
ЧтениеXML, ДокументDOM, XPath, ФабрикаXDTO, ПакетыXDTO в сравнении.
При обмене данными, как бы он не производился ( через файлы, через HTTP запросы или еще каким либо другим путем ) все равно основным форматом обмена является XML. В 1С существует несколько способов обработки XML документов – какой из них выбрать по критерию логической простоты и быстродействия? Для практической проверки различных методов был создан XML документ вида

Задачей всех проверяемых методов было получение из XML файла массива, состоящего из структур со свойствами Номер, Дата, Поставщик, Состав, причем свойство Состав само является массивом структур со свойствами Номенклатура и Количество.
Первый метод – простое последовательное чтение XML.


Текущее положение в XML документе отслеживается в переменной ТекущийПуть и при поступлении текстового узла на основании этой переменной заполняются (или игнорируются) соответствующие данные 1С. Конечно, не совсем корректно оценивать логическую сложность программы в строках исходного текста, но тем не менее это самый большой объем из всех методов — 64 строки. Что касается быстродействия (оно проверялось на компьютере памятью в 8 Гб и процессором Intel i7 2.2 Ггц, было создано два файла один на 10 тысяч записей объемом 10 мегабайт, другой на 100 тысяч и 100 мегабайт соответственно) , то на файле 10 000 записей полная обработка заняла 30 секунд и на файле в 100 мегабайт линейно увеличилась в 10 раз.
Второй метод – получение из XML файла документа DOM и последовательный перебор всех узлов полученного документа


Логически этот метод весьма незначительно проще прямого ЧтенияXML (57 строк кода против 62), а вот с быстродействие картина интересная: для файла в 10 тысяч записей быстродействие составило 12 секунд (быстрее более чем в два раза) , но для файла со 100 тысячами записей резко поднялась до 1000 секунд (медленнее более чем в три раза).
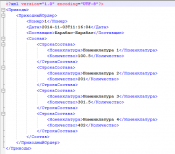
Третий метод подобен второму, но вместо последовательного перебора узлов применен отбор требуемых узлов в DOM документе с помощью выражений XPath .


Этот метод немного проще чем простой перебор узлов в DOM документе, но быстродействие … При 10 000 записей 69 секунд , а для 100 000 обработка длилась более часа, так и не завершилась, после чего была снята принудительно.
Очевидно метод с использованием DOM, в особенности при поиске узлов документа XPath выражениями, надо использовать только для небольших изменений DOM документа со сложной структурой узлов.
Все последующие методы используют для разбора XML документа фабрику XDTO.
Четвертый метод использует метод ПрочитатьXML глобальной ФабрикиXDTO. При этом тип получаемого объекта не указывается, его определяет сам метод фабрики. Тут есть маленькая тонкость – в случае, если тип получаемого объектаXDTO не указан, фабрика не всегда может самостоятельно определить что она получила одиночный объект или список из нескольких одинаковых объектов ( в нашем примере если ПриходныйОрдер в XML документе будет один фабрика посчитает что ПриходыXDTO.ПриходныйОрдер это одиночный объект а не список).


Данный метод не только заметно проще, чем все предыдущие, но и показывает отличное быстродействие на 10 000 записях 4,6 секунды, а при 100 000 обработка длится 46 секунд. Что показывает линейную зависимость от объема обрабатываемого файла.
Пятый метод схож с предыдущим, но глобальной фабрике XDTO подается на вход не только сам XML документ, но и его тип. Этот тип берется из ветки конфигурации XDTO-пакеты. (Если те кто передает вам XML данные хорошие люди, то они должны передать вам и XML схему данных – файл с расширением .xsd из которого вы и создаете в своей конфигурации XDTO-пакет – команда импорт XML схемы …, если нет требуемый пакет обычно не сложно создать вручную, анализируя переданные XML данные).

Один нюанс – частенько XML данные передают без указания URI пространства имен ( атрибут xmlns). Если это так, то необходимо самому добавить недостающий атрибут в XML данные, что и делают первые три оператора процедуры.
Метод замечательный, как по простоте создания, так и по быстродействию – 3,1 секунды на 10 000 записях.
