<?php // Полная загрузка сервисных книжек, создан 2026-01-05 12:44:55
global $wpdb2;
global $failure;
global $file_hist;
///// echo '<H2><b>Старт загрузки</b></H2><br>';
$failure=FALSE;
//подключаемся к базе
$wpdb2 = include_once 'connection.php'; ; // подключаемся к MySQL
// если не удалось подключиться, и нужно оборвать PHP с сообщением об этой ошибке
if (!empty($wpdb2->error))
{
///// echo '<H2><b>Ошибка подключения к БД, завершение.</b></H2><br>';
$failure=TRUE;
wp_die( $wpdb2->error );
}
$m_size_file=0;
$m_mtime_file=0;
$m_comment='';
/////проверка существования файлов выгрузки из 1С
////файл выгрузки сервисных книжек
$file_hist = ABSPATH.'/_1c_alfa_exchange/AA_hist.csv';
if (!file_exists($file_hist))
{
///// echo '<H2><b>Файл обмена с сервисными книжками не существует.</b></H2><br>';
$m_comment='Файл обмена с сервисными книжками не существует';
$failure=TRUE;
}
/////инициируем таблицу лога
/////если не существует файла то возврат и ничего не делаем
if ($failure){
///включает защиту от SQL инъекций и данные можно передавать как есть, например: $_GET['foo']
///// echo '<H2><b>Попытка вставить запись в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>$m_comment));
wp_die();
///// echo '<H2><b>Возврат в начало.</b></H2><br>';
return $failure;
}
/////проверка лога загрузки, что бы не загружать тоже самое
$masiv_data_file=stat($file_hist); ////передаем в массив свойство файла
$m_size_file=$masiv_data_file[7]; ////получаем размер файла
$m_mtime_file=$masiv_data_file[9]; ////получаем дату модификации файла
////создаем запрос на получение последней удачной загрузки
////выбираем по штампу времени создания (редактирования) файла загрузки AA_hist.csv, $m_mtime_file
///// echo '<H2><b>Размер файла: '.$m_size_file.'</b></H2><br>';
///// echo '<H2><b>Штамп времени файла: '.$m_mtime_file.'</b></H2><br>';
///// echo '<H2><b>Формирование запроса на выборку из лога</b></H2><br>';
////препарируем запрос
$text_zaprosa=$wpdb2->prepare("SELECT * FROM `vin_logs` WHERE `last_mtime_upload` = %s", $m_mtime_file);
$results=$wpdb2->get_results($text_zaprosa);
if ($results)
{ foreach ( $results as $r)
{
////если штамп времени и размер файла совпадают, возврат
if (($r->last_mtime_upload==$m_mtime_file) && ($r->last_size_upload==$m_size_file))
{////echo '<H2><b>Возврат в начало, т.к. найдена запись в логе.</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>'Загрузка отменена, новых данных нет, т.к. найдена запись в логе.'));
wp_die();
return $failure;
}
}
}
////если данные новые, пишем в лог запись о начале загрузки
/////echo '<H2><b>Попытка вставить запись о начале загрузки в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>0, 'last_size_upload'=>$m_size_file, 'comment'=>'Начало загрузки'));
////очищаем таблицу
$clear_tbl_zap=$wpdb2->prepare("TRUNCATE TABLE %s", 'vin_history');
$clear_tbl_zap_repl=str_replace("'","`",$clear_tbl_zap);
$results=$wpdb2->query($clear_tbl_zap_repl);
///// echo '<H2><b>Очистка таблицы сервисных книжек</b></H2><br>';
if (empty($results))
{
///// echo '<H2><b>Ошибка очистки таблицы книжек, завершение.</b></H2><br>';
//// если очистка не удалась, возврат
$failure=TRUE;
wp_die();
return $failure;
}
////загружаем данные
$table='vin_history'; // Имя таблицы для импорта
//$file_hist Имя CSV файла, откуда берется информация // (путь от корня web-сервера)
$delim=';'; // Разделитель полей в CSV файле
$enclosed='"'; // Кавычки для содержимого полей
$escaped='\









А почему profiler, а не технологический журнал?
