
Файл со всеми скриптами во вложении.
Скрипты не мои, собраны с ресурсов по MS SQL. Опубликованы скрипты и запросы, которыми сам часто пользуюсь
Большинство скриптов статьи и многие другие представлены в конфигурации:
Обновление однотипных конфигураций, работа с SQL и другие регламентные операции
Обслуживание индексов
Степень фрагментации индексов
Первый запрос показывает текущую фрагментацию индексов базы
SELECT TOP 100 DatbaseName = DB_NAME(), TableName = OBJECT_NAME(s.[object_id]), IndexName = i.name, i.type_desc, [Fragmentation %] = ROUND(avg_fragmentation_in_percent,2), page_count, partition_number, 'alter index [' + i.name + '] on [' + sh.name + '].['+ OBJECT_NAME(s.[object_id]) + '] REBUILD' + case when p.data_space_id is not null then ' PARTITION = '+convert(varchar(100),partition_number) else '' end + ' with(maxdop = 4, SORT_IN_TEMPDB = on)' [sql] FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s INNER JOIN sys.indexes as i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id left join sys.partition_schemes as p on i.data_space_id = p.data_space_id left join sys.objects o on s.[object_id] = o.[object_id] left join sys.schemas as sh on sh.[schema_id] = o.[schema_id] WHERE s.database_id = DB_ID() AND i.name IS NOT NULL AND OBJECTPROPERTY(s.[object_id], 'IsMsShipped') = 0 and page_count > 100 and avg_fragmentation_in_percent > 10 ORDER BY 4, page_count
Результат запроса:

Реорганизация/Перестроение индексов
Скрипт, приведенный ниже, запускает реорганизацию либо перестроение индексов для таблиц базы исходя из текущей дефрагментации (отбирает индексы, дефрагментированные более 10%, затем. если фрагментация менее 30% — реорганизация индексов, если более или равно 30% — перестроение). Я бы рекомендовал использовать как регламентное задание.
USE [myDB] GO SET NOCOUNT ON; SET QUOTED_IDENTIFIER ON; DECLARE @objectid int; DECLARE @indexid int; DECLARE @partitioncount bigint; DECLARE @schemaname nvarchar(130); DECLARE @objectname nvarchar(130); DECLARE @indexname nvarchar(130); DECLARE @partitionnum bigint; DECLARE @partitions bigint; DECLARE @frag float; DECLARE @command nvarchar(4000); -- Conditionally select tables and indexes from the sys.dm_db_index_physical_stats function -- and convert object and index IDs to names. SELECT object_id AS