
Когда при подключении к базе MS SQL появляются ошибки:
Ошибка СУБД:
Microsoft OLE DB Provider for SQL Server: Журнал транзакций для базы данных «ReportServer» заполнен. Чтобы обнаружить причину, по которой место в журнале не может быть повторно использовано, обратитесь к столбцу log_reuse_wait_desc таблицы
sys. databases HRESULT=80040E14, SQLStvr: Error state=2, Severity=11,native=9002, line=1
или
Ошибка СУБД:
Microsoft OLE Provider for SQL Server: The transaction log for database “ReportServer” is full. To find out why space in the log cannot be reused, see the log_reuse_wait_desc column is sys.database
HRESULT=80040E14, SQLSTATE=4 2000, native=9002
это значит, что на диске, где расположен лог транзакций закончилось место и теперь СУБД некуда записывать данные о новых транзакциях. Чаще всего такое происходит, когда не установлено никаких ограничений на размер лога и в MS SQL не создано соответствующих планов обслуживания.
В таком случае нужно уменьшить размер самого файла транзакций (*.ldf), другими словами сделать шринк (сжатие) лога. Для этого можно использовать как запрос, так и сжатие лога вручную.
Рассмотрим сжатие лога транзакций вручную:
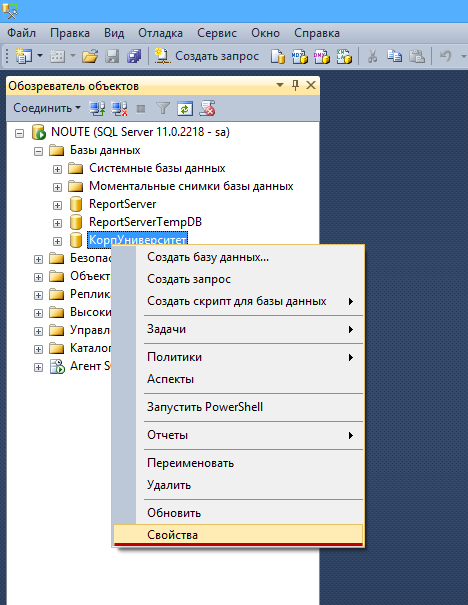
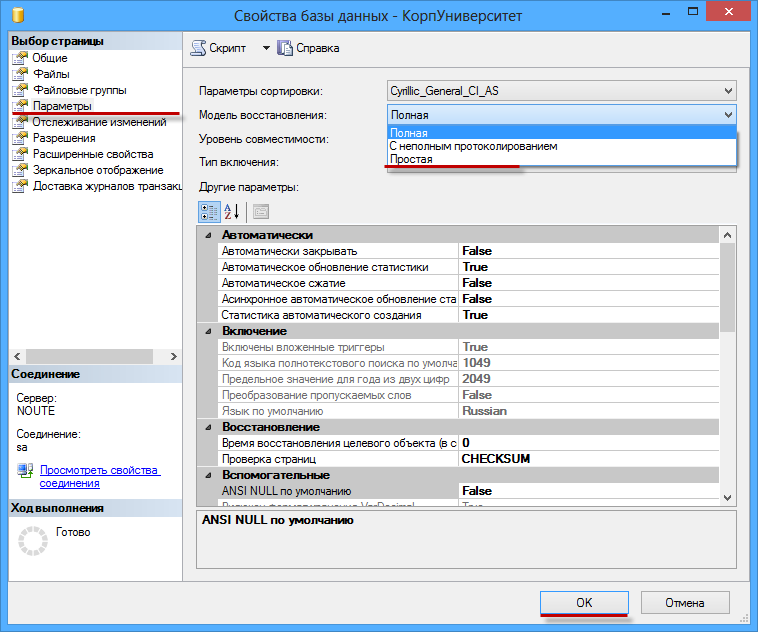
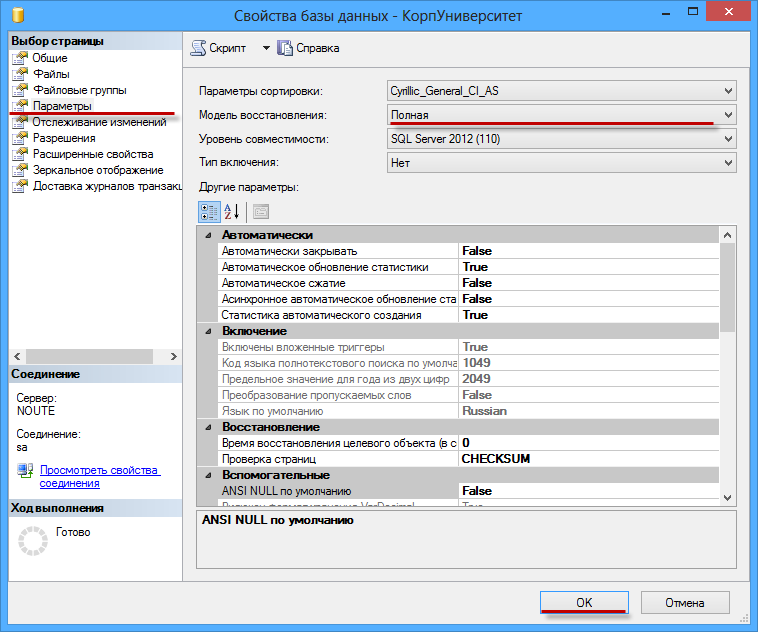