Отличный опыт, спасибо.
Согласен с (1). По ТЖ проще найти проблемный запрос в 1С.
(1)(3) Парни, а разве ТЖ показывает ПВЗ?
(1) awk,
По ТЖ можно найти самый долгий запрос. В нашем случае — это будет последний запрос (где соединяется несколько раз таблица на 2 млн. строк), но проблема то не в нем, а запросе, который эти 2 млн. строк формирует, а он то как раз выполняется гораздо быстрее чем последний :), а запрос в котором на самом деле была ошибка, вообще за 2 секунды выполняется. И как здесь поможет ТЖ? 🙂 Или я чего-то не знаю про возможности ТЖ
(4) barelpro,
да, начиная с 8.2.14 показывает
«Реализована возможность помещения в технологический журнал плана запроса СУБД. Для этого в конфигурационный файл технологического журнала добавлен элемент <planSQL> и свойство «planSQLText» для событий исполнения операторов SQL различных СУБД.»
см.
(2) Armando,
Не за что, рад что пригодился.
(6) headMade,
Спасибо за информацию, как говорится «Век живи, век учись» (с).
Упустил я видимо этот момент. Но если я правильно понимаю там ПВЗ в виде текста, а визуализировать его хз как, да и найти в дебрях ТЖ нужный нам запрос, тоже занятие не из приятных я думаю. Парсеров не так много и я не уверен, что парсеры отрабатывают свойство planSQLText.
И кстати там ПВЗ с расширенной аналитикой по таблицам? (т.е. количество строк, предикаты, вес и т.д.)?
(8) krolya,
для MSQL в ТЖ пишет Rows, Executes, EstimateRows, EstimateIO, EstimateCPU, AvgRowSize, TotalSubtreeCost, EstimateExecutions, StmtText.
Для визуализации обратите внимание на Инструменты разработчика вот
(также не забываем про сервисы Гилева)
Ну а что касается вашей ситуации (нашли замером производительности долгий запрос), то как мне кажется profiler тут подходит как ничто другое.
(9) Да, в ИР есть неплохая иллюстрация того, что дает собирать техножурнал по выполняемым запросам в определенной мере независимо от СУБД. План запроса естественно СУБД специфичен. В видео показан анализ плана запроса СУБД MS SQL.
Попробуйте ЦУП и забудьте ручное ковыряние в трассировке и сопоставление с текстами запросов/метаданными как страшный сон.
я так и не понял, а зачем все это надо было делать, есть же бесплатные сервисы
зачем изобретать велосипед?
Довольно не тривиальный путь поиска ошибок…это как для диагностики не исправности у авто самому спаять плату для диагностики… есть же велосипеды уже.
Вот план запроса в наших сервисах

нафига такой огород с профайлером?
Ну вот, нормальная статья. Не всякие теоретические сопли скопипастенные из интернета, а реальный, боевой опыт!
За картинку отдельный +
Вот скриншот плана запроса из инструмента «Анализ техножурнала» инструментов разработчика. Обратите внимание, здесь имена полей и таблиц уже переведены в термины метаданных (опция).