objectid, index_id AS indexid, partition_number AS partitionnum, avg_fragmentation_in_percent AS frag INTO #work_to_do FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL , NULL, 'LIMITED') WHERE avg_fragmentation_in_percent > 10.0 AND index_id > 0; -- Declare the cursor for the list of partitions to be processed. DECLARE partitions CURSOR FOR SELECT * FROM #work_to_do; -- Open the cursor. OPEN partitions; -- Loop through the partitions. WHILE (1=1) BEGIN; FETCH NEXT FROM partitions INTO @objectid, @indexid, @partitionnum, @frag; IF @@FETCH_STATUS < 0 BREAK; SELECT @objectname = QUOTENAME(o.name), @schemaname = QUOTENAME(s.name) FROM sys.objects AS o JOIN sys.schemas as s ON s.schema_id = o.schema_id WHERE o.object_id = @objectid; SELECT @indexname = QUOTENAME(name) FROM sys.indexes WHERE object_id = @objectid AND index_id = @indexid; SELECT @partitioncount = count (*) FROM sys.partitions WHERE object_id = @objectid AND index_id = @indexid; -- 30 is an arbitrary decision point at which to switch between reorganizing and rebuilding. IF @frag < 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REORGANIZE'; IF @frag >= 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REBUILD'; IF @partitioncount > 1 SET @command = @command + N' PARTITION=' + CAST(@partitionnum AS nvarchar(10)); EXEC (@command); PRINT N'Executed: ' + @command; END; -- Close and deallocate the cursor. CLOSE partitions; DEALLOCATE partitions; -- Drop the temporary table. DROP TABLE #work_to_do; GO SET QUOTED_IDENTIFIER OFF; GO
Отсутствующие индексы
Общее количество отсутствующих индексов в базах:
SELECT [DatabaseName] = DB_NAME(database_id), [Number Indexes Missing] = count(*) FROM sys.dm_db_missing_index_details GROUP BY DB_NAME(database_id) ORDER BY 2 DESC
Отсутствующие индексы, вызывающие высокие издержки:
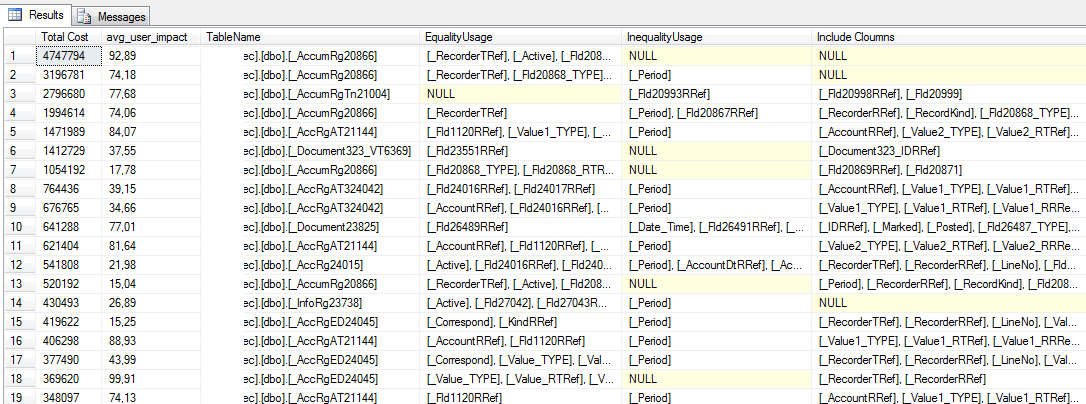
SELECT TOP 100 [Total Cost] = ROUND(avg_total_user_cost * avg_user_impact * (user_seeks + user_scans),0), avg_user_impact, TableName = statement, [EqualityUsage] = equality_columns, [InequalityUsage] = inequality_columns, [Include Cloumns] = included_columns FROM sys.dm_db_missing_index_groups g INNER JOIN sys.dm_db_missing_index_group_stats s ON s.group_handle = g.index_group_handle INNER JOIN sys.dm_db_missing_index_details d ON d.index_handle = g.index_handle WHERE database_id = DB_ID() ORDER BY [Total Cost] DESC
