



Основное назначение метода, это поиск неоптимальных запросов к MS SQL. Приложив немного усилий по модификации кода, мы получили инструмент позволяющий в любой момент ответить на вопрос: "что и когда тормозит?"
Суть проста: в каждый запрос 1С добавляем текстовое поле с идентификатором. Можно использовать строкового (например, КодИБ_ИдЗапроса) или для уменьшения объема генерируемых данных использовать числовые идентификаторы (необходимо иметь таблицу соответствий: код – описание запроса). Запрос с идентификатором будем называть помеченным запросом. Для удобства мониторинга, желательно идентификатор делать первым полем в запросе. При оптимизации «тяжелого» запроса рекомендую изменять идентификатор.
Это просто пример,
З = Новый Запрос(«ВЫБРАТЬ
| «»ЭтоНашИдентификаторЗапроса_версии1″» КАК Поле1,
| Номенклатура.Ссылка
|ИЗ
| Справочник.Номенклатура КАК Номенклатура
|ГДЕ
| Номенклатура.Наименование = &Наименование») ;
Теперь мы можем «родными» средствами статистики MS SQL проводить анализ и мониторинг постоянно в реальном времени, причем комплексно – сразу по всем базам на сервере. На рисунке ниже выделен запрос до (_2) и после оптимизации(_4).

Сам я использую свою обработку //infostart.ru/public/145342/, в которой вы можете найти отчет «Нагрузка на сервере БД» который сообщит, вам какие запросы нагружали сервер больше всего за последний час работы. Период можно изменить в макете «НагружающиеЗапросы»: set @hours = 1; .
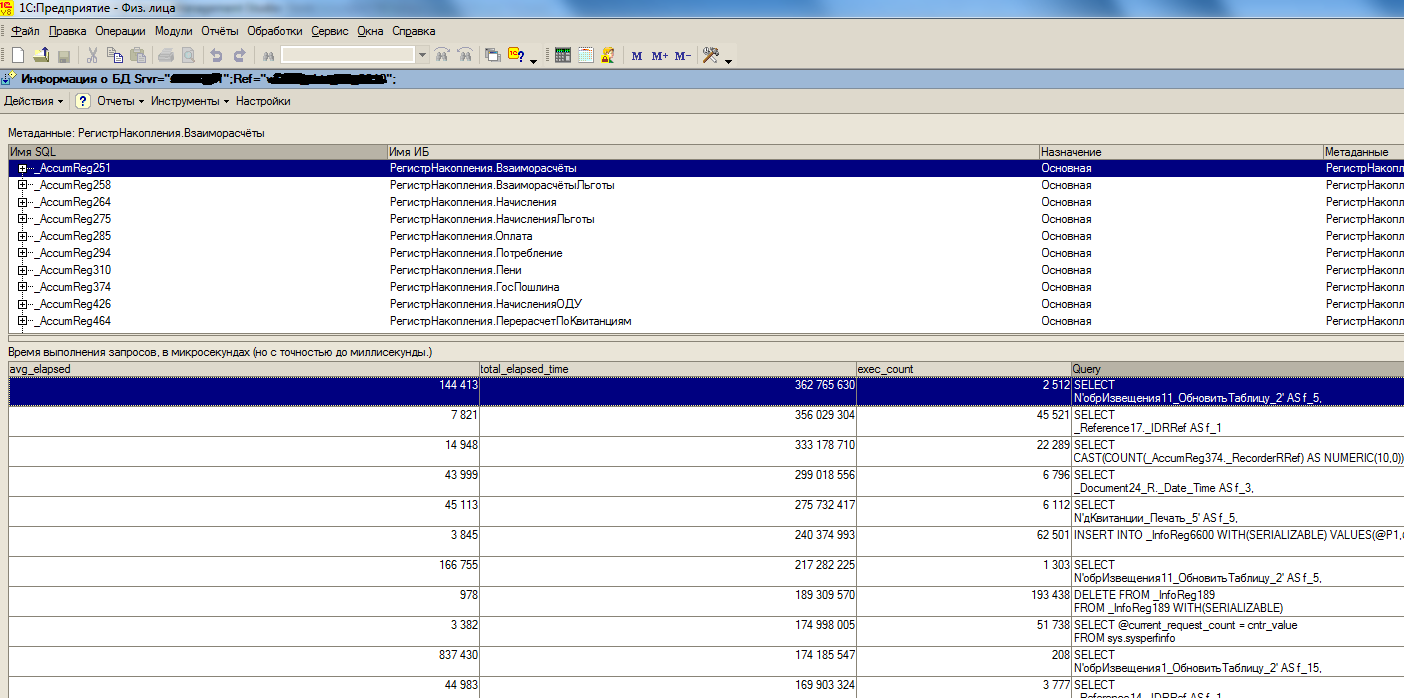
avg_elapsed – среднее время на выполнение плана запроса
total_elapsed_time – общее время затраченное на выполнение плана
exec_count – количество выполнений плана
К сожалению, в данном методе мы не можем пометить некоторые запросы, например, генерируемые 1с при работе с объектной моделью (к счастью, они обычно просто определяются). Так же некоторые проблемы доставляет компилятор запросов, генерируя из вложенных запросов пакеты, но от этого можно избавиться, переписав сложные запросы или помечая эти подзапросы. Главный из минусов это сложность обновлений модифицированных запросов.
Для автоматизации идентификации запросов можете исппользовать обработку (черновой вариант):
- выгружаем файлы конфигурации в каталог
- запускаем обработку, указываем в ней каталог куда выгрузили, жмем загрузить и выполнить
- двойной клик мыши на записи отображает сравнение файлов
- загружаем файлы конфигурации, корректируем
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Где картинки? не видно.