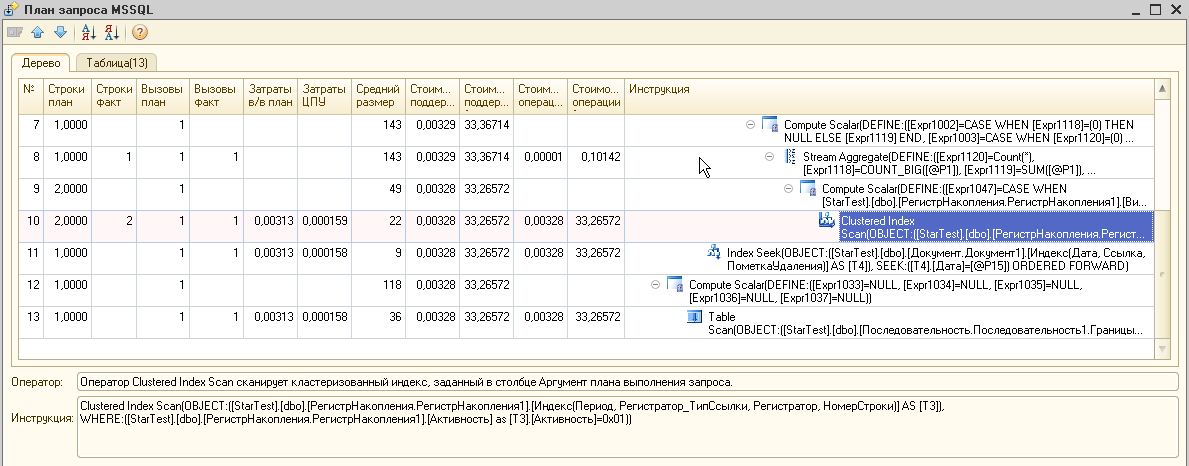
(12) Gilev.Vyacheslav, Не отовсюду к ним достучатся можно. Одно слово — online. 🙂 Вот и приходится по старинке.
(15) DoctorRoza, опыт — однозначно да
однако описание как работать профайлером на не 1с-ких форумах мульён!
сейчас новички вместо того чтобы сходить почитать документацию к 1С:ЦУП прочтут эту статью, решать что они теперь «НЕО» и знают «кунфу» и потом понесутся «гневные письма в 1С» про то что приходится бороться с мнимыми трудностями
по поводу консоли запросов с планом запроса — у нас она тоже есть, взял выполнил запрос и сразу увидел план не выходя из 1С
при всем уважение — это не просто сопли, а извините достаточно «старые»
я вот так и не увидел
извините за прямоту…
(18) awk, а ЦУП использовать который не онлайн что мешает?
и потом, что значит «онлайн» — у вас нет интернета? не верю! разверните подробней
По поводу плана запроса. Помимо ЦУПа, Онлайна Вячеслава и ИР Сергея есть еще Enterprise Integrator от Германа Кудякова. С недавних пор план запроса у него свой: с шахматами и барышнями
У Вячеслава пока чуть хуже чем у Сергея — не определяются автоматом имена таблиц 1С, да и выглядит заметно хуже.
Кстати, а кто как определяет имена таблиц? Я сделал вьюхи на все таблицы и потом смотрю «зависимости» в интересуемой таблице вида «_InfoRg43»
(21) JohnyDeath, вы красиво смешали ЦУП, которые накапливает статистику и ранжирует проблемы и консоль ИР — она на сколько я последний раз, ничего подобного не умела, я не прав, уже задублировала бесплатно ЦУП?
Ну, что сказать?! Точно в цель!!! И по теме и по содержимому. В деле SQL-тюнинга, визуальный план выполнения запросов — это наше все! Важно, что решение предполагает только штатные средства.
Ссылки на другие источники уместны и респектабельны ))) Так, что автору «Респект и уважуха!» (С).
Статья просится в золотой фонд Инфостарта. Знаю, что вернусь к ней еще не раз.
Для меня она, как точка входа на другие ресурсы (такая себе дверь в коморке Папы-карлы). Так, что… бросаю якорь в закладках )))
(20) Gilev.Vyacheslav,
Вячеслав, если бы не данная статья с ссылками на ваши работы, раскатал бы вас здесь и сейчас за неуместную рекламу своего велосипеда пусть даже с хорошим моторчиком (рука так и тянулась к минусу)
Берите пример с tormozit — мягко и не навязчиво продвигается на пользу себе и людям )))
(21) JohnyDeath,
(22) JohnyDeath,
показываются, если подключен сервис
так сделано, потому что сервис Анализа запросов не авторизуется и не подключается к базе (т.е. максимально безопасный насколько это вообще в природе возможно)
Второй сервис выполняет ком-подключение к исследуемой базе и требует ввести логин пароль.