И последний метод. Это скорее некоторая модификация пятого метода, но для условия, что не используется объект конфигурации XDTO-пакет, и фабрика XDTO создается на ходу из текстового описания XML схемы. (Примечание 1-Конечно можно загнать схему в текстовый макет, и оттуда уже использовать, но для учебной программы так нагляднее. 2-Текстовый вариант XML схемы можно например получить создав XDTO-пакет в любой конфигурации XDTO-пакет и выполнив команду Экспорт XML схемы..)


В прилагаемой конфигурации все методы разбора XML представлены в общей команде РазобратьXML, там же в другой общей команде СоздатьXML представлены средства для создания тестовых данных.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Поправь картинку для XPath — слетела
Ну заодно и первую, а то она 8 раз повторилась
Приходится часто обрабатывать файл известной структуры размером от 300 Мб до 1.5 Гб. Для быстрого чтения использую простую схему.
1. Из файла выделяются блоки (у меня называются «offer»), которых может быть до нескольких сотен тысяч. Делается это через чтение текста с разделителем.
2. Каждый блок разбирается с помощью регуляного выражения <ИмяСвойства>(.*?)</ИмяСвойства>
Последний файл размером 460 Мб, обработал за 2 минуты. Но тут надо учитывать, что обработка включала в себя еще чтение/запись в БД.
Памяти такой метод практически не потребляет, правда плохо подходит для файлов со сложной структурой (большим уровнем вложенности)
Не вижу итогов производительности по последнему методу (который с прямым указанием xsd).
А вообще — спасибо. У меня всё руки не доходили померять, в результате исходил из пристрелки «на глазок». Рад, что ваши наблюдения подтвердили мои приблизительные замеры.
Эх, ещё бы посмотреть, что больше съедается, куда кэшируется…
Позволю себе процитировать ИТС. В контексте этой статьи полезно будет.
:
Недопустимо работать с большими XML документами с помощью объектов встроенного языка, предназначенных для обработки файлов целиком: текстовые документы в ТекстовыйДокумент, XML в ДокументDOM и HTML в ДокументHTML, а также создавать в памяти XDTO-пакеты размером с весь XML-файл целиком.
В противном случае, весь файл загружается в оперативную память целиком. Исключения составляют отдельные случаи, когда необходим произвольный доступ к содержимому файла, к какой-то конкретной его части.
Следует использовать объекты для последовательной записи и последовательного чтения: ЧтениеXML, ЧтениеТекста, ЗаписьXML, ЗаписьТекста, с помощью которых можно прочитать файл порциями и расходовать память экономно.
При использовании механизмов XDTO неправильно зачитывать в память весь XML-файл целиком (ФабрикаXTDO.ПрочитатьXML(ЧтениеXML)). Вместо этого следует зачитывать XML-файл последовательно, с помощью объекта ЧтениеXML, а его отдельные фрагменты (теги) десериализовывать с помощью фабрики XDTO.
Подскажите методику, есть HTML страница, есть ли возможность к ней применить вышеизложенные методы, если да, то как?
(6) HTML-страницы нормально можно парсить только через DOM-модель.
Они, как правило, относительно небольшого размера, поэтому быстродействие приемлемое. Я сейчас делаю один проект и в нём как раз есть получение страниц с сайта и их разбор. В цикле дёргаются и разбираются порядка ста страниц.
(7) Поручик, этот механизм понятен, сам им пользуюсь, а если альтернативные варианты, может xpath можно использовать или еще как?
(8) husky, я вот использую в своих парсерах именно XPath.
Положительных голосов на порядок больше чем скачиваний… Странно.
(9) Расскажи про использование XPath для разбора html
(3) salexdv,
Преимущество XML документа, в том что это широко используемый международный стандарт
(11) Поручик,
Почти весь полезный программный код в статье — поэтому скачивание и не сильно требуется
(5) Armando,
Если подавать на вход фабрики XDTO не весь документ, а частями (в тестовом примере каждый ПриходныйОрдер отдельно), то несколько снижается быстродействие — при 100 000 записях с 31 сек до 35. В программировании всегда так — экономим память — ухудшаем быстродействие и наоборот. Экономия памяти не самоцель. Обрабатывать как единое целое или по частям XML документ стоит выбирать для каждого конкретного случая
(12) Я знаю что такое XML, какие у него преимущества/недостатки, и как его можно прочитать. Попробуйте без затрат памяти, и быстро, прочитать файл в 1.5 Гб. Я просто привел способ, которым делаю это я. Согласен у него просто масса недостатков, но в некоторых случаях он очень сильно выручает.
