

Несмотря на определенную «заумность» термина, транзитивное замыкание – это простое и часто встречающееся на практике понятие. Вот примеры:
- Если известно, что пункт А связан с пунктом Б, а пункт Б с пунктом В, то делая вывод о том, что пункт А в итоге связан и с пунктом В, мы «транзитивно замыкаем» отношение «связанность».
- Если группа 1-1-1 входит в отдел 1-1, а тот, в свою очередь является частью департамента 1, то группа 1-1-1 также входит и в департамент 1 в результате «транзитивного замыкания» отношения «вхождение».
- Если рядовой Иванов подчиняется лейтенанту Петрову, лейтенант Петров – капитану Сидорову, капитан Сидоров – майору Пронину, майор Пронин – полковнику Хитрову, а полковник Хитров – генералу Дурову, то рядовой Иванов, хотя и закончил мехмат, также подчиняется генералу Дурову в результате транзитивного замыкания отношения «подчинение».
Получается, что когда спрашивается, как определить все группы, в которые входит некоторая номенклатура или как для каждого подразделения определить все подразделения, включенные в него иерархически, на самом деле необходимо решить одну и ту же математическую задачу: построить транзитивное замыкание соответствующих отношений.
Вопрос о том, как решать и можно ли вообще решить подобную задачу, встречается довольно часто. Можно упомянуть публикации «Получение родителя верхнего уровня с помощью СКД»[//infostart.ru/public/84547/], «Соединение в запросе, сравнение (В ИЕРАРХИИ)»[//infostart.ru/public/102086/], «Пример получения в запросе всех подразделений с учётом иерархии (неограниченный уровень вложенности подразделений)» [//infostart.ru/public/117349/], недавнее обсуждение на форуме «Запрос из справочника с выборкой подчиненных элементов» [http://forum.infostart.ru/forum26/topic72977/message781790/#message781790]. Решение, описываемое в статье, появилось в ходе обсуждения «Реально написать хитрый запрос» [http://forum.infostart.ru/forum14/topic35991/message395140/#message395140], и было там же опубликовано [(103)], однако осталось почти незамеченным. Данная публикация восполняет этот пробел.
Очевидная трудность решения данной задачи заключается в природе табличного представления отношений в реляционных СУБД. Допустим, отношения связанности (например) хранятся в таблице, которая имеет следующий вид:
| Пункт … связан | с пунктом … |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| … | … |
| 99 | 100 |
Тогда, чтобы определить, что пункт 1 связан с пунктом 100, потребуется выполнить множество соединений, число которых, к тому же, будет зависеть от исходных данных.
Тем не менее, решение есть. Оно довольно простое, хотя и не очевидное. Решение опирается на кое-какую математику. Вот она:
Если А – матрица смежности графа исходного отношения, то ее элемент aij равен 1, если i связан с j и 0, если связи нет. Таким образом, ненулевые элементы матрицы А фактически отмечают существование в отношении путей длины 1, А2 (А в степени 2) – путей длины 2, А3 – путей длины 3 и так далее. Если Е – единичная матрица, то
(А + Е)n = Аn + … + A3 + A2 + A + E.
Это специфическое биноминальное разложение представляет собой матрицу смежности графа, содержащего пути длины 0, 1, 2, 3, … , n. Здесь нет биноминальных коэффициентов, потому что операции умножения и сложения выполняются по правилам алгебры логики: 0+0=0, 0+1=1, 1+0=1, 1+1=1. Ну и поскольку в графе из N вершин нет путей длины больше N, то (A + E)N и будет матрицей смежности транзитивного замыкания исходного отношения.
Во всем, что говорилось до настоящего момента, ничего нового нет. Формулы выражают общеизвестный способ, когда мы по шагам накапливаем замыкание, добавляя на каждом шаге более длинные пути. То есть, в случае отношения иерархического подчинения, сначала находим и добавляем к итоговой таблице таблицу потомков уровня 1, потом уровня 2, потом уровня 3 и так далее.
Новое заключается в том, что:
- Замечено, что если M > N, где N – максимальная длина пути, то (A + E)N = (A + E)M. То есть, можно не бояться возведения в степень «с запасом», которая больше, чем максимальная длина пути (глубина иерархии). Результат от этого не изменится.
- Предлагается вычислять (A+E)M следующим быстрым и эффективным способом: (А+E)2 = (А+E)(А+E), (А+E)4 = (А+E)2 (А+E)2 , (А+E)8 = (А+E)4( А+E)4, (А+E)16 = (А+E)8( А+E)8 и так далее, пока степень не станет больше требуемой.
Если попытаться объяснить прием словами, без формул, то получится следующее:
На первом этапе объединяем (UNION) с исходной таблицей путей длины 1 таблицу путей длины 0 (каждый элемент связан с самим собой). Далее соединяем (JOIN) эту таблицу с собой, чтобы получить в результирующей таблице пути длины 0, 1 и 2. Снова соединяем полученную таблицу с собой и получаем в результирующей таблице пути длины 0, 1, 2, 3, 4. Уже в следующем соединении получим пути длины 0, 1, 2, 3, 4, 5, 6, 7, 8. Далее максимальная длина пути будет быстро расти и очень скоро преодолеет любой заданный предел.
При реализации на языке 1С, получается следующая достаточно компактная функция, возвращающая в качестве результата таблицу транзитивного замыкания. Функция приведена на примере отношения иерархии групп и элементов справочника. Эту функцию можно использовать как шаблон и для других отношений. Потребуется всего лишь заменить текст в переменной «Пролог».