(25) Evgen.Ponomarenko, ни от вас и ни от автора не услышал, зачем нужен профайлер при наличии огромного выбора альтернатив, и не только моих инструментов — кроме как простыми путями не идем
любой уважающий себя программист может легко руками настроить logfcg.xml и в течении пары минут посмотреть план запроса в логах ТЖ, не обманывайте себя и других
(13) Confucius,
Я тоже сначала так подумал… но из контекста статьи видно, что автор разбирался с чужим-чужим-чужим черным ящиком. Он использовал формальный подход и штатные средства — классика жанра, зачетно!
(23) Gilev.Vyacheslav, Вы тоже красиво умолчали о стоимости. В данной конкретной проблеме ИРа бы хватило. Мы ведь обсуждаем то, почему автор не использовал ЦУП, верно?
(27) Спасибо, не знал. И нигде раньше этого не слышал. По-моему, я у вас давным-давно спрашивал про разрешение имен таблиц в имена таблиц 1С.
(26) Оно оказывается тоже платное. ( Посмотреть не получится. И она скорее всего идет в составе всей конфы. Верно?
(29) JohnyDeath, о стоимости ЦУПа — любой разработчик может себе позволить НФР версию цупа (по памяти это тысяч десять рублей) имхо это не заоблачная стоимость и ее легко включить в общую стоимость проекта, в рамках которого оптимизируете запрос, если вы франч и делаете это для клиента, то цуп должен вообще купить клиент, для вас он будет бесплатен
ну и где здесь сложности?
(30) Evgen.Ponomarenko,
штатные средства — это технологический журнал, хватит людей обманывать!
(32) Gilev.Vyacheslav,
Это с какой стороны посмотреть, с точки зрения ADB — штатное средство профайлер микрософта в данном случае.
(33) Evgen.Ponomarenko, с точки зрения АДБ он не правит запросы в 1С
(34) Gilev.Vyacheslav,
Я 5 лет проработал в секторе администрирования БД. Мы постоянно мониторили производительность, вместе с программистами решали задачи оптимизации. Под Oracle в 2000 году были такие средства оптимизации, что 1С еще шагать и шагать. К примеру, можно было провести анализ нарушений 3-й нормальной формы. Автоматизация позволяла выгребать ошибки сторонних разработчиков тоннами. В данном случае в статье речь идет об альтернативе, которая имеет место быть. А чем больше возможностей — тем оптимальней решение.
(12)Gilev.Vyacheslav,
(14)Gilev.Vyacheslav,
Вячеслав, добрый день. Отвечу один раз на все сообщения.
Когда я написал фразу: «использовать SQL Profiler для анализа и оптимизации «узких мест» в больших «многоэтажных» запросах», то я в первую очередь имел ввиду не сам SQL Profiler, а именно план выполнения запроса. Если вы заметили, я в Выводах к статье прямым текстом написал, что есть консоль запросов 1С, которая умеет показывать план выполнения запроса и именно ее рекомендовал к использованию для получения плана выполнения более быстрым и удобным способом. Мне без разницы как получить план выполнения запроса, главное чтобы он был. Получу я его через SQL Profiler, консоль или Ваш сервис — мне все равно. Я использовал инструмент, который был под рукой. Он НЕ САМЫЙ УДОБНЫЙ, НЕ САМЫЙ ЛУЧШИЙ и вообще не самый-самый и я нигде в статье не говорил, что это единственный и самый удобный инструмент (очевидно, что это не так).
Целью статьи было показать логику и методику проведения оптимизации для очень больших запросов с использованием плана выполнения запроса на одном примере, а не сравнить все возможные средства получения плана выполнения запросов или рассмотреть все возможные методики проведения оптимизации.
Ну и повторюсь — самый долгий запрос в пакете запросов (не равно) неоптимальный или некорректный, причина его неоптимальности, часто лежит в других запросах.