Ссылка на список Ваших публикаций…
Эта обработка: ?
Вопщем все запросы надо перелопатить в итоге вручную, т.е. добавить эти идентификаторы? Автоматом никак нельзя это сделать?
(3) serega3333,
В 8.3 штатно разложить на составляющие тексты их программно модифицировать и собрать обратно.
Только не забыть про временные таблицы в запросах.
(4) а новая эта фишка в 8.3, понял, спасибо!
(3) serega3333,
Сейчас пытаюсь создать инструмент для автоматизации этой задачи. Идеи и предложения очень приветствуются.
Идея для всех версий платформы:
1 Сохраняем конфигурацию в файл, ее будем далее использовать для обновления и поддержки
2 В конфигураторе выгружаем модули
3 Обработкой помечаем запросы
4 Загружаем модули
5 Обновляем конфигурацию базы
6 Мониторим и оптимизируем
7 Все лучшие наработки переносим в сохраненную конфу
«Простой способ» не очень уж и простой
(6)
Предлагаю три режима:
1) весь пакет метить одной меткой с последующим суммированием времен выполнения;
2) каждый самостоятельный запрос отдельно;
3) каждый подзапрос и каждую часть запроса в «объеденить».
Делаешь через ТекстЗапроса = Заменить(ТекстЗапроса,,) или через непосредственное редактирование текста?
(7) Ага, замер производительности ещё никто не отменял 😉
(9) AHDP,
Как вы определите тормоза в высокочастотных запросах на базе с большим количеством пользователей?
Я ни одним инструментом кроме профайлера SQL не смог определить, что базу тормозят именно высокачастотные (вроде быстро работающие, но очень часто вызываемые), а не которые долго выполняются. Методика оптимизации
от 1С с их КИП в данном случае мне кажется бесполезной. Для работы с тех. журналом требуются нехилые ресурсы и навыки.
(10) Для работы с техножурналом на самом деле уже немало средств реализовано.
В я постарался обеспечить высокий уровень удобства работы с техножурналом. В частности высокочастотные запросы там также можно быстро обнаружить (есть свертки по текстам запросов с вырезанными параметрами и по строкам исходного кода). Также у Гилева есть свой . Также у german есть с профайлером.
(11) tormozit,
Да, инструменты есть и не плохие. Однако, у большинства из них по моему мнению, есть один минус — накопление данных. Для примера, я не знаю как эффективно с помощью них круглосуточно выявлять проблеммные запросы в работающей базе с больщим количеством запросов и выявить динамику в течении часа, суток, месяца и т.д.
У всех методов есть плюсы и минусы. Имхо, тех. журнал это не тот инструмент которым можно полноценно мониторить базы.
(12) Техножурнал не есть конечный инструмент. Это лишь средство для журналирования важный событий. Имхо только через него и можно универсально мониторить базы, используя конечный инструменты.
(8) AHDP,
>Делаешь через ТекстЗапроса = Заменить(ТекстЗапроса,,) или через непосредственное редактирование текста?
Мы пока все вручную. Помечаем только запросы которые мы изменяем или создаем,
в дефолтные запросы от поставщиков стараемся не трогать, что бы не создавать себе дополнительных проблем с обновлениями. Про режимы не понял.
(13) tormozit,
Вот именно — это журнал событий, а не монитор. Появился он как побочный продукт разработки 1С.
(10) Моя позиция такова, что оптимизировать нужно в первую очередь пиковую нагрузку. С запросами которых много и они быстро выполняются проще бороться мастабированием железа — гарантирована стоимость, сроки и результат.
(14) Это я для автоматического добавления в запросы меток. Например в пакете несколько запросов с приемлемым временем исполнения, а сам пакет ну никуда не годиться. Хочется иметь возможность увидеть всё время выполнения пакета и каждого запроса в отдельности.
(12) Есть инструмент PerfExpert от softpoint.ru.
Позволяет накапливать данные и возвращаться к проблемному интервалу времени для анализа.
Минус — платная. Сами пользовались? Какие впечатления?
UPD Добавил к статье обработку для выставления идентификаторов.
(16) AHDP,
Не всегда можно это сделать с помощью железа: ограниченый бюджет, сроки ну и достижения предела по ресурсу (например сетевой канал, скорость шины). Иногда лучше и дешевле изменить алгоритм работы.
Activity Monitor выдаёт:
SELECT
@P1
FROM _InfoRg34 T1 WITH(NOLOCK)
Все слова и цифры заменяет на @P1, а как вам удалось сделать чтоб писал по человечески вместо @P1 ?
(SQL SERVER 2008 R2)
(21) ManyakRus,
Ничего специально не далали, выдает по умолчанию. Возможо это 1С так делает (у нас 8.1)?
у меня 1C 8.2.16.352,
не получается так 🙁
Проверил, действительно в 8.2 константы передает как параметры — печалька.
Изыскания привели к созданию такого запроса:
Показать
Не знаю как это вяжится со стандартом SQL и как ситуация в других СУБД.
работают оба метода 🙂
(максимум и выбор)
Расставлю везде метки 🙂
SELECT
MAX(N’222′),
FROM _InfoRg34 T1 WITH(NOLOCK)
SELECT
CASE WHEN (N’111′ = N’222′) THEN N’333′ ELSE N’444′ END
FROM _InfoRg34 T1 WITH(NOLOCK)
Не получается идентифицировать таким образом запрос из СКД, похоже он модифицируется вообще в какой-то непонятный набор с кучей временных таблиц (.
временные таблицы не идентифицируются,
временные таблицы не идентифицируются,
а они тоже много пожирают,
в БД у них видимо команды инсерт вместо селект.