Шаг 1. Установить модель восстановления Простая (Simple). Правой кнопкой на базе — Свойства(Properties) — Параметры(Options) — 4-й сверху пункт Модель восстановления(Recovery model) — Простая(Simple) — OK.
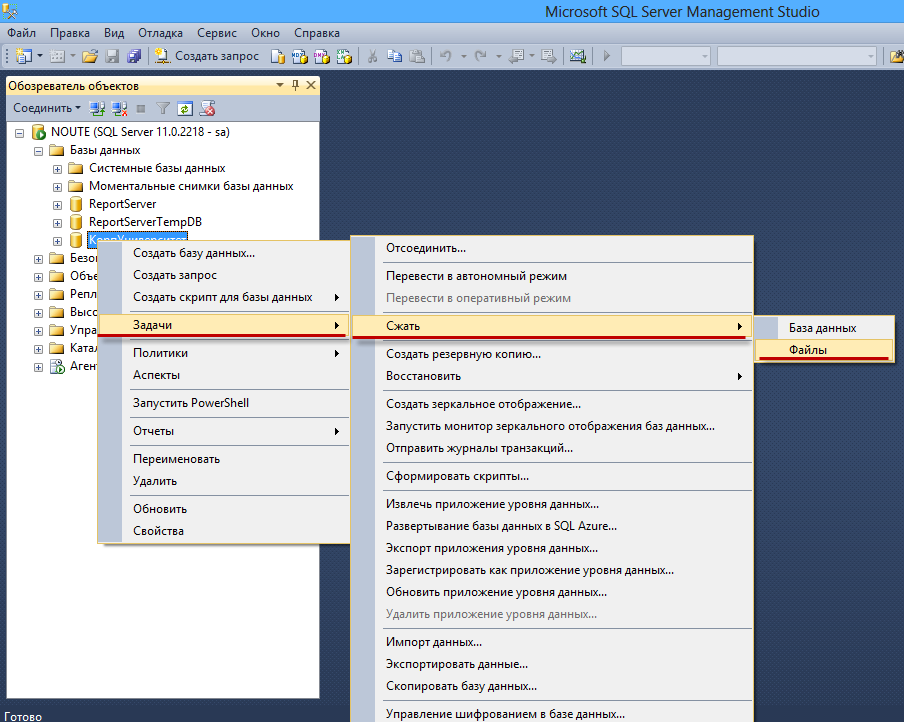
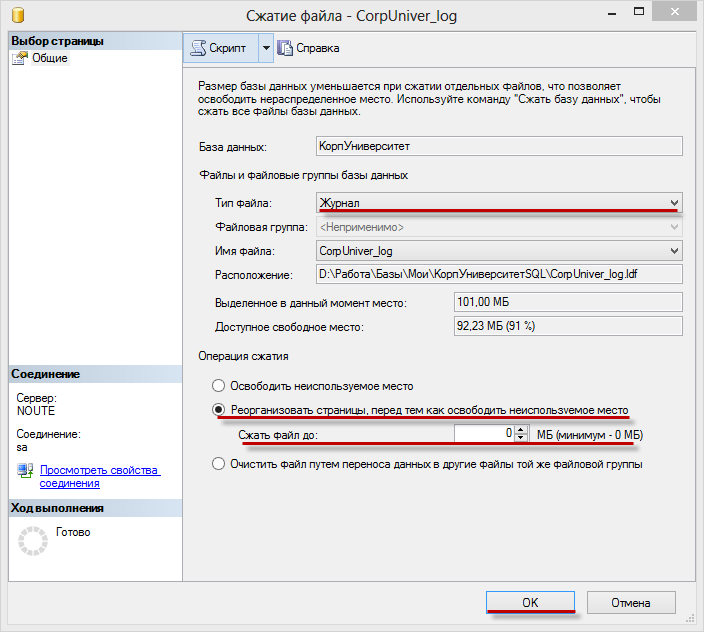
Шаг 2. Выполнить шринк (сжатие) лога транзакций. Правой кнопкой на базе — Задачи(Tasks) — Сжать(Shrink) — Файлы(Files) — установить Тип файла(File type) — Журнал(Log) — в Операция сжатия(Shrink action) — выбрать Реорганизовать страницы, перед тем осводить неиспользуемое место(Reorganize pages before releseasing unused space) — Сжать файл (Shrink file to) —
указать приемлемый размер лога.
Шаг 3. Установить модель восстановления Полная(Full). Правой кнопкой на базе — Свойства(Properties) — Параметры(Options) — 4-й сверху пункт Модель восстановления(Recovery model) — Полная(Full) — OK.
P.S.: В данной статье даны рекомендации для решения конкретной проблемы. Настройка самого MS SQL здесь не рассматривается!
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
(0) а зачем возвращать в состояние «Полная»?
Можно оставаться на Простой и рассчитывать только на бэкапы.
(1) Полная более гибкая. А для больших баз еще и быстрая: с одной стороны можно обеспечить маленькие интервалы восстановления, с другой быстрый бэкап в рабочее время.
