и столбцов оказывается выгоднее добавлять в цикле 50 тысяч строк к таблице из 40 тысяч строк, чем наоборот. Возможно, это связано с особенносями выделения памяти для таблицы значений.
4.6 Влияние количества отличий
Ну и, наконец, исследуем зависимость времени сравнения от степени отличия таблиц. Видно, что при увеличении процента расхождений время работы свертки замедляетс. Так как начинает играть роль нелинейность сортировки.
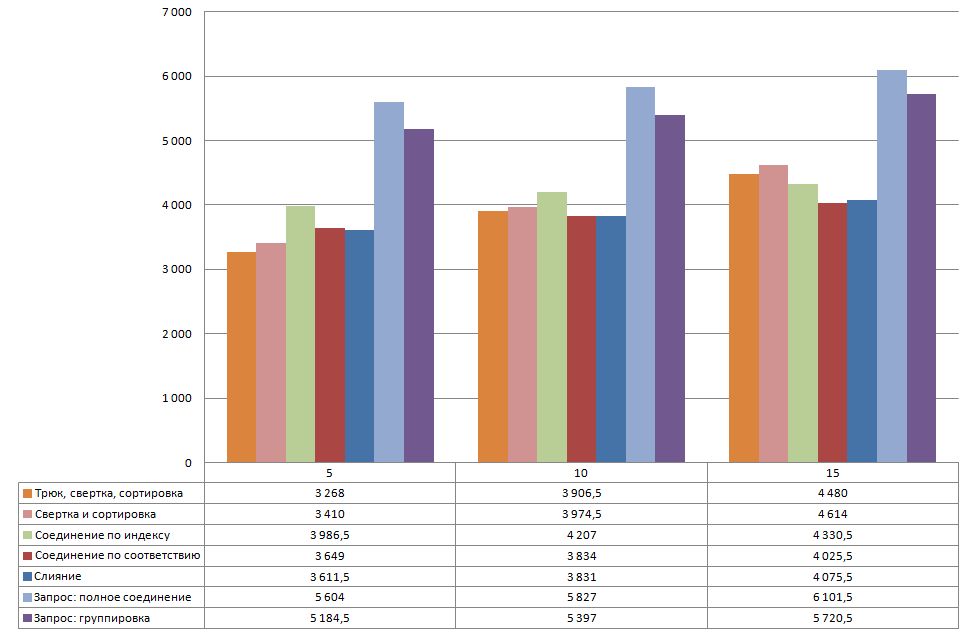
4.7 Влияние оборудования и программного окружения
Тесты выполнялись на платформе 8.3.5.1248 на ноутбуке VGN-Z51MRG. Полученные зависимости в целом подтверждаются на другом оборудовании, но есть и некоторые особенности, обобщить которые пока не удалось.
5. Выводы
5.1. Самый простой метод свертки оказывается в большинстве случаев и наиболее производительным. Его и нужно использовать как универсальный метод, но не в специальных случаях.
5.2 При малом размере (до 50000 строк) можно получить дополнительное ускорение свертки, применив копирование столбцов при объединении таблиц (метод 3.2).
5.3 В специальном случае одной ключевой колонки, значительного количества различий и существенной разницы размеров таблиц следует использовать соединение по соответствию. Так же следует поступать, даже если ключевых таблиц несколько, но сравнение производится с одной и той же таблицей, для которой можно заранее подготовить «дерево решений» на основе соответствия, настроенное на ее особенности.
5.4 В специальном случае нескольких ключевых колонок при значительном количестве различий и не отсортированности сравниваемых таблиц нужно использовать метод соединения по индексу.
5.5 Для наибольшей эффективности методов 1-4 нужно выбирать правильный порядок указания таблиц при сравнении.
5.6 В специальном случае отсортированности сравниваемых таблиц при значительном количестве различий следует использовать слияние.
