<?php // Полная загрузка сервисных книжек, создан 2026-01-05 12:44:55
global $wpdb2;
global $failure;
global $file_hist;
///// echo '<H2><b>Старт загрузки</b></H2><br>';
$failure=FALSE;
//подключаемся к базе
$wpdb2 = include_once 'connection.php'; ; // подключаемся к MySQL
// если не удалось подключиться, и нужно оборвать PHP с сообщением об этой ошибке
if (!empty($wpdb2->error))
{
///// echo '<H2><b>Ошибка подключения к БД, завершение.</b></H2><br>';
$failure=TRUE;
wp_die( $wpdb2->error );
}
$m_size_file=0;
$m_mtime_file=0;
$m_comment='';
/////проверка существования файлов выгрузки из 1С
////файл выгрузки сервисных книжек
$file_hist = ABSPATH.'/_1c_alfa_exchange/AA_hist.csv';
if (!file_exists($file_hist))
{
///// echo '<H2><b>Файл обмена с сервисными книжками не существует.</b></H2><br>';
$m_comment='Файл обмена с сервисными книжками не существует';
$failure=TRUE;
}
/////инициируем таблицу лога
/////если не существует файла то возврат и ничего не делаем
if ($failure){
///включает защиту от SQL инъекций и данные можно передавать как есть, например: $_GET['foo']
///// echo '<H2><b>Попытка вставить запись в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>$m_comment));
wp_die();
///// echo '<H2><b>Возврат в начало.</b></H2><br>';
return $failure;
}
/////проверка лога загрузки, что бы не загружать тоже самое
$masiv_data_file=stat($file_hist); ////передаем в массив свойство файла
$m_size_file=$masiv_data_file[7]; ////получаем размер файла
$m_mtime_file=$masiv_data_file[9]; ////получаем дату модификации файла
////создаем запрос на получение последней удачной загрузки
////выбираем по штампу времени создания (редактирования) файла загрузки AA_hist.csv, $m_mtime_file
///// echo '<H2><b>Размер файла: '.$m_size_file.'</b></H2><br>';
///// echo '<H2><b>Штамп времени файла: '.$m_mtime_file.'</b></H2><br>';
///// echo '<H2><b>Формирование запроса на выборку из лога</b></H2><br>';
////препарируем запрос
$text_zaprosa=$wpdb2->prepare("SELECT * FROM `vin_logs` WHERE `last_mtime_upload` = %s", $m_mtime_file);
$results=$wpdb2->get_results($text_zaprosa);
if ($results)
{ foreach ( $results as $r)
{
////если штамп времени и размер файла совпадают, возврат
if (($r->last_mtime_upload==$m_mtime_file) && ($r->last_size_upload==$m_size_file))
{////echo '<H2><b>Возврат в начало, т.к. найдена запись в логе.</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>'Загрузка отменена, новых данных нет, т.к. найдена запись в логе.'));
wp_die();
return $failure;
}
}
}
////если данные новые, пишем в лог запись о начале загрузки
/////echo '<H2><b>Попытка вставить запись о начале загрузки в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>0, 'last_size_upload'=>$m_size_file, 'comment'=>'Начало загрузки'));
////очищаем таблицу
$clear_tbl_zap=$wpdb2->prepare("TRUNCATE TABLE %s", 'vin_history');
$clear_tbl_zap_repl=str_replace("'","`",$clear_tbl_zap);
$results=$wpdb2->query($clear_tbl_zap_repl);
///// echo '<H2><b>Очистка таблицы сервисных книжек</b></H2><br>';
if (empty($results))
{
///// echo '<H2><b>Ошибка очистки таблицы книжек, завершение.</b></H2><br>';
//// если очистка не удалась, возврат
$failure=TRUE;
wp_die();
return $failure;
}
////загружаем данные
$table='vin_history'; // Имя таблицы для импорта
//$file_hist Имя CSV файла, откуда берется информация // (путь от корня web-сервера)
$delim=';'; // Разделитель полей в CSV файле
$enclosed='"'; // Кавычки для содержимого полей
$escaped='\










Здорово.