Функция ТранзитивноеЗамыкание(ИмяСправочника, МаксимальнаяДлинаПути) Экспорт
Пролог = «ВЫБРАТЬ Родитель НачалоДуги, Ссылка КонецДуги ПОМЕСТИТЬ ЗамыканияДлины1 ИЗ Справочник.Номенклатура
| ГДЕ Родитель <> Значение(Справочник.Номенклатура.ПустаяСсылка)
| ОБЪЕДИНИТЬ ВЫБРАТЬ Ссылка, Ссылка ИЗ Справочник.Номенклатура;»;
Рефрен = «ВЫБРАТЬ РАЗЛИЧНЫЕ ПерваяДуга.НачалоДуги, ВтораяДуга.КонецДуги ПОМЕСТИТЬ ЗамыканияДлины#2 ИЗ ЗамыканияДлины#1 КАК ПерваяДуга
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ ЗамыканияДлины#1 КАК ВтораяДуга ПО ПерваяДуга.КонецДуги = ВтораяДуга.НачалоДуги;
| УНИЧТОЖИТЬ ЗамыканияДлины#1;»;
Эпилог = «ВЫБРАТЬ НачалоДуги Предок, КонецДуги Потомок ИЗ ЗамыканияДлины#2 ГДЕ НачалоДуги <> КонецДуги»;
Запрос = Новый Запрос(СтрЗаменить(Пролог, «Номенклатура», ИмяСправочника));
МаксимальнаяДлинаЗамыканий = 1;
Пока МаксимальнаяДлинаЗамыканий < МаксимальнаяДлинаПути Цикл
Запрос.Текст = Запрос.Текст + СтрЗаменить(СтрЗаменить(Рефрен, «#1», Формат(МаксимальнаяДлинаЗамыканий, «ЧГ=0»)), «#2», Формат(2 * МаксимальнаяДлинаЗамыканий, «ЧГ=0»));
МаксимальнаяДлинаЗамыканий = 2 * МаксимальнаяДлинаЗамыканий
КонецЦикла;
Запрос.Текст = Запрос.Текст + СтрЗаменить(Эпилог, «#2», Формат(МаксимальнаяДлинаЗамыканий, «ЧГ=0»));
Возврат Запрос.Выполнить().Выгрузить()
КонецФункции
В теле функции сначала собирается текст запроса. Он состоит из «пролога», который извлекает из базы данных исходное отношение, дополняет его путями нулевой длины и помещает результат во временную таблицу путей длины 1 и 0. Это единственная часть функции, которая зависит от структуры данных и типа исходного отношения. Далее следует «рефрен» — повторяемая часть запроса, в которой короткие пути соединяются в более длинные пути для новой временной таблицы, а также удаляется временная таблица, полученная на предыдущем шаге. Завершает текст запроса «эпилог», в котором извлекается итоговая временная таблица. После сборки полученный пакетный запрос единожды выполняется.
На первый взгляд может показаться, что текст запроса будет очень длинным. На самом деле, даже если справочник содержит миллион элементов в цепочке подчинения (мегаматрешка!), понадобится всего двадцать рефренов. Запрос будет в десятки (сотни?) раз короче некоторых запросов в ЗиУП.
Второе замечание, которое можно предупредить, это то, что, возможно, потребуется отдельный запрос для определения количества элементов в справочнике, чтобы оценить максимальную длину пути (уровень подчинения). Ответом здесь будет то, что на практике почти всегда можно будет взять некоторое достаточно большое число, например 256 или 1000, исходя из характера задачи.
Третье замечание может заключаться в сомнениях: а насколько это будет быстро работать? Специально для скептиков прилагается отчет, работающий в любой конфигурации, который строит транзитивную иерархию любого справочника с замером времени выполнения запроса. Оно измеряется миллисекундами.
Ну и, наконец, для тех, кто заметил сходство математики предлагаемого метода и «Порождающего запроса» [//infostart.ru/public/90367/], могу добавить, что порождающий запрос появился именно вследствие данного решения.
P.S.: Если провести небольшой рефакторинг и перевести функцию на английский, она будет выглядеть компактней (всего 9 строк!)
function closure(name, N, M = 1) export
q = new query(strreplace(«select parent a, ref b into r1 from catalog._ where parent <> value(catalog._.emptyref) union select ref, ref from catalog._;», «_», name));
while M < N do
q.text = q.text + strreplace(strreplace(«select distinct p1.a, p2.b into r#2 from r#1 as p1 join r#1 as p2 on p1.b = p2.a; drop r#1;», «#1», format(M, «NG=0»)), «#2», format(2 * M, «NG=0»));
M = 2 * M
enddo;
q.text = q.text + strreplace(«select a Предок, b Потомок from r#2 where a <> b», «#2», format(M, «NG=0»));
return q.execute().unload()
endfunction
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
мм.. первыйнах..
А можно хоть для примера полный текст запроса глянуть? )
*bogdan_sukonnov отскребает мозг со стен
Сергей, я бы хотел понять эту статью, и вижу как Вы считаете, что объясняете свою мысль. Но Ваше представление об очевидном и понятном далеко от реальности (к сожалению, таких как я много).
Интересно наблюдать как от объяснений на русском — Хитровых,Дуровых вы перешли к «матрица смежности графа исходного отношения», «путей длины» и т.п.
Самое плохое, что когда Вы пытаетесь объяснить «словами, без формул» терминология от формул остается.
Может быть стоит добавить примеры? Исходный справочник, результаты первого соединения, результаты второго.
И может быть список литературы? Оно, конечно погуглить можно, но все-таки.
Сейчас увидим 1с-ников без программерско — математического образования =)
Т. к. редко можно встретить программиста, не проходившего в ВУЗе математику, то, думаю, большинству объяснения понятны. Ценность данной статьи в том, что автор это реализовал и сделал замер производительности. Я не думал, что это будет эффективным решением с точки зрения производительности. Автор показал обратное. За это плюс.
С математической точки зрения интересно. С практической же …
Запрос.Текст = «ВЫБРАТЬ
| Номенклатура.Ссылка КАК Ссылка
|ИЗ
| Справочник.Номенклатура КАК Номенклатура
|ГДЕ
| Номенклатура.Ссылка = &Ссылка
|ИТОГИ ПО
| Ссылка ТОЛЬКО ИЕРАРХИЯ«;
МассивРодителей = Запрос.Выполнить().Выгрузить().ВыгрузитьКолонку(«Ссылка»);
МассивРодителей.Удалить(МассивРодителей.Найти(Ссылка).Индекс);
Проще и нагляднее )
(6) mymyka,
совершенно верно… потому как с практической..
ildarovich, у вас идет накручивание запроса в цикле по частям — а как вы определяете связи дуг между собой? Что это — конец одной и начало другой?