5.7. В специальном случае больших (зависит от оборудования) и примерно равных по размеру таблиц, которые, к тому же, имеют значительные отличия и состоят из коротких строк и предельно малого числа колонок, возможно использовать запросы.
5.8 Если в таблицах преобладают числовые данные, даты, средние и длинные строки, то в запросах сравнения таблиц следует использовать группировку, и только для очень коротких строк — полное соединение.
6. Общие выводы
6.1 В любом случае перед решающим выбором лучше по-возможности сравнивать несколько методов в реальных условиях их применения. Например, при помощи приложенной к статье обработки.
6.2 Учет особенностей данных в таблицах позволяет произвести целенаправленную дополнительную оптимизацию большинства приведенных методов. Для этого остается немало возможностей, оставшихся за пределами рассмотренного круга вопросов.
6.3 Ввод таблиц значений в запросы может занимать значительное время, что в большинстве случаев сводит на нет эффективность их применения в задачах, когда данные берутся из памяти, а не из базы. Бездумное использование запросов в этой задаче — вредное заблуждение.
6.4 Время работы метода НайтиСтроки при наличии индекса по колонкам, входящим в отбор, не зависит от размера таблицы значений. Таким образом правильной оценкой быстродействия метода сравнения таблиц с использованием соединения по индексу является O(N).
6.5 Время работы методов часто зависит от малозначительных (на первый взгляд) деталей записи программных конструкций. Поэтому для достижения предельной производительности этим деталям микрооптимизации следует уделять максимум внимания.
P.S.: Нужно также отметить большой вклад в данную работу всех участников обсуждения Как оптимально сравнить две таблицы значений? Среди них YanTsys, caponid, mymyka, но особенно awk и serginio, которые предложили, реализовали и отладили свои методы для одномерного случая, вносили множество полезных поправок и соображений, а также активно участвовали во всех обсуждениях. Отдельное спасибо спонсорам той самой ветки и Nadushka74 — за интересный вопрос.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
сделайте бесплатное скачивание.
(1) МихаилМ,
Это уже не возможно по новым правилам. Бесплатное скачивание действительно только для старых обработок.
Если только Сергей выложит обработку здесь, в комментариях — тогда будет бесплатно для скачивания.
(1) МихаилМ, всем, кто заинтересован в развитии темы, пришлю обработку по почте. Пишите адрес в личном сообщении.
у меня при настройках , как на прикрепленной картинке произошла ошибка. версия 1с 8.3.5.1248 файловая
Кстати если в соответствии, слиянии и по индексу используется сравнение ресурсов одинаковых строк, то вот для сверток и запроса этот алгоритм отсутствует. А время то оно требует немалого.
На самом деле все зависит от задачи. Например часто приходится сравнивать базы по наименованиям для синхронизации. Выводить одинаковые, а вот различные могут в большинстве случаев находиться рядом и можно уже сравнивать неодинаковые. При этом наименования могут дублироваться.
Сергей, а не пробовали в методах с запросами предварительно сортировать таблицы? Перед их помещением в запрос?
К сожалению, язык запросов 1С не позволяет серверу СУБД дать указания напрямую, какой метод соединения использовать, но, возможно, передав сортированные таблицы, оптимизатор запросов сам использует merge join вместо nested loops?
Ну и в методах с запросами, имхо, тоже не все так однозначно. Потому как быстродействие очень сильно зависит от того, какая база — файловая или серверная, если серверная — то какое там железо, где tempdb лежит — на обычном харде или на ssd. Львиную долю занимает не выполнение запроса, а передача таблиц с клиента на сервер, их сериализация
(4) МихаилМ, я промежуточный вариант случайно дал (в статье нормальный). Сейчас уже поправил — еще раз нужно взять из (3).
(6) Dach, таблицы во всех приведенных замерах отсортированы. Проблема НЕ в способе соединения таблиц в запросе. В приведенных случаях там точно не nested loops, иначе не линейная зависимость бы была. Там, скорее всего, hash-match. Проблема в передаче таблиц в запрос.