Я XMLSрy использую, но + за стремление
Люто плюсанул 🙂 Но позволил себе наглость чуть-чуть добавить функционала 🙂 Скрин и результат прилагаю…
Теперь можно и имеет смысл юзать почти все что угодно из например…
То есть, результат такой конструкции: ceiling(sum(//Товары//Сумма)) max(//Товары//Количество) можно увидеть в соответсвующем поле при выборе ТипРезультата=ТипРезультатаDOMXPath.Число … ну и с остальными вариантами также 😉
ЗЫ Еще раз спасибо за проделанный труд!
(2) German, XMLSpy оно ж не одинэсовское вроде? Просто какбэ реализации 1С разновсяческих API весьма своеобразное… Наталкивался на непонимания ряда функций и чудеса синтаксиса… Так-что лучше отладку делать нативно 😉
ЗЫ Еще бы регэкспы добавили нативно внутря — цены бы платформк не было 😉
(0) у меня вопрос это проблема реализации xpath в 1С, или ЧЯДНТ?
Пытаюсь выбрать все элементы Acceptance для которых подчиненный элемент имеет необходимый текст (значение).
xpath выражение не отрабатывает в обработке (8.2)
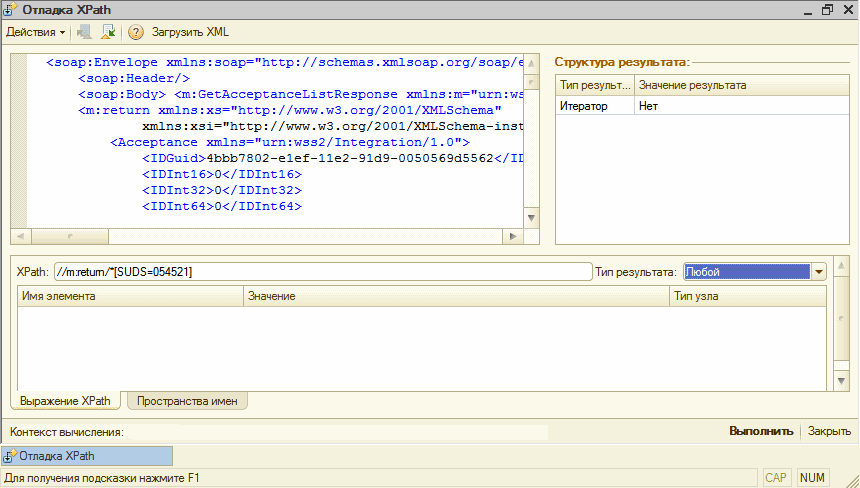
но работает в другом инструменте корректно (notepad++)

UPD: Запрос /soap:Envelope[soap:Header=»test»] работает. Скорее всего что-то связано с namespace атрибутов.
(5) xzorkiix, из скриншотов не видно — на что маппится префикс «m:». Соответствие префиксов и URI настраивается на второй закладке. Возможно, notepad++ умеет это делать сам.
(6) я выше подправил, вижу что для soap: который по умолчанию занесен в файл всё ок.
Все возможные ns в xml
<soap:Envelope xmlns:soap=»http://schemas.xmlsoap.org/soap/envelope/»>
<soap:Header>test</soap:Header>
<soap:Body> <m:GetAcceptanceListResponse xmlns:m=»urn:wss2/1SESL/1.0″>
<m:return xmlns:xs=»http://www.w3.org/2001/XMLSchema»
xmlns:xsi=»http://www.w3.org/2001/XMLSchema-instance»>
<Acceptance xmlns=»urn:wss2/Integration/1.0″>
Попробовал и вторую вкладку раскидать, но видимо ещё мимо. Не нужно ли здесь использовать Фабрику XDTO? (как в случае сервиса)
(7) xzorkiix, нет, фабрика не нужна. Если дадите сам файл и искомое выражение, могу посмотреть, но вечером.