Кстати, что интересно — вот в соседней статье обсуждается проблема визуализации больших запросов на примере ЗУП 2.5 и там используются ну совсем не штатные средства 🙂
(28) Gilev.Vyacheslav,
Любой уважающий себя программист волен быть свободен в выборе инструментов для достижения целей и я не вижу чем вариант получения плана выполнения запроса через SQL Profiler принципиально отличается от получения плана выполнения запроса через ТЖ.
Ну и любой уважающий себя программист может легко подключиться к SQL Profiler’у и посмотреть план запроса в трейсе — не обманывайте других!
Только ПОСМОТРЕТЬ план запроса в логах ТЖ, это еще не решение задачи — нужно ПОСМОТРЕТЬ план выполнения НУЖНОГО ЗАПРОСА (просто посмотреть план выполнения первого попавшегося запроса я думаю смогу секунд за 30, что называется кто быстрее :)))). А найти план выполнения нужного запроса из пары десятков в логах выполнения ТЖ мне почему-то кажется занимает дольше двух минут 🙂
(19) Gilev.Vyacheslav,
…из SQL Profiler удобно использовать для анализа и оптимизации «узких мест» в больших «многоэтажных» запросах…
извините за прямоту…
Извиняю, но Вячеслав, вы при цитировании опустили принципиальную часть моей фразы, которая искажает ее смысл.
Я могу с легкостью из нее убрать ссылку на SQL Profiler (она не потеряет смысла и останется верной), а суть ее сводится к тому, что план выполнения запросов МОЖЕТ(!) хорошо помочь в решении задачи оптимизации больших запросов. И повторюсь, что мне без разницы каким способом я получу нужный мне план выполнения запросов в следующий раз — будет ли это Profiler, ваш сервис или логи ТЖ.
// offtop
Какой, простите, вырвиглазный сайт. Сделайте меня развидеть это!
(36) , (37) , (38) , (39) krolya, Алексей, по существу статьи — можно было откинуть про инструментарий и написать :
берем жирный запрос, смотрим на левую и правую части соединения,
смотрим на скорость правой части, смотрим на скорость левой части, смотрим на скорость «обоих частей вместе» — далее смотрим кто из них самый явно долгий,
далее «проваливаемся вглубь» этого долгого и повторяем итерацию
таким образом какой бы не был огромный запрос, не обязательно мегасхемы рисовать, можно автоматизированно локализовать узкое место,
я не прав?
ценное зерно (не ходившим на 1С:эксперта) в статье про нехватку отборов при перемножении — не буду придираться
у меня ваша заметка вызвала такую реакцию потому что напоминает софтпоинтовое «много воды и чуть-чуть полезного»
вообщем вцелом не обращайте на мое ворчание внимание, ваша статья найдет своего благодарного читателя, профайлером тоже надо уметь пользоваться
(41) Gilev.Vyacheslav,
берем жирный запрос, смотрим на левую и правую части соединения,
смотрим на скорость правой части, смотрим на скорость левой части, смотрим на скорость «обоих частей вместе» — далее смотрим кто из них самый явно долгий,
далее «проваливаемся вглубь» этого долгого и повторяем итерацию
Вячеслав, согласен, но тогда это будет не та статья, которую я задумывал :), т.к. я хотел показать весь путь оптимизации одного запроса от начала и до конца. Если в статье доносить только главную мысль «без воды», то она не будет воспринята (хотя возможно я не прав в этом).
ОК. Договорились 🙂
(0) перечитал спокойно, хотя хотел в пылу написать с утра.
Возникли следующие мысли:
1. Знать и уметь использовать профайлер вкупе с методом ПолучитьСтруктуруХранения() — НУЖНО
2. В реальной работе лучше использовать ИнструментыРазработчика, КонсольЗАпросов и КонсольКода с трассировками, не забываем про EnterpriseIntegrator от Германа.
3. APDEX и ЦУП знать нужно — но это инструментарий который вначале нужно внедрить, а только потом использовать.
Однако меня больше заинтересовало другое:
Решение – добавить новое условие в ВЫБОР КОГДА по новому виду показателя.