(7) Dach, Как показывает простое тестирование — загрузка данных во временную таблицу — без разницы файловый или серверный вариант работы примерно на порядок затратнее по времени. Т.е в коде сравнение уже выполнилось, а запросом даже еще данные не загрузились.
Все это зависит только от того, где получаются данные для сравнения — на каком уровне получили данные (база данных, сервер 1с, клиент), то там и сравниваем — накладные расходы на перевод уровня очень велики.
(11) BigClock, код я посмотрел. С точки зрения методов, приведенных в статье, это соединение по индексу. Грубых ошибок в коде нет. Индексы созданы, значит, больших потерь в производительности тоже не будет. Все добротно, но:
1) Зачем-то дважды формируется строка имен колонок — когда несколькими строками выше проверили колонки (список) на совпадение. Возможно, здесь расчет на то, что задание элементов в структуре поиска должно происходить в том-же порядке, что и в индексе. И если порядок колонок в двух таблицах разный, то и индексы должны соответствовать этому порядку. Я этого не замечал, впрочем, стоит проверить.
2) Симметричность — это красиво, но … если создавать индекс и производить поиск только в одной (большей) таблице, «вычеркивая» из второй таблицы найденные строки, то быстродействие можно повысить раза в 1,5 — 2. Тем более, что выводить разницу не нужно.
Как-то так.
Всегда большое удовольствие читать статьи ildarovich , спасибо, это интересно. С другой стороны финальный вердикт несколько огорчил — получается что-то сильно оптимизировать алгоритмически почти невозможно, результат практически равен.
Я тут недавно решил стать хорошим программистом хД и начал изучать «алгоритмы и структуры данных», в следствии этого решил выполнить то, что делают многие — написал несколько видов сортировок на 1С и сравнивал их по скорости выполнения. Я был сильно удивлен, когда стандартный 1Сный способ через сортировку списка значения выигрывал по времени примерно в 600 раз у bubblesort(до более быстрых сортировок я пока не дошел). Но куда больше меня удивило то, что если bubblesort записать в одну строчку, то проигрывает она уже в 200-300 раз. Одна лишь запись в строчку в 2-3 раза ускорила мою самописную сортировку.
Я это к тому, что довольно сложно что-то оптимизировать алгоритмически когда огромные ресурсы тратятся на совершенно другие вещи, ну как мне показалось. Или может я просто туплю 🙂
(13) slazzy, Отладку отключи — м уже выяснили почему в одну строку быстрее…
Тут эту тему на форумах очень сильно обсуждали про сравнение таблиц значения.
(14) awk, да я примерно представляю почему оно так и читал обсуждения эти, я просто не думал, что будет настолько большая разница. И тут я нашел несколько человек, которые сравнивали сортировки аналогично и они все многократно проигрывали обычной 1Сной, а сами методы по своей результативности различались не очень сильно, хотя на практике должны бы. Но это конечно оффтоп в данной теме) само по себе сравнение таблиц очень интересно
(13) slazzy,
Увы, инстрУмент такой — оптимизируй не оптимизируй, а все равно в платформу упрешься.
(14) awk,
Я пропустил — где это выяснЯли и вЫяснили?
почему в списке методов нет анализа данных поиск ассоциаций? Если скд в чистом виде будет проигрывать в большинстве случаев из-за медленного вывода в тз., то анализ данных должен быть сопоставим по скорости с другими методами. правда может проигрывать по объему используемой памяти.
(19) МихаилМ, очень интересный вопрос. В ходе исходного обсуждения я эту возможность озвучивал (без конкретики), но никто эту тему не поддержал и своего решения не предложил. Я, в общем-то, не собирался ничего своего разрабатывать, а хотел собрать существующие решения методом краудсорсинга. И ждал такого рода находок.
Из анализа данных я только попробовал дерево решений для поиска в Таблице1 использовать, но с налету не получилось.