Еще бы автор написал, для чего вообще нужна данная процедура )
(3) batan, данная процедура нужна в том случае, если логи сильно разрастаются. Было у меня на практике, когда нерадивые сисадмины не следили за логами и они разрастались до размеров нескольких сотен ГБ (240 Гб если быть точным, был и в 70 Гб). Поэтому и приходилось выполнять такие манипуляции.
Читайте плз документацию к БД она не просто так писана — если бы мог, поставил бы минус публикации — есть стандартные процедуры с бекапом и обрезкой лога.
а то что написано можно делать только на базе без подключенных пользователей — хотя зачем это нужно?? если можно обойтись стандартной процедурой в одну строчку мссиквела.
кому интересно — тот хотя-бы на sql.ru поищет.
(2) aspirator23,
Полный бред! Не видела ни разу ни одной фирмы, где в течение дня начинали восстанавливать бакап, а потом еще пол-дня чесали репу, какие доки/транзашки были сделаны, а какие нет(учитывая, что 30-50тичисленное стадо манагеров постоянно разбредается и никого не собрать по тубзикам-курилкам, чтобы выяснить где был реал-тайм).
Выводы: простой режим восстановления, ночной бакап + в обед, если уж так плющит(видела в одной конторке, где сотрудников принудительно выгоняют на хавчик из офиса и базы) и получасовые снапшоты, если уж совсем фобия.
(5) То что написано делается без «выгоняния» пользователей.