Скачал конфу, в ней нету всех методов, а качал для того что бы посмотреть функцию МассивВСтроку() Не могли бы поделится ?)) А то ЗначениеВСтрокуВнутр даёт немного другой результат
(16) Trotter_NN,
Функция находится в модуле общей команды РазобратьXML
(4) Yashazz,
Быстродействие практически такое же как и при использовании ФабрикиXDTO и ПакетаXDTO
Всегда использую XDTO. Если правильно продумать логику то и кодить не нужно если новый объект добавился.
Для этого я использую ОбщийМакет.
Что хотел сказать XDTO рулит 🙂
Собственно в (5) этому подтверждение 🙂
Статья шикарная. Радует глаз сравнение визуально в коде всех методов. Я много занимаюсь обменами и всегда использую методы последовательного чтения ХМЛ. Попробую применить два последних метода. Автору однозначно плюсую.
(20) logarifm, Попробуйте совместить последовательное чтение + xdto. Будете приятно удивлены 🙂
Спасибо. У самого времени не было потестить все методы.
очень поучительно, плюс однозначно..
когда-нибуть пригодится
>>…то они должны передать вам и XML схему данных – файл с расширением .xsd …
их файла xml можно самому собрать xsd-схему, есть консольная утилита xsd.exe
(25) anton.fly7,
По крайней мере мои попытки использовать эту программу оканчивались неудачей — полученный xsd файл проще было не доделывать до кондиции, а создать свой вручную.
(26) svenderevsky, ну не знаю… возможно… я им постоянно пользуюсь когда переношу что-то через xml файлы. в базе источнике записываю данные в текстовик xml, потом генею xsd, потом в базе приемнике через фабрику читаю xml
(10) ZMGMSC, старт мани есть не у всех, точнее есть у всех, но не все их могут использовать)
Сразу, сходу, не дочитав статью :
В первом методе, ИМХО, быстродействие тормозит вот это : МассивВСтроку(). Проверь без него, т.е. вообще не нужно использовать ТекущийПуть. Он нужен только в том случае, если есть неуникальные имена узлов, а в примере их нет
В примере для метода 4 один абзац написан дважды.
(3) salexdv, Да реальная тема, есть более подробный пример как читаешь оферы?
(31) SeverBaP,
А что такое оферы?
(32) svenderevsky, «</offer>» — из YML понятие товарное предложение (товар).
На данный момент написал такое:
Показать
(33) SeverBaP,
Показать
В принципе то же самое, только позволяет несколько сэкономить память при последовательном чтении XML
(34) svenderevsky, в памяти все нормально но скорость просто жесть.. вот думаю как лучше.
(35) SeverBaP,
Работа с DOM самая тяжелая операция из всех методов разбора XML, явное увеличение быстродействия может дать работа с фабрикой XDTO
(36) svenderevsky, непонятно как допустим используя XDTO вытянуть текст из: <category id=»85115″ parentId=»85354″>Платья и сарафаны</category> — «Платья и сарафаны» ведь в объектеXDTO только свойства.
(37) SeverBaP,
В пакете XDTO создайте тип category и добавте к нему три свойства — id,parentId и text (впрочем третье имя может быть любым), для первых двух свойств установите Форма — атрибут, а для третьего Форма — текст. Тогда фабрика XDTO поймет строку вида <category id=»85115″ parentId=»85354″>Платья и сарафаны</category>
(38) svenderevsky, можно пример? у меня аналогичная ситуация.
(39) kirillkr,
Не совсем, точнее совсем, непонятно пример чего?
(40) svenderevsky,
Как программно!! (без изменения конфигурации) создать или модифицировать пакет xdto, чтобы можно было прочитать и атрибуты и само содержимое тега?
(41) kirillkr,
(41) kirillkr,
В последнем примере статьи фабрика XDTO создается программно из строки. тут и надо указывать требуемые элементы пакета
(41) kirillkr, А что Вам мешает сделать как показано в последнем примере из статьи? То есть «Программно!!» создать пакет.. Позволю себе процитировать автора:»фабрика XDTO создается на ходу из текстового описания XML схемы». Должно решит вашу проблему кмк.
(42) SeverBaP, спасибо, читал, но не помогло.
(43), (44), использовал, но может некорректную схему написал — все равно не видит. Вот мой код,
, а в аттаче пример файла.
В схеме использовал разные варианты, но ни один не видел текст, который между тегами, но прекрасно видит атрибуты.