Если вы такое решение реализуете (через поиск ассоциаций) — будет очень здорово. Анализ данных — мощный инструмент и его нужно всячески популяризировать. Понятно, что в составе платформы он появился не просто так, а как дань научному прошлому Нуралиева — старшего. Но и хорошо, зато он у нас есть.
(18) AlexO, обсуждения
(21) awk, увы, в тексте темы нет намека на сравнение в одну и не в одну строку написания кода.
Вы имеете ввиду — первоначальное длительное обсуждение? Там страниц много, на первых трех нет точно. Если не трудно — укажите место, где именно этот вопрос разобрали.
Спасибо, полезная информация. Систематизирована и от автора, которому можно доверять.
(24) Сергей, непонятно — вы не знали про массив, и все всегда делали в ТЗ? Или тема плавно перешла в «в каком объекте 1С наиболее быстрый поиск, чтение и запись»?
Т.е. начали про реализации сравнений ТЗ, и пришли к выводу, что ну их, ТЗ, аутентичный массив все-таки быстрее ))
Притом, что с массивом строк ТЗ весьма неудобно работать на практике ТЧ документов и справочников. Слишком много условий сразу надо накладывать на использование.
(25) AlexO, стоп, стоп — вы меня не поняли, обсуждаются более тонкие материи — один из этапов сравнения.
Речь идет о сравнении ТЗ и только о нем. Никаких массивов
В статье рассмотрено семь методов и говорится, что, покопавшись, можно выжать еще немного производительности из каждого метода, не меняя его сути.
Я считал, что тем, кто любит выжимать из кода все до последнего, будет интересны и доли процентов тоже. В (24) говорится как этого можно добиться для метода 3.2 с помощью хитрого и не очевидного приема, на идею которого меня навело одно из сообщения МихаилаМ.
Итак, в чем этот прием, если неохота разбирать код.
Первое: сравнение ТЗ «сверткой» выполняется путем последовательности четырех действий: объединением ТЗ, группировкой, отбором одиночных строк и их сортировкой.
Речь идет об ускорении первого этапа: объединении ТЗ. Используется хитрый прием. Его суть вот в чем (посмотрите внимательно код в (24)).
Сначала находится массив из N строк (ссылок) второй таблицы. Затем этот массив перестраивается. К его концу приписывается M пустых ссылок. Затем элементы массива сдвигаются к его концу, а затем в его начало дописывается ссылка на ОДНУ И ТУ ЖЕ НОВУЮ СТРОКУ.
Если теперь при копировании таблицы значений указать такой искаженный массив строк как параметр, то в начале таблицы-копии окажется M вставленных строк. Без долгой операции Вставить(0), время которой линейно зависит от размера таблицы.
Открытие в том, что в массиве строк (ссылок) строки можно дублировать, за счет чего после копирования очень быстро продублируются и само содержание строк.
(26) Т.е., если нашли более быстрый способ образования таблиц-партнеров, тогда этот этап нужно повторить во всех сортировках, чтобы не было перекоса. И сравнить результаты снова между собой.
Мне кажется, МихаилМ писал об этом.
(27) AlexO, пока хочу выдержать паузу, накопить побольше замечаний и предложений. К тому же разница (улучшение) — это несколько процентов (5-10). Общей картины она не меняет — улучшает и так лучший результат. Также желательно выяснить у разработчиков, считают ли они этот прием (дублирования ссылок на строки перед Скопировать) корректным. Хотя тут вроде бы поведение платформы соответствует ожидаемому. Не хотелось бы, чтобы функция перестала работать после обновления платформы.
Ну спасибо! Респект автору. Прямо научно-иследовательская работа: постановка проблемы, литераткрное обозрение, исследования, анализ результатов и, наконец, выводы.