Результат запроса:
К анализу недостающих индексов можно еще добавить активность таблиц на чтение/запись:
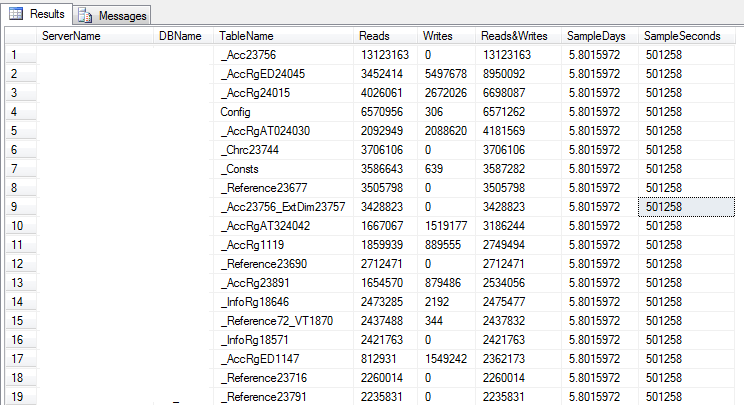
-- Table Reads and Writes -- Heap tables out of scope for this query. Heaps do not have indexes. -- Only lists tables referenced since the last server restart SELECT @@ServerName AS ServerName , DB_NAME() AS DBName , OBJECT_NAME(ddius.object_id) AS TableName , SUM(ddius.user_seeks + ddius.user_scans + ddius.user_lookups) AS Reads , SUM(ddius.user_updates) AS Writes , SUM(ddius.user_seeks + ddius.user_scans + ddius.user_lookups + ddius.user_updates) AS [Reads&Writes] , ( SELECT DATEDIFF(s, create_date, GETDATE()) / 86400.0 FROM master.sys.databases WHERE name = 'tempdb' ) AS SampleDays , ( SELECT DATEDIFF(s, create_date, GETDATE()) AS SecoundsRunnig FROM master.sys.databases WHERE name = 'tempdb' ) AS SampleSeconds FROM sys.dm_db_index_usage_stats ddius INNER JOIN sys.indexes i ON ddius.object_id = i.object_id AND i.index_id = ddius.index_id WHERE OBJECTPROPERTY(ddius.object_id, 'IsUserTable') = 1 AND ddius.database_id = DB_ID() GROUP BY OBJECT_NAME(ddius.object_id) ORDER BY [Reads&Writes] DESC; GO
Результат запроса:
Неиспользуемые индексы
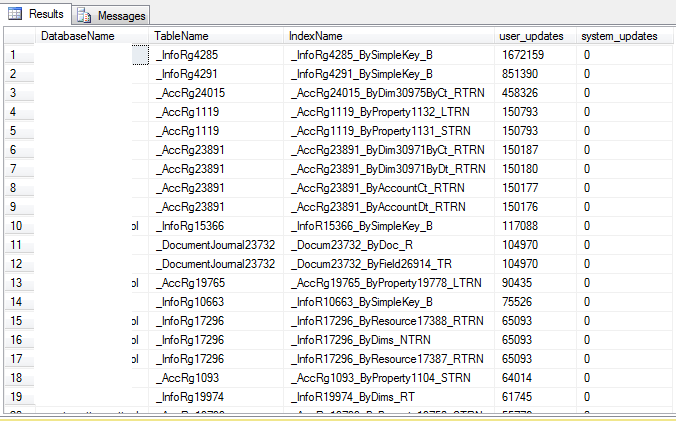
-- Create required table structure only. -- Note: this SQL must be the same as in the Database loop given in the following step. SELECT TOP 1 DatabaseName = DB_NAME() ,TableName = OBJECT_NAME(s.[object_id]) ,IndexName = i.name ,user_updates ,system_updates -- Useful fields below: --, * INTO #TempUnusedIndexes FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id WHERE s.database_id = DB_ID() AND OBJECTPROPERTY(s.[object_id], 'IsMsShipped') = 0 AND user_seeks = 0 AND user_scans = 0 AND user_lookups = 0 AND s.[object_id] = -999 -- Dummy value to get table structure. ; -- Loop around all the databases on the server. EXEC sp_MSForEachDB 'USE [?]; -- Table already exists. INSERT INTO #TempUnusedIndexes SELECT TOP 10 DatabaseName = DB_NAME() ,TableName = OBJECT_NAME(s.[object_id]) ,IndexName = i.name ,user_updates ,system_updates FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id WHERE s.database_id = DB_ID() AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0 AND user_seeks = 0 AND user_scans = 0 AND user_lookups = 0 AND i.name IS NOT NULL -- Ignore HEAP indexes. ORDER BY user_updates DESC ; ' -- Select records. SELECT TOP 100 * FROM #TempUnusedIndexes ORDER BY [user_updates] DESC -- Tidy up. DROP TABLE #TempUnusedIndexes