Что «Иванов подчиняется лейтенанту Петрову, капитан Сидоров – майору Пронину» вы знаете, но где вы узнаете подчиненнность лейтенанта Петрова и капитана Сидорова между собой, пока не опросите весь гарнизон (миллионный справочник)?
Да еще и глубину надо задавать жестко..
(6) Действительно, найти ВСЕХ предков ОДНОГО элемента справочника можно с помощью предложенного Вами запроса, хотя его недостатком является использование выражения ИТОГИ, что не позволяет использовать его в пакете. Метод, описываемый в статье, находит сразу ВСЕХ предков (потомков) ВСЕХ элементов справочника, может быть использован в пакете и не использует объективно (в статье показано почему) медленную (причина тормозов многих запросов) конструкцию В ИЕРАРХИИ.
Кроме того, метод подходит и для других типов связей, например связей аналогов запасных частей, когда известно, что запасная часть Б является аналогом А, запасная часть В — аналогом Б, часть Г — аналогом В и нужно найти все аналоги А. Или, например, связи документов «на основании» и тому подобное.
(8)
Вы не сможете найти ВСЕХ предков вашим методом, если цепочка генеалогической связи прерывается, и её надо восстанавливать на основе отсутствующих данных — проще говоря, если таковая связь нигде не обозначена (в именах потомков-предков, в отдельной таблице связей etc), единственный способо её найти — перебрать ВСЕ элементы иерархией и выяснить, у кого из них родственная связь с искомым.
(10) AlexO,
Вообще непонятно к чему фраза. Что значит «цепочка прерывается«? Описанный в статье метод именно для этого и предназначен — для нахождение всех предков или всех потомков всех элементов. Даже если уровень вложенности сравним с общим количеством элементов таблицы.
(11) sashocq,
я вижу в методе только восстановление заранее известных цепочек «КонецДуги является началом НачалоДуги дуги-родственника», т.е. связь родственников между собой как-то и чем-то должна быть уже предопределена.
Как в примере «рядовой подчиняется лейтененату, лейтенант подчиняется капитану, значит рядовой подчиняется капитану» (хотя по субординации как раз не так 🙂 )
А не перебор всех-ко-всем.
Как раз этого-то и избегает Сергей, и это же вынесено в качестве главного смысла метода.
Я не нахожу составления таблицы связей все-со-всеми и поиск по ней.
А перебор всех — это как раз и исключено.
(9) Зря Вы так про 1С. Тем более она здесь ни при чем: в статье описан математический метод, алгоритм. Он будет хорошо работать на любой платформе: 1С, Java, T-SQL, C++ и так далее, давая в результате существенное ускорение построения транзитивного замыкания. Этому не помешает никакая «дырка в разработке языка 1С, Т-SQL, Java, C++, PHP (нужное подчеркнуть), появившаяся вследствии неграмотной методологии и разгильдяйской реализации»
(13)
да я не спорю, что ваш метод больше математический, чем 1совый 🙂
Я про то, что сам разработчик не может/не хочет (нужное подчеркнуть) разработать инструменты по работе с им же придуманными сущностям 🙂
(12) AlexO,
А она есть. Выполняется несколько запросов в пакете.
1-й составляет связи длиной 1 (A — B)
2-й составляет связи длиной 2 (A — ? — B)
3-й — 4
4-й — 8
5-й — 16
i-й — 2#k8SjZc9Dxk(i-1)
т.е. чтобы в таблице оказались связи длиной до 1048576 нужно выполнить 21 такой запрос.
Не в цикле! А в пакете.
И, похоже, при небольшой модификации запроса можно добавить поле длины пути между элементами.
(15) Все точно! Похожими запросами (добавив длину пути) можно определить максимальную глубину справочника, а также найти циклы. Вскоре я добавлю в статью эти запросы — пока просто не могу решить: делать одну функцию или две.
Последствия от использования такие же как на логотипе?
Умно!) Математика на службе у программистов 1с 🙂 Плюсую 🙂
(15) sashocq,
ну, и где тогда искать 2 и 3-го родителя?
(13)
Это описание как-то далеко от математики. Про теорию множеств и кортежи вообще не упомянуто.
(1) Вот полный текст запроса на примере справочника «Военнослужащие» с иерархией элементов и ограничением длины замыканий равным 8:
Показать
(2) Пример последовательности таблиц в задаче о подчинении военнослужащих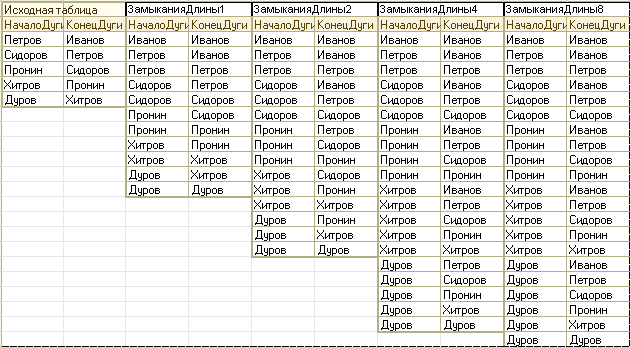
(21)
> и ограничением длины замыканий равным 8
А почему именно 8?
(0) > На самом деле, даже если справочник содержит миллион элементов в цепочке подчинения (мегаматрешка!), понадобится всего двадцать рефренов
А почему именно 20? Не увидел формулу для вычисления, возможно, я невнимательно прочитал?
(23) Восемь — потому, что военнослужащих шесть, а 8 — ближайшее к нему сверху число из ряда 1-2-4-8-16-32-64-128-256-512-1024 и так далее.