аааа… стоп-стоп… похоже понял
У вас «пустой» префикс задан для пространства по умолчанию. в XPath по стандарту пустые префиксы не прокатывают. Назовите его как-нибудь, скажем «t» и все узлы «без префиксов» в выражении адресуйте, как «t:»
(8) Пустое, это уже была попытка угадать. Под фабрикой я понимал Пакет XDTO (это тоже была попытка угадать). Буду смотреть файл, если будут вопросы — побеспокою. А в целом ваше предположение мне кажется верным (о том что необходимо присвоить префикс всем вхождениям, где я произвожу поиск).
Спасибо.
(9) xzorkiix, это не просто предположение, а уже набитая шишка. Пустые префиксы не канают и это не глюк, а фича XPath.
(11) xzorkiix, нужно было наоборот.
1. Исходный текст имеет пространство по-умолчанию, скажем, Х (икс), и все узлы записаны без префиксов
2. На закладке пространства имен для Х указываем некий произвольный префикс, скажем, х(икс).
3. В выражении XPath обращаемся к узлам, которые без префиксов, через префикс х(икс), указанный на закладке
4. PROFIT. исходный XML не модифицируем, он идет, как есть.
т.е. у вас в файле <Узел>, а в выражении — x:Узел
(12)[посыпает голову пеплом]. Спасибо.
(5) Для notepad++ какой-то плагин? В самом редакторе на нашёл, в XML Tools тоже нет похожего.
(14) Поручик, тоже не вижу плагина…
(15) Нашёл. xpatherizernpp. XML XPath Query Analyzer Plugin for NotePad ++.
(15) Ещё до кучи в качестве закладки
XPather
…generates XPaths while browsing or inspecting HTML/XML/*ML documents; evaluates your XPaths and inspects the results; extracts the content.
(17) Поручик, не ставил пока, спрошу: а они умеют вычислять не относительно начала документа, а относительно произольного узла?
(18) В плагине для notepad++ понятия произвольного узла нет. И другой момент, если для документа установлена кодировка UTF-XX, то он плохо работает с кириллическими названиями тэгов, атрибутов, текстовым содержимым. Надо переключаться в режим ANSI.
(19) Поручик, тогда фтопку плагин, моя обработка рулит! 😉
(20) Я пользуюсь обеими средствами. У тебя не сохраняется сам текст xml и нет возможности загрузить из файла. Могу и сам сделать, но лень. Зато в плагине не сохраняется выражение Xpath. Кстати, рекомендую сохранять историю выражений в списке выбора.
Я бы сделал, но ту свою задачу выполнил и уже особо не интересно.
(21) Поручик, да, история выражения и сохранение нужны. Недавно тоже XPath-ил с помощью обработки и их не хватало. Но, как ты выразился, сделать лень.
(23) Я с истории практически начал, в своей обработке, да и в текст её вываливать там можно. И сохранение тоже потребовалось сразу. А вот с пространствами имён даже заморачиваться не стал. Думал ещё точку начала поиска сделать изменяемой, но так и не освоил дзен, как заставить это работать без ошибки несоответствия.
(24) Yashazz, просто без пространств имен вроде как XPath не работает, или я что-то путаю?
Если есть файл с ПИ по умолчанию (т.е без префикса), то выражение ничего не найдет. Пример:
<root xmlns=»http://someURI.com»>
<elem>куку</elem>
</root>
Выражение /root/elem ничего не найдет, ибо XPath процессору нужен префикс для . Это соответствие как раз для такого обхода — в файле без префиксов, а в выражении с префиксами: /ns:root/ns:elem. Соответствие префиксов у вас отсутствует и подобный файл обработать с помощью XPath не получится. Возможно, я что-то уже и путаю на старости лет, не уверен на 100%
Зря скачал.
В заголовке написано: «Обработка позволяет производить отладку выражений XPath на произвольном документе».
Скачал, вставил документ HTML обработка выдает ошибку, что открывающих тегов более 1, получается, что обработка работает не с «произвольными документами», а с документами XML.
Надо бы дизинформацию из заголовка убрать.
(26)
А че картинку не засунул?
(26) Честно говоря, и в голову не пришло, что кто-то захочет применять XPath для обработки HTML. Под словом «документ» понимается документ XML. Дезинформации здесь не вижу.