Результат:
Индексы с высокими издержками
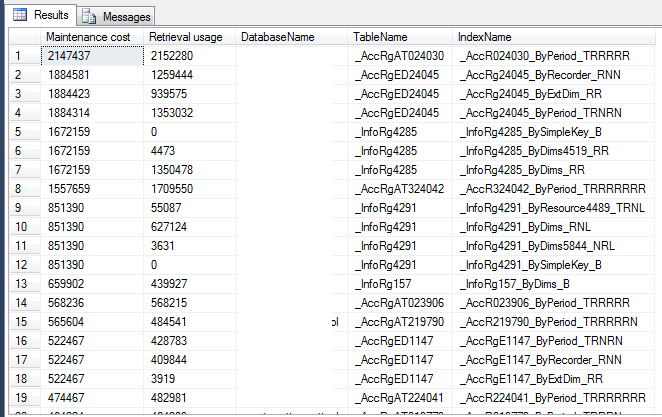
-- Create required table structure only. -- Note: this SQL must be the same as in the Database loop given in the following step. SELECT TOP 1 [Maintenance cost] = (user_updates + system_updates) ,[Retrieval usage] = (user_seeks + user_scans + user_lookups) ,DatabaseName = DB_NAME() ,TableName = OBJECT_NAME(s.[object_id]) ,IndexName = i.name INTO #TempMaintenanceCost FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id WHERE s.database_id = DB_ID() AND OBJECTPROPERTY(s.[object_id], 'IsMsShipped') = 0 AND (user_updates + system_updates) > 0 -- Only report on active rows. AND s.[object_id] = -999 -- Dummy value to get table structure. ; -- Loop around all the databases on the server. EXEC sp_MSForEachDB 'USE [?]; -- Table already exists. INSERT INTO #TempMaintenanceCost SELECT TOP 10 [Maintenance cost] = (user_updates + system_updates) ,[Retrieval usage] = (user_seeks + user_scans + user_lookups) ,DatabaseName = DB_NAME() ,TableName = OBJECT_NAME(s.[object_id]) ,IndexName = i.name FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id WHERE s.database_id = DB_ID() AND i.name IS NOT NULL -- Ignore HEAP indexes. AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0 AND (user_updates + system_updates) > 0 -- Only report on active rows. ORDER BY [Maintenance cost] DESC ; ' -- Select records. SELECT TOP 100 * FROM #TempMaintenanceCost ORDER BY [Maintenance cost] DESC -- Tidy up. DROP TABLE #TempMaintenanceCost
Пример работы:
Часто используемые индексы
-- Create required table structure only. -- Note: this SQL must be the same as in the Database loop given in the -- following step. SELECT TOP 1 [Usage] = (user_seeks + user_scans + user_lookups) ,DatabaseName = DB_NAME() ,TableName = OBJECT_NAME(s.[object_id]) ,IndexName = i.name INTO #TempUsage FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id WHERE s.database_id = DB_ID() AND OBJECTPROPERTY(s.