В справочнике из шести элементов не может существовать подчинения глубины больше 5-ти.
На каждом шаге находим подчинения уровня 1-2-4-8-16-32 и так далее, пока этот уровень не станет больше числа элементов справочника или заранее заданного числа (например, в конфигурации задана максимальная глубина иерархии справочника или есть соображения разумной достаточности).
Формулы в статье нет, в тексте программы формула применяется неявно, правильное объяснение в также в (15).
(25) Не совсем понял вопрос.
В самом сложном случае максимальная длина пути в графе транзитивного замыкания отношения (любого, не обязательно иерархического) совпадает с числом вершин — элементов. Число элементов легко посчитать предварительно, еще одним запросом. Так сделано в прилагаемой обработке. Она универсальна, работает во всех случаях, без всяких ограничений на глубину иерархии. Однако предварительный подсчет числа элементов справочника отдельным запросом даже не всегда нужен. Возьмите справочник Номенклатура. Может в нем быть больше 1000 уровней? По смыслу этого справочника? Или справочник контрагентов? Всегда можно определить какое-то число с большим запасом! Или возьмите отношение подчинения военнослужащих — знаете, сколько сейчас служащих в армии? — Тогда задайте это число как ограничение уровней иерархии!
Не все основано на иерархии — суть отношения может быть любой. В исходной задаче («Реально написать хитрый запрос») речь шла просто о связанности элементов, когда один элемент имеет реквизит (или ТЧ), содержащий(содержащую) ссылку на другой элемент справочника.
В качестве тестовой можете использовать любую типовую демо-конфигурацию.
(26)
Речь об аналогах. Как можно решить эту задачу, используя данный метод?
Приведите пример запроса.
вот такой не работает
Показать
> Возьмите справочник Номенклатура. Может в нем быть больше 1000 уровней?
А цепочка аналогов вполне 😉
т.е. подчиненность военнослужащих в (22) основана на иерархии справочника?! Стесняюсь спросить — Вы в армии служили?
P.S. Ну раз тут адвокаты прибежали и минус мне поставили, тогда и я поставлю 🙂
(27) Вот, пожалуйста, для УПП. Этот текст должен быть записан в переменную «Пролог»:
Показать
(28)
НачалоДуги КонецДуги
Диван для отдыха Кухонный гарнитур «Тинга-У»
Диван для отдыха Компьютер
Кухонный гарнитур «Тинга-У» Диван для отдыха
Компьютер Диван для отдыха
Диван для отдыха Диван для отдыха
Диван для отдыха Диван для отдыха
хм….
Это не окончательный запрос?!
(27) Чтобы в ЦЕПОЧКЕ аналогов было 1000 записей, у Вас должно быть 1000 РАЗЛИЧНЫХ И ВЗАИМОЗАМЕНЯЕМЫХ деталей. Неправдоподобный случай. Ну, если Вы настаиваете, возможно, подойдет число 65535?
(29) Было сказано, что этот текст должен был записан в переменную «Пролог». То есть я посчитал, что Вы скачаете отчет, замените в модуле объекта текст в функции ТранзитивноеЗамыкание правее Знака равенства Пролог = на тот, который был прислан, ну и попытаетесь нажать кнопку «Выполнить» после всего. По хорошему, еще стоит посчитать записи в Регистре сведений «аналоги номенклатуры». Ну если Вам это трудно сделать, чуть подождите — сделаю готовый отчет.
(31) Я не цепляюсь к мелочам. Просто ни знаю ни одной запчасти, у которой ОДНОЙ было бы 1000 аналогов, да еще заданных цепочкой.
(32)
скачал, заменил.
Показать
{ВнешнийОтчет.ТранзитивноеЗамыканиеИерархии.МодульОбъекта(69)}: Ошибка при вызове метода контекста (Выполнить)
Возврат Запрос.Выполнить().Выгрузить()
по причине:
{(22, 69)}: Синтаксическая ошибка «РАЗЛИЧНЫЕ»
РегистрСведений.АналогиНоменклатуры КАК АналогиНоменклатурыВЫБРАТЬ <<?>>РАЗЛИЧНЫЕ ПерваяДуга.НачалоДуги, ВтораяДуга.КонецДуги ПОМЕСТИТЬ ЗамыканияДлины2 ИЗ ЗамыканияДлины1 КАК ПерваяДуга
(33) нужно различать понятия «неправдоподобное» и «маловероятное»
вот как надо решать такие задачи 🙂
(34) забыли в Прологе внутри «» поставить «;»
(37) кто забыл?
(27)(29)(32) Вот обещанный отчет для замыкания аналогии …и результаты его работы после того как в Демо-Базе добавил четыре записи в Регистр АналогиНоменклатуры. Сделал аналогами все вентиляторы по цепочке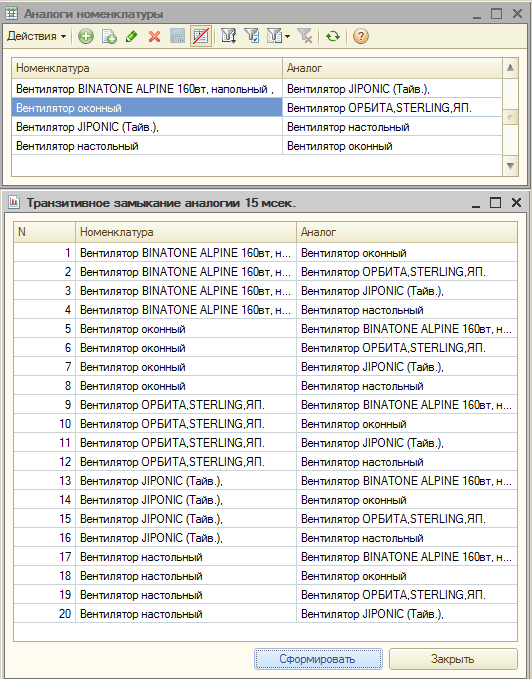
(38) Мы с Вами забыли (((
(39) спасибо! вот теперь стало намного понятнее
(24)
в общем, не совсем понятно, как теория из статьи соотносится с практикой же из статьи 🙂
а именно — все эти x в n степени, где n-кратное 2, и сам запрос.