совместно с вот этим
Я правильно понял, что когда другой разработчик добавит новое значение показателя ПоКакимНибудьНовымДаннымСотрудникаИлиВЗависимостиОтФазыЛуны — проблема вновь возникнет ? И тогда придется повторно вспоминать данный кейс.
Если я все правильно понял, то это не решение — это HOTFIX.
Нужно избавится от конструкции ВЫБОР внутри условия соединения и тогда я думаю будет еще чуть быстрей за счет отказа от CASE подобных конструкций и в будущем не рухнет вновь.
(43) lustin,
Алексей, спасибо за комментарии.
Правильно, но этого не будет — см. ниже 🙂
Предыдущие разработчики добавили новый вид перечисления, что я считаю некорректно, я практически уверен что задачу, которую они решали можно было реализовать либо используя типовые механизмы либо минимально корректируя существующие. По крайней мере не влезая в корректировку перечислений, так как в коде типовых ОЧЕНЬ ЧАСТО перечисления обрабатываются структурой ЕСЛИ … ИНАЧЕ ЕСЛИ … КОНЕЦЕСЛИ;. И изменение списка значений для перечисления приводит к масштабным изменениям по всему коду конфигурации.
Поэтому совсем правильным вариантом я считаю будет — провести рефакторинг изменений, которые привели к необходимости корректировки этого перечисления и оставить типовой код запроса :), но так я думаю никто сейчас делать не будет.
А чтобы избавиться от конструкции ВЫБОР, это нужно проводить рефакторинг кода этого запроса и корректировать типовую, что во-первых, накладно, а во-вторых соотношение полученного результата (ускорения) к стоимости его достижения мне кажется будет не в его пользу. Т.е. не стоит оно того имхо 🙂
(14)(17) Раз уж все отметились, вот интерактивный!!
(45) В чем его интерактивность? Он может выполнять по шагам операции плана? =)
(44) ну значит я с Hotfix’ом угадал. А вот про типовую я забыл.
Скорее всего ты прав — необходимо посмотреть где им не хватило типовой и зачем и тогда рефакторить (причем может быть даже процессы а не конфигурацию).
(46) пока при наведении расшифровка, при клике на таблице переход к , на остальное пока особо фантазии не хватило 🙂
В общем там чистый HTML, можно хоть скачущего ПОНИ прилипить
(20) Gilev.Vyacheslav, ЦУП — це круто. Нет, ну правда. Хорошо когда есть деньги. Тогда не сильно задумываешься на тему: «А как дальше жить». Но у многих их нет. И живут же они как-то. Просто они немного больше думают (делают). Так и здесь. Хорошо когда заказчик купил КИП, да еще и на сервере терминальном открыл доступ в интернет. А вот когда не открыл и не купил? Да еще и ТЖ поднимает сам по служебке через неделю? После пары таких клиентов и бинарники становятся исходниками. Просто работа моя увеличивает время и стоимость. Наверное, КИП и ваш сервис будет дешевле (даже не наверное, а скорее всего). Но жадных — надо учить рублем.
А не смутило сразу, что TABLE SCAN используется? Может, стоило бы для начала помочь оптимизатору?
(50) Sorm,
Я в первую очередь разбирался с ошибками, которые потенциально дешевле в устранении. Принцип Парето работает безотказно — 80% торможения можно устранить за 20% затрат. Мне в тот момент гораздо выгоднее было разобраться с 2 млн строк, чем устранять table scan 🙂
(51) krolya, Проиндексировать эту таблицу вместо анализа запроса(анализ, конечно, правильней, не спорю) не проще был сначала попробовать? Как бы это первое, что приходит в голову.
(52) Sorm,
Сложно судить, но мне почему-то как раз пришло в голову именно с таблицей разобраться, чем пытаться помочь с TABLE SCAN’ом )
Интересно как другие думают? 🙂
(52) Sorm, зачем ускорять «ненужную» работу, лучше ее минимизировать как (53)
(54) Gilev.Vyacheslav, согласен, но здесь вопрос во времени. Разобраться в запросе всяко дольше, чем индекс привинтить. А с учетом индекса, возможно, нагрузка на сервер станет непринципиальной. Ну, это только мое мнение. Просто часто разбираюсь с большими сложными SQL-процедурами, в которых «годичные» наслоения кода. Первый метод — все что можно выносится во временные таблицы, индексируется.. ну и т.д. Второй — сидеть разбираться в процедуре применительно к данным.