[object_id], 'IsMsShipped') = 0 AND (user_seeks + user_scans + user_lookups) > 0 -- Only report on active rows. AND s.[object_id] = -999 -- Dummy value to get table structure. ; -- Loop around all the databases on the server. EXEC sp_MSForEachDB 'USE [?]; -- Table already exists. INSERT INTO #TempUsage SELECT TOP 10 [Usage] = (user_seeks + user_scans + user_lookups) ,DatabaseName = DB_NAME() ,TableName = OBJECT_NAME(s.[object_id]) ,IndexName = i.name FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id WHERE s.database_id = DB_ID() AND i.name IS NOT NULL -- Ignore HEAP indexes. AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0 AND (user_seeks + user_scans + user_lookups) > 0 -- Only report on active rows. ORDER BY [Usage] DESC ; ' -- Select records. SELECT TOP 100 * FROM #TempUsage ORDER BY [Usage] DESC -- Tidy up. DROP TABLE #TempUsage
Пример работы:
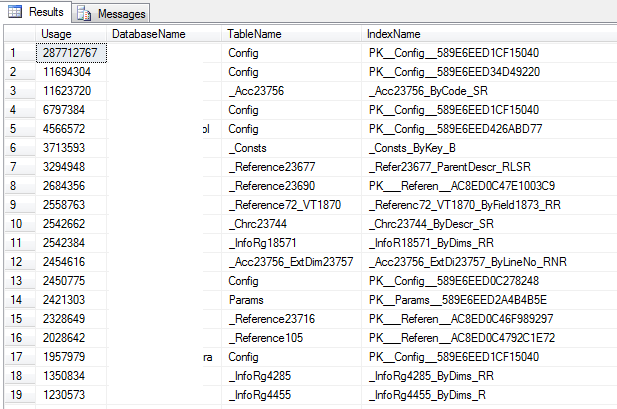
Планы запросов
Самые тяжелые запросы
SELECT TOP 10 SUBSTRING(qt.TEXT, (qs.statement_start_offset/2)+1, ((CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH(qt.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset)/2)+1), qp.query_plan, qs.execution_count, qs.total_logical_reads, qs.last_logical_reads, qs.total_logical_writes, qs.last_logical_writes, qs.total_worker_time, qs.last_worker_time, qs.total_elapsed_time/1000000 total_elapsed_time_in_S, qs.last_elapsed_time/1000000 last_elapsed_time_in_S, qs.last_execution_time FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp ORDER BY qs.total_logical_reads DESC -- logical reads -- ORDER BY qs.total_logical_writes DESC -- logical writes -- ORDER BY qs.total_worker_time DESC -- CPU time
Пример:
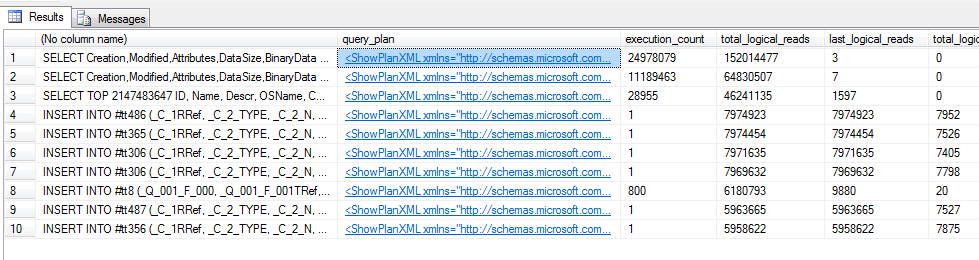
Параллельные планы запросов
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
WITH XMLNAMESPACES
(DEFAULT
'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan AS CompleteQueryPlan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)')
AS StatementText, n.value('(@StatementSubTreeCost)[1]',
'VARCHAR(128)') AS StatementSubTreeCost, dm_ecp.usecounts
FROM sys.dm_exec_cached_plans AS dm_ecp
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS dm_eqp
CROSS APPLY query_plan.nodes
('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple')
AS qp(n)
WHERE
n.query('.').exist('//RelOp[@PhysicalOp="Parallelism"]') = 1
GO
Пример:
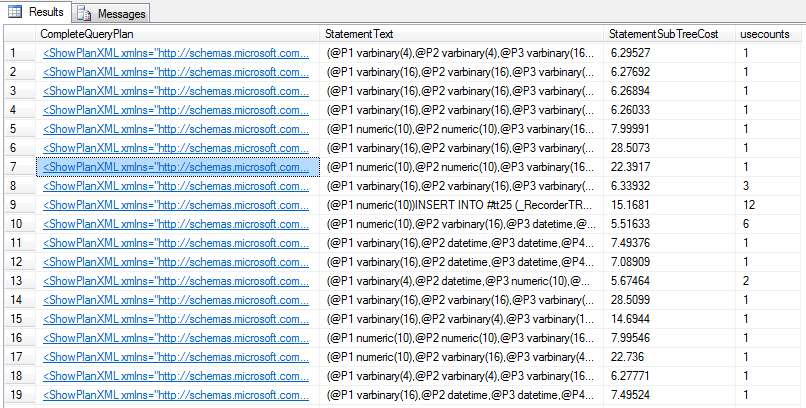
Пример плана запроса:

Статистики ожиданий
В этом запросе исключены незначимые типы ожиданий:
SELECT TOP 10 wait_type , max_wait_time_ms wait_time_ms , signal_wait_time_ms , wait_time_ms - signal_wait_time_ms AS resource_wait_time_ms , 100.0 * wait_time_ms / SUM(wait_time_ms) OVER ( ) AS percent_total_waits , 100.0 * signal_wait_time_ms / SUM(signal_wait_time_ms) OVER ( ) AS percent_total_signal_waits , 100.0 * ( wait_time_ms - signal_wait_time_ms ) / SUM(wait_time_ms) OVER ( ) AS percent_total_resource_waits FROM sys.dm_os_wait_stats WHERE wait_time_ms > 0 -- уберем нулевые задержки AND wait_type NOT IN ( 'SLEEP_TASK', 'BROKER_TASK_STOP', 'BROKER_TO_FLUSH', 'SQLTRACE_BUFFER_FLUSH','CLR_AUTO_EVENT', 'CLR_MANUAL_EVENT', 'LAZYWRITER_SLEEP', 'SLEEP_SYSTEMTASK', 'SLEEP_BPOOL_FLUSH', 'BROKER_EVENTHANDLER', 'XE_DISPATCHER_WAIT', 'FT_IFTSHC_MUTEX', 'CHECKPOINT_QUEUE', 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TRANSMITTER', 'FT_IFTSHC_MUTEX', 'KSOURCE_WAKEUP', 'LAZYWRITER_SLEEP', 'LOGMGR_QUEUE', 'ONDEMAND_TASK_QUEUE', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT', 'BAD_PAGE_PROCESS', 'DBMIRROR_EVENTS_QUEUE', 'BROKER_RECEIVE_WAITFOR', 'PREEMPTIVE_OS_GETPROCADDRESS', 'PREEMPTIVE_OS_AUTHENTICATIONOPS', 'WAITFOR', 'DISPATCHER_QUEUE_SEMAPHORE', 'XE_DISPATCHER_JOIN', 'RESOURCE_QUEUE' ) ORDER BY wait_time_ms DESC
Расшифровка статистик ожиданий
Пример результата:
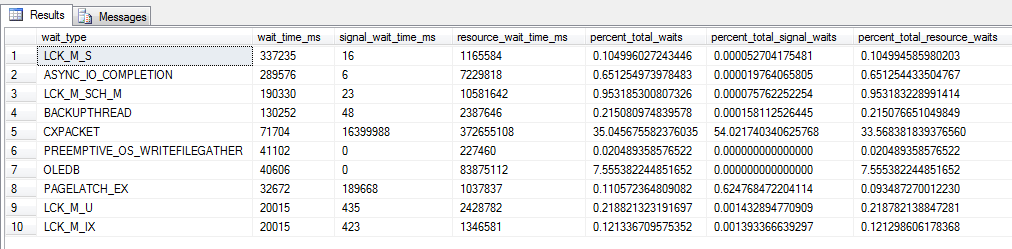
Следует иметь ввиду, что статистика не сохраняется при перезапуске SQL Server, и все данные накапливаются с момента последнего сброса статистики или перезапуска сервера.
Очистка статистик ожидания:
DBCC SQLPERF(waitstats, CLEAR) GO
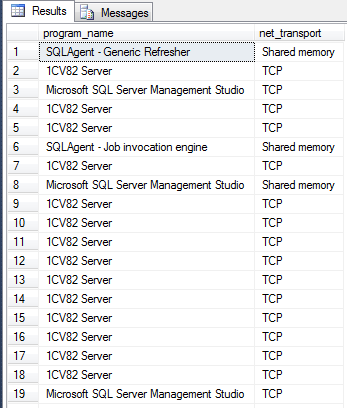
Рабочие протоколы
select program_name,net_transport from sys.dm_exec_sessions as t1 left join sys.dm_exec_connections AS t2 ON t1.session_id=t2.session_id where not t1.program_name is null
Пример:
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Спасибо. Погонял на тестовом сервере с несколькими базами — некоторые запросы выдали любопытные вещи. На которые раньше не обратил бы внимания и жил бы себе спокойно… 🙂
(1) не за что, периодически буду обновлять, как найду что-нибудь интересное
Еще бы описание, как применять полученные результаты.