(6) Попробуйте поработать с большими базами данных. Тогда и опыт появился бы и понимание как это работает.
То что вы не видели, не означает, что у всех также.
делаем то же самое. работает на 100%. Выгонять пользователей не нужно. Место на диске за 3 минуты освобождается.
На одной из картинок в параметрах есть такое свойство как «автоматическое сжатие = FALSE».
А почему сразу его не поставить в TRUE? И забыть про все вышеописанное?
Вредительская статья. Уходить на простую модель без предварительного полного бэкапа — мягко говоря опрометчиво. Ну в общем то и формулировка задачи странная. Проще 1 раз настроить задания по созданию бэкапов и обрезанию логов (о боже с запросами, да да) и забыть об этом.
Автор забыл добавить что после обратного перехода на полную модель нужно собственно сделать полный бэкап, так как он предыдущими действиями прервал цепочку восстановления, соответственно если есть задания по бэкапу оно не будет выполнятся, пока не пройдет новый фул бэкап.
Метод описанный в статье имеет право на жизнь, но лучше все изначально грамотно спроектировать, что бы проблема с «внезапно» выросшим журналом не было в принципе.
Идея неплоха, но в заголовке статьи не хватает надписи «в экстренном случае» или «когда штатные средства не позволяют»
Действительно, бывают запущенные ситуации, когда с логом уже ничего сделать нельзя (ни бэкап, ни шринк).
Я правильно понимаю, что эта операция поможет в случае, когда на диске уже почти не осталось свободного места?
(2) aspirator23, Полная модель восстановления — обеспечивает восстановление «с точностью» «до минуты» (имею ввиду из бакапа), но это приводит к тому что разрастается лог (часто он занимает весь диск, и база «останавливается»), Простая модель — позволит восстановить информацию только на момент создания бакапа, никакого (почти) влияния на скорость работы эти модели не имеют (полная модель теоретически медленнее — т.к. при её использовании делается множество «лишних записей» в лог, в отличие от простой модели). подробнее тут . Поэтому предпочтительно использовать именно простую модель, с каждодневным бакапом (в наиболее ненагруженное пользователями и фоновыми заданиями время), и с регулярным автоматическим шринкованием, через планы обслуживания СКЛ (кстати использование планов обслуживания 2008/2012 также позволяет «без написаания запросов», производить гибкие настройки многих вещей, в частности бакапов и шринков, да и много чего еще). вот тут еще инфа есть про бакап
(13) Важное замечание сделал(11).
1.Насчет того что «разрастается лог, который часто занимает весь диск» — это не обсуждаем.
SQL сервер тоже нужно настраивать, а не просто поставить по умолчанию.
2.»предпочтительно использовать именно простую модель, с каждодневным бакапом» — я уже писал, что простая модель хороша для небольших баз. А также в случае если требования по восстановлению
никто не заявляет. А вот если заявляет и база большая, то простой моделью не выкрутишься.
Либо не обеспечишь нормальную периодичность восстановления, либо если обеспечишь, то тогда база будет ложиться
в момент выполнения полного бэкапа при простой модели.
Я обычно делаю скриптом. Быстрее получается.
Также можно настроить выполнение по расписанию.
Показать
(14) aspirator23,
никто не заявляет.
Простая модель хороша для любых баз (и больших и не больших), если нет требований по восстановлению на любой момент времени.
(9) dvv01, можно даже настроить, чтобы с логом вообще проблем не было, но в данном примере рассмотрено как это можно сделать просто и быстро
(12) bforce, дельное замечание по-поводу названия. Да, когда места нет, а его нужно срочно освободить.
(11) Babuin, по-поводу полного бэкапа добавлю. А вот насчет настройки — это отдельная тема. Я лишь показал, как по-быстрому место освободить. У самого базы висят и все настроено. Так что настройку тут не рассматриваю.
(15) ixileon, можно скриптом. А можно как и у меня. Тут кому как удобнее.
без предварительного выяснения, почему увеличился размер transaction log,
нет смысла его усекать. втом числе и автоусекать.