Имеем:
число элементов всего справочника (включая все каталоги) — 17
пусть вложенность = 5, берем до n=8 (ну, типа, теория у нас такая, будем пока её придерживаться 🙂 )
1-ый запрос:
получили ВСЕ элементы справочника (и где ж тут ускорение, если у меня будет мильен элементов в справочнике должны ОДНОВРЕМЕННО лежать в памяти во временной таблице? ну ладно, это вопрос первый был) — их 17, плюс — еще 13 элементов, которые ТОЛЬКО ПОДЧИНЕННЫЕ (вложены).
Итого — на первом этапе имеем 30 записей в ВрТ «ЗамыканияДлины1».
2-ой запрос:
начинаем «замыкать» полученную таблицу на саму себя методом «конец хватай сам себя из начала любой записи».
Получаем «ЗамыканияДлины2», записей — уже 34.
3-ой запрос:
начинаем «замыкать» аналогично 2-му запросу, получаем ВрТ «ЗамыканияДлины4», получаем 39 записи (ну понятно, исходные плюс насоединевываем дополнительно пары Предок-Потомок из «соседних пар» реальных вложений согласно вложенности; это вроде как получили все пары первой вложенности с конца + исходные пары — хотя на самом деле ).
Ну, и крутим дальше наш запрос, пока не создадим все пары вложенностей потомков ко всем их родителям до n включительно, каковое n определяем эмпирически сами по глубине вложенности справочника.
3-ой запрос:
ВрТ «ЗамыканияДлины8» — 40 записей.
Чем больше вложенностей — тем больше записей добавляется.
В конце из полученной ВрТ «ЗамыканияДлины8» вырезаем замыкания записей на самих себя, оставляя только пары: 23 записи
Т.е. в результате получили длинющий список всех возможных вариантов отношений по реальной иерархии: т.е. если 1-2-3-4-5, то и 1 лежит в 5.
Но тут опять же перебор ВСЕХ потомков со ВСЕМИ предками.
Шило на мыло.
(36) Ссылку посмотрел, спасибо, однако по-прежнему думаю, что данный метод быстрее, поскольку в указанной RCTE используется рекурсия, которая не соединяет таблицу саму с собой, а добавляет к получаемой таблице «С» (в моей статье — это таблица «А») пути длины 1 на каждом шаге из указанной таблицы «rel». То есть рекурсия будет выполнятся столько раз, какова максимальная длина пути в графе, а у меня — гораздо меньше раз!
(36) Altair777,
вот это реальное решение — когда средствами СУБД на «аппаратном» так сказать уровне, зная конец и начало Предков-Потомков, находим всю цепочку.
А в 1С — костыли, от которых 1С не перестает хромать на обе ноги 🙂
При всем уважении к Сергею и его масштабным усилиям закрасить ущербность нашей любимой платформы 🙂
(44)
а разве соединение таблицы самой с собой и такие многократные прогоны, равные числу вложенностей, не являются рекурсией?
(44)
т.е. в любом случае любая реализация на уровне платформы, как в (36), будет быстрее костылей 🙂
(43) Не понял, где шило, а где мыло. Пусть запрос, указанный в статье, «мыло». А где «шило»? Приведите свой, другой вариант запроса, который будет проще, быстрее. Тогда вопрос будет понятнее. Только не забудьте, что в итоговой таблице в данном запросе должны быть все пары элементов, из которых можно попасть друг в друга. Их всегда довольно много. Именно такая таблица называется транзитивным замыканием и дает возможность для любого элемента получить список его потомков (для подчиненности) и список его предков.
осталось только решить одну классическую задачу для этого метода — прокладка оптимальных маршрутов между точками
(48)
так вот же, дырка в реализации в (6)
(49) Altair777,
как раз этого-то никто никогда и не решит 🙂
Разве что позитронный мозг сделают для решения каждой конкретной задачи по нахождению оптимального маршрута в конкретном случае 🙂
(45) Позволю себе сказать, что кто-то хромает на обе ноги, когда научусь ходить сам, например, заставлю работать больше 9 миллионов строк кода больше чем у 1 миллиона пользователей.
«Уважение к потугам» почему-то привык всегда автоматом заменять в тексте на «уважение к усилиям».
(46) Рекурсия рекурсии рознь, ее можно построить по-разному. Еще раз повторяю, что в предлагаемом мной подходе соединений меньше!
(47) Если запрос, приведенный в статье, Вы называете костылем, то что для Вас, например, крылья?
(53)
заменил, без проблем 🙂
и опять же — пример крыльев в (36)
(52) А для чего, по Вашему, используется запрос из (36)?
(49)(52) Ничего сложного в этой задаче нет. Почти все алгоритмы давно открыты и исследованы. Не хватает времени и грамотных автоматизаторов.
(53)
ну это, наверное, не только меня поставило в тупик, что это, и откуда 🙂
(56)
.. и все исследованные алгоритмы имеют сильные и слабые стороны, и также неэффективны в одних случаях, как крайне эффективны в других
и опять ставите в тупик… 🙂
для чего-для чего — найти и построить недостающие связи на основе исходных данных.
Или Вы хотели сразу и всех родителей? 🙂
Нет, увы, там только пример подобной реализации для своих задач.
Так я уже поднимал этот вопрос в (9) — как раз именно это и легко реализовать на уровне платформы, причем 1с-справочники — это не инопланетные корабли, запущенные неизвестно кем 🙂
Ну вот вам ещё на почитать:
Простым русским языком, что характерно.
(47) Совести у Вас нет — попрекать меня костылями (шутка). А вообще-то это не костыль, это (мой запрос) — трость! И даже весьма изящная.
(шутка). А вообще-то это не костыль, это (мой запрос) — трость! И даже весьма изящная.