(3) здесь интернет в помощь, только для типов ожидания кучи статей
Утащил в эвернот, спасибо )
(4) если так рассуждать, то по анализу производительности в инете тоже статей куча. Хотелось бы здесь сразу видеть ссылки на эти статьи, которые помогут расшифровать результаты.
(6) начнем с того, какой результат вы хотите расшифровать?
Отлично, да, спасибо, самому не писать и не искать. Как раз все доработки дописал и до производительности добрался.
(6) Armando, тут должна быть ссылка на книгу «Настольная книга эксперта по технологическим вопросам»… Серьезно, тут не пара статей будет. Даже не пара десятков…. Я бы так и гуглил: «производительность 1С план запроса», «производительность 1С индексы», «производительность 1С блокировки… я так и гуглил в свое время, почитал и пошел книжки читать, чтобы информация не кусками надерганная была, а упорядоченная…
Подписаться забыл на тему.
Спасибо за тему. Подписался.
Спасибо! Очень полезный инструментарий. Давно хотел собрать себе такой же.
Спасибо буду изучать.
Хороший наборчик.
Вот если бы еще все это с анализом на стороне 1С. Т.е. чтоб и поля показал, из которых индексы состоят и т.п. Например как у Алексея:
Зачем клонировать давным давно написанное без своих рекомендаций и результатов опыта?
Лучше прочитать оригинал статьи от .microsoft:
И вот еще в копилку . Нарыл это Алексей Лустин (lustin), за что ему большое спасибо.
(15) спасибо за ссылку, мне следовало указать её в статье
(14) индексы можно посмотреть или любой другой аналогичной, при помощи нее можно найти и избыточные индексы и убрать галочку индексировать с соответствующих реквизитов
(19)jan27
Для регистров немного сложнее, может потребоваться изменение порядка следования измерений или включение и настройка агрегатов.
(19) ну а почему бы сразу не сделать один отличный инструмент и не вошкаться в кучке маленьких переключаясь из одной в другую?
(20) да, согласен, я говорил о простых и явно избыточных по определенному реквизиту, к тому же к сожалению платформа 1С не позволяет создавать рекомендуемые индексы
(22)jan27
Ну в плане новых типовых это уже не так критично, года с 2008 в 1С всё-таки одумались и перестали в типовых конфигурациях выставлять режим индексирования в реквизитах, оставив специалистам на месте решать какие поля требуют дополнительного индексирования.
(23) однако, это не мешает некоторым «специалистам» индексировать эти реквизиты, о чем я и толкую. Не у всех конфиурации под контролем своих программистов, а достаются в наследство от «топовых» франчей. Еще раз подчеркиваю, что подход должен быть сугубо индивидуальный и я осознанно не привожу конкретики типа делай раз, делай два и … опа ускорение 1с в 100 раз
(23) h00k,
Ага. См. регистры аналитики учета затрат в УПП )
Ну есть все же поля, однозначно требующие индексирования — и будь конфа тридцать три раза типовой — индекс там стоять должен )
Многострадальный sys.dm_exec_query_stats можно еще использовать так, топ 30 запросов по длительности блокировки.
Показать
Наблюдаем за памятью: если Free Pages меньше 300, объем ОЗУ узкое место в производительности системы.