(55) Sorm,
Первый метод: крайне трудоемок для громоздких запросов и не факт что приведет к нужным результатам.
Второй метод: анализ самих данных я не использовал на первом этапе «широкого» поиска, а только на более позднем, когда я сузил область поиска некорректного кода до 1-2 запросов.
(56) krolya, «Первый метод: крайне трудоемок для громоздких запросов» — собственно, почему? Уточню — я имею в виду хранимые процедуры и функции.
(57) Sorm,
Долго придумывал какую аналогию привести, чтобы обосновать свое решение. Пришла в голову следующая идея:
по-большому счету любую операцию можно рассматривать как V=f(P,T), где V объем, т.е. количество выполненных операций за все время, P производительность, т.е. скорость выполнения этих операций в единицу времени) и T время затрачиваемое на работу, т.е. общее время выполнения операции. Предположим (для упрощения, но можно проверить и составить реальный график по реальным данным) график будет линейным (V=P*T).
Предположим, что у нас на начальном этапе скорость обработки данных — 100 единиц в единицу времени, а объем необходимый для производства равен 100 000 единиц (у нас цифры были другие 2 млн строк и 2 минуты), тогда время которое необходимо затратить, чтобы произвести (обработать) 100 000 единиц — 100 000 / 100 = 1000 единиц времени.
Двигаемся дальше — скорость оставляем НЕИЗМЕННОЙ, а значительным образом уменьшим количество записей до 1000, тогда время будет равно 10 единицам, а теперь подумаем во сколько раз нам нужно увеличить скорость выполнения операций при НАЧАЛЬНЫХ условиях объема 100 000 и заданном времени T=10, скорость выполнения операции должна стать 10 000, т.е. вырасти в 100 раз (математика первый класс :)))).
Ну, а в нашем случае, у нас было 2 млн. строк и я планировал его уменьшить до 2000 примерно, соответственно скорость выполнения нужно было увеличить в 1000 раз, чтобы получить сравнимый прирост 🙂
С моей точки зрения, я мог с высокой степенью гарантии уменьшить количество записей до 2000, но получить прирост в 1000 раз при добавлении индекса — я получил бы вряд ли.
P.S. Я проверю это на каком-нибудь SQL и выложу результаты. Самому интересно 🙂
Здесь был комментарий 🙂
Автору спасибо за известную методу, но можно все проще сделать (я сейчас о конкретно в этой статье описанном случае), без всяких профайлеров, если знаешь текст проблемного запроса, берешь любую консоль запросов, либо допиливаешь, либо готовую с расчетом времени выполнения каждой ВТшки, и с вероятностью 90% самый долгий по выполнению Пакет и будет проблемным, и тут уже либо менять БизнесЛОгику запроса для оптимизации, либо чисто технически оптимизровать пакетник. для большинства пользователей, чтение планов запроса не даст полезной инфы, подумаешь table scan, подумаешь nested loops, и т .п.
(60) unoDosTres,
вдогонку к своему посту, скрин проблемного запроса из консоли запросов, и сразу видно что проблема в отмеченной Втшке, по-моему удобней и быстрей для описанного в теме случая, ну или хотя бы достойная альтенатива, конечно такого глубокого анализа как из плана запроса не получить, но узкое место сразу как на лодони
(61) unoDosTres,
Да, разумная альтернатива и ее бы хватило для этого случая, по идее можно еще и количество строк смотреть — потому что у меня проблемный запрос не был самым долгим, но он влиял на другие. Так что анализ по количеству строк + время выполнения вполне себе пристойный инструмент для анализа запросов.
Ну и еще одна тонкость — иногда бывает достаточно сложно собрать все кусочки в единый запрос.