(58) Спасибо за ссылку. Если внимательно просмотреть указанную статью, то в ней говорится:
1. Только об отношениях иерархии, тогда как в данной статье иерархия приведена как ОДИН из примеров прикладной задачи, решаемой предлагаемым методом;
2. Из-за особых свойств отношения иерархии для нее возможно использование вспомогательных структур «чтобы легко и быстро получать ответы на перечисленные вопросы». Запрос, приведенный в статье, не требует использования вспомогательных структур, «чтобы легко и быстро получать ответы на перечисленные вопросы».
3. Кстати, метод «вспомогательная таблица», без доказательств определяемый в статье как «более эффективный и удобный» использует в качестве ВСПОМОГАТЕЛЬНОЙ таблицы как раз таблицу ТРАНЗИТИВНОГО ЗАМЫКАНИЯ (!!!). Про ее получение в статье не сказано, говорится лишь (без доказательств! — а вдруг автор ошибся?), что
4. Примеров запросов в статье ни одного нет.
Поэтому лучше использовать первоисточники. Например, того же .
(60) Вообще-то, в статейке описана точно та же структура данных, которую ты в итоге получаешь. Вот и всё, что я хотел сказать 🙂
Слово «иерархия» в статейке можно заменить любым другим отношением, суть не изменится.
Что касается практического использования, то у нас это сплошь и рядом — фильтры по группам справочников. В отчётах и формах списков.
Типа:
фильтр
SELECT
…
FROM
спрМатериалы Материалы
WHERE
Материалы.ID IN (SELECT ID FROM Дерево_Материалы WHERE ParentID = :ВыбМатериал)
уровень (на практике не используется, просто как пример)
SELECT Count(*) Уровень
FROM Дерево_Материалы
WHERE ID = :ВыбМатериал
вот кстати ещё, про практику
Я не знаю, можно ли в восьмёрке поддерживать подобную структуру, но с точки зрения быстродействия это всё же выгоднее, чем генерить её каждый раз.
(61) Большое спасибо за ссылки!
Не знаю, нужно ли мне спорить? Не хочу спорить по пустякам, цепляясь к Вашим словам, хотя там есть неточности. Просто не понимаю, к чему Вы клоните.
Я с Вами согласен, что для эффективной работы с иерархическим справочником МОЖНО использовать дополнительные структуры данных. Я знаю, что отношение иерархии — особенное, вершины дерева нумеруются левосторонним обходом. На этом построен подход Joe Celco. Мог бы предложить свой вариант на принципах «арифметического кодирования». Можно использовать и таблицу транзитивного замыкания (довольно, кстати, большую (если матрешка состоит из 1000 матрешек, то там будет 500000 записей)), и малыми силами поддерживать ее в актуальном состоянии при вставке, обновлении и удалении элементов справочника. Кстати, очень заинтересовала работа Ваших триггеров. Как отрабатывается ситуация удаления из цепочки 1-2-3-4-5-6, элемента 3-4? Разрывается ли при этом связь 1-6? Или я чего-то просмотрел?
Однако в моей статье речь идет не совсем об этом. Предлагается НОВЫЙ (даже для T-SQL) метод БЫСТРОГО (за счет каскадного возведения в степень) построения транзитивного замыкания с «нуля» без использования вспомогательных таблиц. При этом метод работает с ЛЮБЫМИ транзитивными отношениями (в том числе с циклическими). Метод был предложен не из любви к искусству (хотя она присутствует), а потому что люди спрашивают: «как это сделать» (ссылки я привел). Можно, например, построить транзитивное замыкание перед выполнением сложного отчета, завязанного на иерархию. Думаю, найдутся и другие применения, кроме уже указанных в статье.
А вот для дерева прав метод не подойдет. Я этого и не утверждал. Поскольку выдаваемая таблица для проверки обладания правами ОДНИМ пользователем будет ИЗБЫТОЧНА.
Если я правильно понял, в тексте функции в статье есть ошибка :
ЗамыканияДлины1, а надо ЗамыканияДлины#1
(в прологе)
(63) bulpi,
Все, понял, был неправ
(63) bulpi,
все там правильно, это не часть Рефрен.
(62) Я не имел целью спорить, и никуда особо не клоню. Просто потрындеть за практическую реализацию. Всё-таки меня практика гораздо больше занимает, чем теория 🙂
> Как отрабатывается ситуация удаления из цепочки 1-2-3-4-5-6, элемента 3-4? Разрывается ли при этом связь 1-6?
А никак не отрабатывается. Это всё рассчитано на очень конкретные условия применения, а именно на иерархию справочника. Из дерева тупо удаляются все пары, в которых участвует удаляемый элемент. При этом предполагается, что при удалении нетерминального узла, сначала будут удалены и все его подчинённые узлы. Иными словами, нетерминальные узлы вообще никогда не удаляются.
При удалении именно связи будет посложнее. Надо удалять пары 1-5, 1-6, 2-5, 2-6 и т.д.
Про права. Ну почему же не подойдёт? Вполне. Там смысл был найти первого родителя в дереве, у которого что-то явно прописано. Примерно так:
|SELECT Top 1
|
|FROM
| спрОбъектПриложенияПрав ОПП
| LEFT JOIN Дерево ON Дерево.ID = ОПП.ID
| LEFT JOIN спрОбъектПриложенияПрав ОПП_Действующий ON
| ОПП_Действующий.ParentID = Дерево.ParentID
| OR ОПП_Действующий.ID = :ОбъектПриложения
|
|WHERE
| ОПП = :ОбъектПриложения
| AND ОПП_Действующий.Право != $ПустойИД
|ORDER BY
| ОПП_Действующий.Уровень Desc
(я по привычке пишу ParentId и ID, в терминах статьи будет НачалоДуги, КонецДуги)
Иерархия объектов приложения при этом такая
Задача
Документ
Шапка
Реквизит
ТЧ
Справочник
…
Что же касается объёмов вспомогательной таблицы, то опять же, учитываем специфику SQL, т.е. начхать на объёмы, главное чтобы в индекс чотко попадать.