Когда уже про PostreSQL все разжуют? Справедливости ради например =)
(28) у тебя есть шанс быть первым))
Кину сюда, похожий материал из своей коллекции:
(30) спасибо, оригинал:
Вот бы еще скрипт с интеллектуальным обновлением статистики: обновить статистику только по тем таблицам, где например более 5% измененных записей (как с фрагментацией индексов)
У меня подобное сделано. но это концепт — при желании можно допиливать под себя.
(32) читай (16)
Перекрывающаяся статистика
Показать
(34) JohnyDeath, Ух, дух захватывает, спасибо!
(17) h00k, Запросы 1 и 2. Усреднение часто поднимает вверх «одиночек», есть риск не увидеть массовые запросы с низким значением [Average CPU used] но высоким [Total CPU used].А их оптимизация дает больший эффект.
Конечно и по средней надо смотреть и по «Итого» и по максимальным значениям, комбинация выборок дает более полную картинку.
(37)Sergey.Noskov Да, возможно это стоило указать в комментариях к запросам. Как-то не пришло в голову что коллеги могут не додуматься изменить опубликованную версию запроса для получения полной картины, и будут довольствоваться только средними показателями.
(32) sorb, есть вот такой еще вариант:
Почему у некоторых запросов из представления dm_exec_query_stats поле total_elapsed_time меньше чем total_worker_time? Подозреваю, что связано с распараллеливанием, но как в таком случае посчитать время ожидания?
(40) подозреваю, что используя данное представление, никак… подробнее Об этом запросе:
Поизучал свои базы и обнаружил, что у таблицы «группы пользователей» сильно нагружен некластерный индекс. А кластерный, более быстрый, простаивает в основном. Вот если я поменяю кластерность, ничем не чревато? Ну, не считая нарушения запретов 1С.
(42) Painted, поменяйте порядок реквизитов в конфигураторе так, чтобы некластерный индекс стал кластерным. Хотя особой разницы в том, какой индекс, нет. Странно то, что индекс вообще используется — если записей сильно меньше 1000, то сканирование дешевле обходится. Или у Вас групп супермного?
(43) sorb, Групп штук 30. Индексы лучше вообще убрать?
(42) следуя такое возможно. учитывая. что кластерный индекс по умолчанию по первичному ключу, со стороны 1С — при обновлении все вернется на свои места… стоит ли овчинка выделки?
Можете попробовать на копии базы и сравнить производительность
(44) если у реквизитов проставлен признак индексировать, то лучше убрать (в конфигураторе)
(43) порядок реквизитов не меняет некластерный индекс на кластерный
Не самописные скрипты можно было бы и бесплатно опубликовать. Однако за материал спасибо — пригодилось. )
Хочу подсчитать среднюю степень параллелизма запроса. Лучшая оценка будет total_worker_time / total_elapsed_time ?
(49) очень грубая оценка. т.к. total_worker_time может быть меньше total_elapsed_time ввиду ожиданий на задержках. Степень параллелизма указывает в ShowPlan statics
(50) Это какого представления колонка «ShowPlan statics» ? Если ты про сам план запроса, то понятно, что там все детально видно. Нужна именно оценка для всего запроса. Понятно, что она будет грубой. Я просто ищу наилучшую.
(51) Да, про план запроса
(44) Painted, при таком количестве записей индекс получится больше, чем сама таблица, ну и при любых соединениях гарантированно будет использован nested loops из-за малого количества записей
(47) да, забыл, что это справочник, а не регистр сведений. Но по сути вопроса имхо в данном случае индексы нужны как рыбе зонтик 🙂
Параллельные запросы и использование ЦПУ
на всякий случай скрипты
Показать
Показать
запросы к sys.dm_exec_cached_plans (количество adhoc, prepared и др.
Показать
Нашел еще один , автор скрипы понемногу дополняет и поддерживает в актуальном состоянии.
Адрес:
(58) что-то ссылка не работает, может просто адрес скинешь?
(58) Ссылка не открывается…
На просторах нашел и там про sp_WhoIsActive
Интересная подборка, спасибо!
Подпишусь, спасибо за подборку.