Статья отличная, просто учебник для всех, побольше бы таких, ну и дополнение про оптимизацию, память и ссылку на ИТС было бы неплохо указать — тогда было бы просто идеально! Буду рекомендовать коллегам к прочтению 🙂
Спасибо за статю много поучительного и интересного.Я бы сказал статья для чайников.Буду детально разбиратся с каждым примером. Автор так держать
Обнаружил пренеприятнейшую вещь — при действительно больших объёмах (4 585 894 строк, 222 411 694 символов) вызываемый из 1С объект Shell.RegExp валит 1С по недостатку памяти, даже на достойных серверах. Сами куски мелкие, рубить их ЧтениемТекста по разделителю — мало смысла. Жаль, что нет метода Прочитать(КоличествоСтрок,Разделитель), а есть только Прочитать(КолвоСимволов).
Кстати, никто не в курсе, ЧтениеУзловDOM сразу берёт всё (т.е. требует памяти) или идёт последовательно?
Журнал регистрации из под 8.2 не открылся в вашей конфе.
{Обработка.ЗагрузитьДанныеXML(1128)}: Ошибка чтения журанала регистрации: C:Documents and SettingsvoronovРабочий столЖурнал регистрации1.xml
{Обработка.ЗагрузитьДанныеXML(1057)}: Неверный формат
ВызватьИсключение Ошибка;
Увы. У вас есть наработки с поддержкой 8.2 или 8.3 форматов журнала регистрации?
(49) ya.Avoronov,
У меня таких наработок нет
(49) Я потихоньку делаю такую читалку, недели через 2-3 выложу.
Статья хорошая, а вот файл скачивать не стоит.
В прилагаемой конфигурации есть только два первых способа разбора, остальные отсутствуют. Копипастинг не получится 🙂
Листинги же этих способов в тексте даны мелкими картинками, на небольшом экране сломаешь глаза.
Но в остальном — прекрасное пособие для начинающих.
Как можно проверить наличие свойства некоторго тега у XML?
Использую 4-вариант (ФабрикаХДТО), некоторые поля могут быть нобязательные, поэтому приходится проверять их наличие самописной функцией (вернее дёргать значение свойства через неё):
Показать
Еще бы для сравнения варианты обработки с преобразованием XSLT. Позволяет несколькими строками кода получить на выходе требуемый объект в терминах 1С. Вот только для больших файлов XML (1 ГБ и больше) сложность возникает — памяти не всегда хватает.
Еще хотелось бы понять. Само по себе открытие файла XML уже занимает какие-то ресурсы, зависящие от размера файла. Есть предположение, что при открытии происходит проверка валидности файла. Есть информация по этой теме?
А то в последнее время приходится работать с XML сложной структуры просто огромных размеров. приходится извращаться. Иначе клиент валится по нехватке памяти. Про быстродействие молчу.
(54) Valerich, про нехватку памяти см (5)
Случайно обнаружил, что для фабрики XDTO схема XML может быть такой :
<xs:schema xmlns:xs=»http://www.w3.org/2001/XMLSchema» </xs:schema>
и 1С все прекрасно прочитает. Можно не париться ни с пакетами XDTO (3 вариант), ни со схемой (4 вариант). Все равно, какие бы типы элементов и атрибутов ты не определил в схеме, 1С их читает как string.
Также, если XML-файл не содержит реквизита URL-пространство имен, то это не помеха для чтения.
(52) sebum, Блин, сначала скачал, потом комент увидел. Качал просто чтобы код не набирать 🙂
А пятый листинг по api позволит с сайта забрать приходные накладные? Если со стороны сайта все готово.
А как поступить, если необходимо сериализовать большой табличный документ? Его же не запишешь частями? И в память приходится грузить целиком, в результате чего 1с падает по ошибке недостаточно памяти…
Автор, необходимо предупреждать в начале поста, что для .cf нужна платформа 8.3.5
Почему не прикрепить .rar, в котором прикрепить как .cf, так и сами обработки отдельно?
Решил попробовать разобрать 5-м методом xml файл с госзакупок. Разработчики как раз там поставляют и сам xml и схему xsd.
В документации сказано:
При попытке чтения вываливается с ошибкой..
Кто-то читал файлы с госзакупок при помощи поставляемой схемы? Подскажите в чем может быть ошибка?
Почему вы всегда игнорируете инструменты XSLT?