Избыточность же здесь вообще заранее задекларирована, и сомненью не подлежит.
> При удалении именно связи будет посложнее. Надо удалять пары 1-5, 1-6, 2-5, 2-6 и т.д.
|DELETE FROM Дерево
|WHERE
| ParentID IN (Родители_для_3)
| AND ID IN (Потомки_для_4)
вроде так
(66) Все понятно, согласен.
(67) Да, именно так. Ну и так как Update можно сделать Как Delete+Insert, все случаи будут отработаны. Это замечательно свойство деревьев — транзитивное замыкание можно наращивать, добавляя по одной дуге основного отношения и симметрично сокращать, убирая по одной дуге. Такой симметрии нет, например, в сборочных спецификациях, когда одна деталь входит в разные узлы — это значит, что есть параллельные ветви и прием из (67) не работает. Получается, Ваш практический пример рассеял мои сомнения по поводу утверждения из статьи Виноградова
Спасибо!
(54) Специально для Вас переписал функцию. Эта та же функция! На языке 1С! Может быть в этом виде она Вам понравится?
Показать
Лучше уж на SQL. Всё-таки восьмёрошные средства написания запросов слегка удручают.
insert Дерево (ParentID, ID)
select ParentID, ID, 0
from спрМатериалы
where ParentID != ‘ 0 ‘
insert Дерево (ParentID, ID)
select ID, ID
from спрМатериалы
declare @level int
set @level = 0
while @@RowCount > 0
Begin
—print str(@level) + str(@@ROWCOUNT)
—set @level = @level + 1
insert Дерево (ParentID, ID)
select
Родители.ParentID, Потомки.ID
from
Дерево Родители
INNER JOIN Дерево Потомки ON Потомки.ParentID = Родители.ID
where
Not Exists (select * from Дерево Д where Д.ParentID = Родители.ParentID and Д.ID = Потомки.ID)
End
Кстати вопрос, а в чём практическая ценность записей (ref, ref)? Да и теоретическая тоже не очень понятна, ведь таких связей в графе нет.
(70) БЕЗ таких связей на первом шаге в таблице у нас будут ТОЛЬКО пути длины 1, на втором — ТОЛЬКО пути длины 2, на третьем — ТОЛЬКО пути длины 4, на пятом — ТОЛЬКО пути длины 8 и так далее. С такими связями на первом шаге в таблице у нас будут пути длины 0 и 1, на втором — пути длины 0, 1 и 2, на третьем — пути длины 0, 1, 2, 3 и 4, на четвертом — пути длины 0, 1, 2, 3, 4, 5, 6, 7 и 8 и так далее. Этот прием оставляет в накапливаемой таблице все ранее найденные связи. Теоретически это возведение в степень не самой матрицы A, а матрицы A + E, где E — единичная матрица.
спасибо отличная статья
Спасибо ! Для меня ОЧЕНЬ полезная статья. Как раз решаю нахождение всех комплектующих к определенному изделию да еще, если нет остатков, с аналогами комплектующих…. 8(
мне кажется, механизм «соединений наборов данных СКД» может это заменить
(74) Совершенно не представляю, что здесь общего.
Не совсем все понял но спасибо статья хорошая.
Спасибо за статью. Частные решения задачи иерархии(и СКД тоже) важны в понимании не иерархической структуры реляционных баз данных.
(70) ADirks,
Вроде, MSSQL имеет более изящные средства.
Конструкция WITH … AS позволяет реализовать рекурсию
Пытался решить эту задачу лет 10 назад, не хватило духу. Спасибо за статью, очень полезно.
Спасибо, буду разбираться. Сейчас решаю задачи производства, и надеюсь это поможет ускорить разузлование спецификаций.
Гениально. Пользуюсь уже с год. Мое почтение автору.
Отличная статья, есть хорошие комментарии, если исключить тупые придирки (точку с запятой сам поставить не додумался) некоторых авторов. У меня нервы сдали читать эти придирки, удивляюсь как у автора хватило терпения на них на все отвечать.
Много комментов типа «средствами СУБД» все проще — не пойму, будете в задаче анализировать какая СУБД используется и для каждой свои средства использовать что-ли ? Или просто выпендриться хотелось?
У меня, например, большинство клиентов на файловой базе работает, остальные на MSSQL и на Postgress. Ибо SQL-ный вариант 1С довольно таки дорого стоит и не все могут себе его позволить.
И не надо забывать, что конкретные задачи пишутся для конкретной предметной области, поэтому каждый разработчик должен сам решить какой именно способ в каждом конкретном месте стоит применять. И какова может быть вложенность иерархии в каждом конкретном месте и какие данные поместить в начальную выборку «Пролог» (из справочника или из регистра).
Автору жирный плюс за грамотный и красивый способ решения задачи, в некоторых местах своей разработки я 100% буду его применять для оптимизации работы. А в некоторых местах кода оставлю родные средства 1С, так как на 100% уверен в малом кол-ве вложенности и малом кол-ве записей данной предметной области.
(49) В публикации эта задача, наконец, рассмотрена.
Подскажите насчет второго замечания: «Второе замечание, которое можно предупредить, это то, что, возможно, потребуется отдельный запрос для определения количества элементов в справочнике, чтобы оценить максимальную длину пути (уровень подчинения).»
Если в справочнике стоит «Ограничения кол-ва уровней иерархии», то получить макс. длину путь можно будет так?
Спасибо.
(85) headMade, да, в точности так
В обсуждении приведена еще одна конкретная практическая задача про транзитивные скидки и ее решение с помощью метода, описанного в данной статье.
(3) Gulf_Stream, я 1С-ник без математического образования — и чо? Я ни слова не понял из приведённого описания, но результирующий запрос настолько банален и бородат, что просто даже жалко потраченного автором времени на все эти страшные математические выкладки.