У меня база 90 Гб. В режиме Siple, ибо то что делают юзеры и программеры с базой часто в модели Full увеличивало базу раз в 5. Даже в Siple модели лог увеличивается, если есть большое количество изменений (15-30 Гб бывает).
Для откатов, делаете дифференцированные бекапы базы в продолжении для (периодичность скажем час) и всё что нужно есть.
Шринк да базе 90 Гб при полной модели при робочих юзерах (лог файл 50-150 Гб) нивжизнь не пройдёт, или будет делаться очень долго. Так как при полной модели в основной базе ещё нет изменений, которые хранятся в лог-файле, а если юзера работают с данными, изменения по которым должны быть записаны… Ну и немаловажный факт — количество юзеров. У меня их за 100 одновременно работающих. Транзакции никто таки не отменял…
Как одноразовая мера, чтобы если база выжрала всё место на диске и отказывается работать, вполне оно. Все равно никто работать уже не будет. Тогда да, это самый эффективный вариант.
На хера ReportServer 1С?
как раз такая ситуация пришла. База была брошена, франчи установили, уехали и никому до неё не было дела — никакого бэкапа — так иногда только DT-шники выгружали и то когда вспомнят. НО после проведения реиндексации реструктуризации лог вырос до 300 ГБ при базе в 45 ГБ. и почти кончилось место на диске.
причем реально база 19,5 ГБ в локальной файловой копии.(45 ГБ стала после загрузки в существующую DT-архива — может подскажете как правильно вернуть назад???).
Сделал все как в статье (не стал БЭКАП делать ибо некуда. ограничился выгрузкой в ДТ-архив.) при неработающих пользователях. размер указал 30 ГБ. Шринк прошел очень быстро. Щас настраиваю планы обслуживания (пока на тестовой базе) и ставлю вопрос о приобритении винта специально под бэкапы.
Но у меня такой вопрос
Вроде установил модель обратно в FULL, но даже сделав реиндексацию таблиц после этого размер журнала не изменился. и мало того уже рабочий день заканчивается — куча проведеных документов была, но размер какой был такой остался и дата изменения не изменяется (последние изменения базы — 0:22 — ночью в базе никто не работает кроме меня:) а лога аж 22 числа, т.е. 2 дня назад) — у меня установлено автоувеличение лога на 200 Мб, а базы на 500 МБ, может быть дата изменения меняется только во время увеличения размера.
Хотя после реиндексации размер лога должен был увеличиться на 25 ГБ (так было до шринка) — может кто нибудь разъяснить почему лог на месте стоит? — планы бэкапов еще не подключал т.е никакого архивирования нет.
(23) echo77, не захотел создавать тестовую базу вот на ней и показал. Действительно, нужно будет изменить скрины.
Есть не самый простой и быстрый, но очень надежный рецепт усечения «пустого» (т.е. данных там нет но файл не уменьшается) файла ldf. Применяю когда ничто другое не помогает. Правда если изначально (при создании базы) файл был создан определенного размера, то этот способ тоже не поможет.
Рецепт простой:
//начинаем транзакцию
BEGIN TRAN
GO
//делаем апдейт какого нибудь поля какой нибудь большой таблицы
UPDATE ….
GO
//отменяем транзакцию
ROLLBACK
GO
После этого файл можно усечь на размер заполненных данных в файле ldf.
Рецепт используем столько раз, сколько потребуется.
Зачем используете ПОЛНУЮ модель, если шринкуете транзакционный лог? НУ да ладно это другая тема, а по этой можно просто выполнить запрос (Для примера имя БД «Base»):
Затем файл с логом можно удалить, либо перенести на другой диск/сервер
Спасибо автору реально помогло. Такой вопрос а где можно почитать по поводу настройки SQL сервера поделитесь ссылками )))
Вчера столкнулись с проблемой большого лога. Спасибо автору, статья полезная. Мне не понятно одно, 1С Сервер может вопрос логов как-то регулировать?