(28)
А почему они могут посчитать это «некорректным»? Не припомню, чтобы у разработчиков вообще были какие-либо «методики» и оптимизации в плане работы с существующими в платформе объектами ))
Очень интересная и актуальная для меня тема. Но для меня актуальность смещена несколько в другую сторону. А именно: быстро и просто определить отличаются ли две ТЗ. Какие именно отличия — не особо важно. И ожидаемый сценарий: 95% — одинаковые, 5% — отличаются. Поэтому возможно если понадобиться анализ 5%, то можно будет взять один из вышеизложенных способов. Но каким методом быстренько отсеять одинаковые ТЗ?
Первым пришедшим в голову решением было использование Хешей. Проверив на прилагаемой обработке получил результат примерно в два раза лучше чем у «Трюк, свертка, сортировка». Но все равно мне это не нравится: протого способа получить Хеш ТЗ не придумалось и делаю через ТЗ->ХранилищеЗначения->ЗаписьFastInfoset.
Думается мне должен быть более быстрый способ, чтоб установить, что две ТЗ равны.
(31) friend0, а почему не через ЗначениеВСтрокуВнутр?
(32) что-то даже не подумал, что оно так умеет. Как обычно ищу «более интересные» пути вместо простых. 🙂
Но по факту разница получается небольшая (на 50000): свертка — 1 774,00, Хеш — 655,00, ЗначениеВСтрокуВнутр — 602,80. Хотя ТЗ порядка 500 строк (при множестве повторов) через строку прогоняется ощутимо быстрее.
(33) friend0, свертку можно еще чуть подкрутить, если интересует только равенство. Свертка лучше в том смысле, что не чувствительна к порядку строк в сравниваемых таблицах, когда равенство не зависит от порядка строк. Но вообще, конечно, сравнению «в одну строку кода» трудно что-либо хитроумно-алгоритмическое противопоставить.
Спасибо за работу!
Было бы интересно увидеть сравнительные замеры когда надо просто получить факт равны ли таблицы, без расшифровки расхождений. Хотя лидером скорее всего будет ЗначениеВСтрокуВнутр(Т1) = ЗначениеВСтрокуВнутр(Т2), но надо ж убедиться))
Очень вредное заблуждение, к сожалению многие для «красоты кода» все операции с ТЗ пытаются запихнуть в запросы (последнее время в СКД), не принимая во внимание накладные расходы.
А сравнение Табличных частей, например одного и того же документа, для анализа сделанных изменений — каким способом наиболее оптимально делать? Возможно, что запрос выйдет на 1 место?
(36) AndrewVVS, табличные части обычно не имеют больше 1000 строк. При небольшом количестве строк быстродействие не будет главным критерием выбора. Скорее всего, лучше выбрать более простой, короткий и понятный метод, дающий результат в нужном виде. Это будет может быть либо свертка, либо запрос.
Я бы отсортировал, сохранил как mxl и стандарным сравнением файлов вывел, получится намного нагляднее, хоть и не так быстро.
(39) serg-wws, разница действительно «невелика». Но это в том случае, если каждый из методов тщательно выглажен и вылизан, а объемы данных — ограничены. На практике есть риск взять не лучший метод и реализовать его не лучшим образом. В этом случае разница будет очень даже «велика».
(38) nikita0832, в публикации как раз таки идёт сравнение двух mxl сначала через сравнение двух ТЗ (по одному из методов данной статьи). Стандартному сравнителю 1С уже скармливаются файлы поменьше, т.к. иначе сравнение, например двух 200 МБ файлов можно ждать очень долго… Так что лучший способ это комбинация из сравнения ТЗ и 1С-овского стандартного сравнителя.
Плюс предлагая вместо сравнения ТЗ — сравнение mxl стандартным сравнением вы исходите из задачи «Показать пользователю результат сравнения», но сравнивать две ТЗ нужно не только для того чтобы «показать голый результат»!
Можете попробовать сравнить таблицы автоматически тут
(42)
А вы сами пробовали? Сервис не работает, пишет:
Сравнение excel файлов будет доступно в течение ближайшего времени, если у вас есть желание использовать сервис, то вы можете оставить свои контакты в форме ниже и мы вам сообщим о готовности.
Сегодня утром пробовал и днём.