(66) кто-нибудь скиньте ссылочку и в двух словах про преимущества XSLT. Много информации не всегда нужный объем задач по парсингу XML.
(41) Получаешь последовательность, а потом текст:
Последовательность = ТвойОбъектXDTO_СТекстом.Последовательность();
Текст = Последовательность.ПолучитьТекст(0);
А не подскажет кто-нибудь?
есть такой xml-файл
можно для него использовать 5 метод?
и можно xmlns передавать из файла или нужно его задавать заранее?
(69)
я подразумевал, что нужно передевать в тип и можно ли взять это из файла?
(69) И еще вопрос.
можно ли в коде наложить условие на проверку, что это ОбъектXDTO или СписокXDTO?
Подскажите, как правильно сделать XDTO пакет для xml файла,
Возможно сочтете за некропостинг, но теперь многое из написаного можно записать еще более емко с помощью: ЗаполнитьЗначениеСвойств()
Вот упрощенный вариант понятного чтения в несколько строк небольших файлов, на примере типичного документа с табличной частью (сверка актов из 1с 77):
Показать
(71) Ты серьезно?)
ТипЗнч(ФабрикаXDTO.СписокXDTO) = Тип(«СписокXDTO»)
Не могу понять, как заставить фабрику прочитать значение из строки:
<Контрагент xmlns:xsi=»http://www.w3.org/2001/XMLSchema-instance» xsi:type=»CatalogRef.Контрагенты»>3722b978-d17a-11e5-89f0-001fc663b5b0</Контрагент>
Все объекты без проблем читаются методом = ФабрикаXDTO.ПрочитатьXML(ЧтениеXML)
и только контрагент имеет один атрибут type со значением CatalogRef.Контрагенты, куда девается ссылка?
Пакеты xdto вообще не использую, так как все объекты нормально читаются, но походу надо создать маленький пакет специально для этой строки.
Подскажите пожалуйста, как должен выглядеть этот микро-пакет или надо всё-таки создавать огромный пакет для всех объектов?
(75) Ответ на вопрос, может кому поможет (А Я УВЕРЕН В ЭТОМ ТАК КАК ПОТРАТИЛ НЕДЕЛЮ)
(77) В общие команды загляните
(78) Простите не увидел…
Автору спасибо, пригодилось очень.
Автору большое спасибо
Спасибо!
(76)
Безмерно благодарен, уж как только не пробовал схемы XML загружать, ниче не получалось. Я бы тоже неделю искал если не больше, если бы не твой коммент.
Спасибо, познавательная статья, как раз в скором времени пригодится))
Большое спасибо автору за примеры!
Возникла неудобная ситуация с обработкой списка в XML.
Если в списке одна строка, то возникает ошибка при попытке выполнить цикл, т.к. ЗаявкаXDTO.POSBreakages.POSBreakage является почему-то объектом XDTO, а если несколько строк, то ЗаявкаXDTO.POSBreakages.POSBreakage видится как СписокXDTO и обход проходит нормально, можно выкрутиться через попытку исключение, но красивое решение пока не удалось найти.
Для Каждого СтрокаPOSBreakages Из ЗаявкаXDTO.POSBreakages.POSBreakage Цикл
СтрокаPOSBreakagesСтруктура = Новый Структура(«POSBreakage_ID,SC_POSBreakage_ID,POSBreakage_Name»);
СтрокаPOSBreakagesСтруктура.POSBreakage_ID = СтрокаPOSBreakages.POSBreakage_ID;
СтрокаPOSBreakagesСтруктура.SC_POSBreakage_ID = СтрокаPOSBreakages.SC_POSBreakage_ID;
СтрокаPOSBreakagesСтруктура.POSBreakage_Name = СтрокаPOSBreakages.POSBreakage_Name;
ДокументЗаявкаСтруктура.POSBreakages.Добавить(СтрокаPOSBreakagesСтруктура);
КонецЦикла;
Предложите лучший вариант.
(85)
(85) я просто проверял такие строки на тип Если ТипЗнч(ЗаявкаXDTO.POSBreakages.POSBreakage)=Тип(«СписокXDTO») Тогда
Цикл… Иначе не цикл …
Спасибо!
Почему в cf не все указанные варианты примеров?
В разборе вижу только:
// Простой обход дерева
// Использование XPath
Где другие варианты??
(89)
Сорри, нашел все в «Общие команды»…)
Сорри, нашел ,в «Общие команды»…)