(29) FKLDOZ,
1С вообще практически ничего не может на SQL. SQL-сервер — он сам по себе, и сам управляет своими логами.
(5) caponid,
если про «Усечь журнал транзакций» в 2012 — то он не всегда отрабатывает. А лог нужно урезать обязательно.
(5) caponid,
С пользователями делается.
(1) adhocprog,
Когда у вас будут вводить по десятку документов в секунду, тогда и оцените восстановление на любой момент времени.
(9) dvv01,
А потому, что принудительно лог очищается ВСЕГДА. А не как придется в случае автошринка при выгрузке.
А есть случаи, когда нужно обрезать только лог, без бэкапа…
(14) aspirator23,
Отчего же не обсуждаем? Вы знакомы с проблемой «база загружена не полностью» и её причиной?
(21) МихаилМ,
нет смысла его усекать.
как бы работа самой базы? Наставляемые обновления? Изменения в конфе? Нет?
Это все не приводит к увеличению лога?
Из всего сказанного и из комментариев я что то не совсем понял. Если мы используем полную модель восстановления, сделали полный бэкап, обрезали лог базы, и если вдруг понадобиться восстановиться из бэкапа, то ничего не получиться?
(33) qwed557, поддерживаю!
(33) qwed557,
все получится — восстановится на момент бекапа полностью.
Полная же модель подразумевает — восстановление на любой момент времени, что невозможно, если данные транзакций уничтожены (лог транзакций стерт). Поэтому его в таком случае не трут, а также бэкапят вместе с базой. Но это именно для тех, кто понимает, что ему нужно. Для остальных — SIMPLE режим 🙂
(33)
При полной модели восстановления бэкапы делаются так часто как это возможно для того чтобы процесс восстановления начинать не с испокон веков существования базы а с последнего полного созданного бэкапа + далее накатывают после этого бэкапы логов транзакций. это очень удобно хотя на практике приходилось пользоваться всего пару раз в жизни. У нас например это раз в неделю по четвергам (самое оптимальное время исходя из всех регламентов скуля + сервера 1С).
При простой модели вы сможете восстановить базу только на момент последнего созданного бэкапа.
Если у вас есть нормальное ПО по управлению бэкапами и логами ТЗ (хотя все это можно написать и на SQL) то делается просто.
Полная модель. Создается бэкап базы, хранится, далее бэкапятся логи раз в нужное вам время у нас это 15 минут, логи тоже хранятся, но каждый раз когда проходит полный бэкап базы НОРМАЛЬНО все старые бэкапы базы и логов трутся и начинается новый отсчет времени. Ну и так же настроено месячное хранение базы полугодичное и годовалое которые хранятся отдельно и трутся соответственно когда создаются подобные бэкапы.
При полной модели и наших настройках мы можем восстановить базу максимум с недельной давностью, далее все остальное накатить логами.
Так же мы можем восстановить базу на начало месяца, начало полугодия и начало года но уже без логов транзакций.
Насчет тормозов не могу согласиться с предыдущими ораторами о том что простая модель работает быстрее, они работают одинаково если нормально настрое сервер SQL, просто лог транзакций должен по умолчанию лежать на другом зеркале, отдельно от того зеркала где располагается база. Много раз проверяли что так что так работает одинаково. Если же логи транзакций лежат на том же массиве что и база — безусловно будет работать медленнее.
Статья очень помогла, и комментарии. Спасибо!
(15) А как в автомате по всем базам.. т.к. баз за 100 ню?
Спасибо! Очень помогло!!! Очень подробно и доходчиво, так. что имея 0 знаний по SQL базам — очистил место за счет логов старых баз. Благодаря комментариям понял зачем все это надо!!! И если б не «А вот насчет настройки — это отдельная тема» разобрал бы это г…. — при базе менее 3 ГБ размер лога уже превышает 700 ГБ!!!
Т.е. если сделать выгрузку через конфигуратор и грохнуть эти 700 Гб, то можно спать спокойно? Или сделать полный бэкапп нужно средствами SQL?