Если пробовали, то интересна реакция сервиса, если тупо поменять строчки местами — он найдёт? Стандартный сравнитель 1С не умеет такие распознавать.
А уже писали, что «3.4. Соединение по соответствию» не работает?
Пример во вложении:
в верхней таблице — результат сравнения методом 3.4.
ниже соответственно данные таблицы 0, 1 и строка измерений.
Кстати, да.
Наверняка Вы знаете, но напомню: если в соответствие вставлять пару, где ключ Неопределено, то эффект «вау» для новичков гарантирован.
(44) Про то, что в соответствие «по-тихому» не вставляется ключ, равный «Неопределено», написано, например, здесь: . Этот неожиданный эффект не был учтен при написании 3.4. Можно поправить, но особого смысла не вижу. Метод 3.4 вроде бы ни с одной стороны лучшим не оказался — я бы просто не советовал его использовать.
Почему бы не сравнивать хешы, полученные из полей строк?
cтрока ТЗ -> массив -> хранилище значения -> строка64 -> двоичные данные -> хеш
(46) Слишком много преобразований, это будет совсем не «лучший» метод.
Кроме того, когда выполняется свертка по списку полей (речь идет о рассмотренном в публикации методе «свертка и сортировка»), платформа, думаю, как раз и считает тот же самый хэш, который вы предлагаете считать «вручную». Чтобы быстро находить группу, к которой должна отнестись строка.
(47) Да, я уже проверил. Свертка как таковая делает это на более низком уровне, а значит в разы быстрее. Интересно, ТЗ умеет сворачивать по полям неограниченной длинны иди двоичным данным.
Спасибо, помогло.
Как вариант сравнения:
Если необходимо сравнить таблицы значений с числами, то можно следующий алгоритм:
Данный вариант, если нет связи между колонкой сравнения и другими колонками.
(0) мне сложно оценить предложенные вами алгоритмы, но хотелось бы внести свою лепту в данный вопрос.
я реализовал сравнение запросов, по сути это сравнение таблиц значений по одинаковым измерениям (полям связывания) и по заданным полям сравнения:
(50) Будут ошибки (ложноположительные для равно срабатывания), так как одну сумму можно разложить по разному.
Такая проверка даст ровно то, что ее спрашивали: в двух таблицах равно число строк и их итоги.
(52) Какие именно ошибки, если мы сравниваем только 1 колонку двух таблиц без привязки к другим колонкам? «От перемены мест слагаемых сумма не изменяется». В данном случае мы узнаем сумму всех чисел и количество чисел каждой колонки и если (сумма колонки 1=сумме колонки 2) и (количество колонки 1=количеству колонки 2), значит значения в колонках одинаковые (вне зависимости от номера строк, так как для нас это не имеет значения, потому что сравниваются эти колонки, без привязки к другим колонкам)
Данное сравнение мне понадобилось чтобы сравнить в двух таблицах номера телефонов при заполнении справочника. Если номера не изменились — не перезаписывать объект.
Для проверки данного метода приложил файл Excel
(53) А если подумать?
(24) ildarovich, большое спасибо за представленные варианты и такой нешуточный анализ.
Есть возможность доработать вариант с МассивомСтрок?
Она работает корректно только, если Таблица0.Количество() = Таблица1.Количество().
Случаи, когда функция отрабатывает не корректно:
1. Выдает не корректную таблицу Разница, если Таблица0.Количество() < Таблица1.Количество()
2. Выдает ошибку , если Таблица0.Количество() > Таблица1.Количество():
Ошибка при вызове метода контекста (Скопировать)
Таблица = Таблица1.Скопировать(МассивСтрок);
по причине:
Недопустимое значение параметра (параметр номер ‘1’)
(55) Нужно исправить:
СталаГраница = БылаГраница + Таблица0.Количество();
на
СталаГраница = БылаГраница + Таблица0.Количество() — 1;
(56) Подправленная функция:
Показать
(55)