Можно получить родителей, последовательно соединив таблицу с самой собой, выравнивая по следующему родителю — целое открытие! Прочитав заголовок, я думал, что автор изобрёл способ, как можно ТОЛЬКО запросом выбрать всех родителей и приготовился уже встать и яростно аплодировать, но увидев то, что сам делал неоднократно и то, что видел неоднократно реализованным другими, только в более простом виде и без всей этой высшей математики, даже как-то грустно стало. У этой задачи, кстати, и вариации есть, из того, что помню — из отрезков А-Б нужно складывать маршруты, где последняя точка отрезка — это первая точка следующего. Ещё почти такая же задача — на диапазоны номеров документов, когда у вас есть номера от 1 до 10000 и вы можете внутри них продавать любое число меньших диапазонов (5-100, 4579-6793 и т.п.) — не совсем тоже самое, даже, наверное, посложнее будет, но принцип того, что есть связь А-Б-В-Г…-Н, тоже присутствует. В некоторых задачах даже к использованию кода не приходилось прибегать — когда заранее известна максимальная вложенность — сразу готовый текст запроса, без извращений. В общем, так и не понял, из чего такой сыр-бор и главное — зачем тут высшая математика, если родителя-то и получить никаким другим способом не получится, кроме как последовательно нанизывать запросы со следующим родителем.
П.С, прочёл комментарии — просто не могу поверить, что никто с таким не сталкивался.
П.П.С. уничтожать таблицы в запросе имеет смысл только если используется менеджер временных таблиц или если зачем-то вдруг понадобилось использовать тоже самое имя таблицы. Во всех других случаях они и так уничтожаются после выполнения запроса.
(88) for_sale, чтобы разобраться в сути метода, попробуйте ответить на вопрос: сколько «ваших» запросов потребуется, чтобы последовательным нанизыванием запросов установить наличие связи 1-100 при наличии парных связей 0-1-2-3-4-5-6-7-8-9-10-11-12-13-14-15-16-17-18-19-…-90-91-92-93-94-95-96-97-98-99-100? Рискну предположить, что то, неоднократно виденное вами «грустное» решение потребует 100 запросов. То есть первым запросом определяем потомков первого уровня, вторым запросом соединением с потомками первого уровня получаем потомков второго уровня и так далее — всего 100 раз? — Вы этот метод имели ввиду?
Но мой метод требует для решения той-же задачи НЕ СТО, а ВСЕГО СЕМЬ запросов. А если цепочка будет иметь длину 1000 (глубина вложенности справочника 1000), потребуется ВСЕГО ДЕСЯТЬ ЗАПРОСОВ, миллион — ВСЕГО ДВАДЦАТЬ. Двадцати сделанных на всякий случай (с запасом) запросов будет хватать почти всегда. Даже запрос не нужно динамически строить. Его можно готовым записать. В этом и разница. За этим и нужна математика. Прием называется «матричное умножение» и довольно широко используется в других областях программирования.
Если посмотрите другие мои статьи — увидите другие решенные тем же методом практические задачи. В том числе определение кратчайших путей, критических путей и так далее.
— Ну что, теперь, наконец, развеселились?
Кстати, по-поводу задачки на номера документов. Если имеется ввиду объединение соседних отрезков в более крупные, то такая задачка для дат решена мной в статье . Под номером 14. Даты легко изменить на номера. Там всего пара запросов — никакой «транзитивности» в той задаче я не усмотрел. Там находится инвариант точек одного непрерывного отрезка и по нему делается группировка. — Посмотрите!
И вообще, если знаете какие-нибудь трудные задачи по запросам, скажите, мне они интересны.
По-поводу уничтожения таблиц: да, их можно не уничтожать, но сколько времени мы таким образом сэкономим? — Ничтожно мало. Я считал, что показанный запрос будет использоваться как часть других запросов, которым может понадобится освобожденная память, занятое имя таблицы. Поэтому здесь и сделан дроп. Убрать удаление легче, чем добавить, кому не нужно — уберет.
(89) да, теперь я вижу, что вы не просто нанизываете одного родителя на другого, а в прогрессии сокращаете количество запросов с астрономического до приемлемого. С точки зрения математики это, наверное, занимательно. Но с практической точки зрения я могу ещё сильнее упростить ваш запрос!
«ВЫБРАТЬ Ссылка, Родитель ИЗ Справочник.Номенклатура»
Результат запроса будет почти такой же.
Вы просто выбираете все элементы и их родителей. Практическая ценность вашего решения существовала бы только если можно было бы получить всех родителей ОДНОГО ЗАДАННОГО элемента. Но этого как раз ваш запрос не даёт, к сожалению.
Нет, можно, конечно, в последнем запросе наложить условие, получить строки с родителями, в цикле обойти их, но, благодаря использованию конструкции РАЗЛИЧНЫЕ в запросе, он работает ооочень медленно (у меня на 130 тысячах элементов так и не получилось дождаться окончания запроса, пришлось брать справочник из примерно 100 элементов — это секунд за 10 отрабатывает). Поэтому, намного «дешевле» обойти рекурсивно всех родителей заданного элемента.
А по поводу вложенности — опять же, если спуститься на землю, то реальная вложенность какая бывает? Ну 3, ну 5, ну 10 уровней (никогда не видел). Получается, что и не нужны эти заоблачные соединения миллиона таблиц, в реальности, если брать запрос, то проще и правда нанизать одного родителя на другого и получить 3-5 запросов в пакете, но зато изначально отфильтрованных по нужному элементу.
(90) for_sale, вы верно подметили, что если стоит задача определения связей ОДНОГО элемента в ОЧЕНЬ БОЛЬШОМ и малоуровневом справочнике, то этот метод проиграет по быстродействию внезапросной технике или «бородатому» методу.
Это связано с особенностями предлагаемого метода, которые заключаются в том, что на промежуточном этапе метод вынужден оперировать со ВСЕМИ связями справочника. Если в справочнике 130 тысяч элементов и пять уровней, то связей там — больше полумиллиона. Естественно, три раза попарно соединить таблицы такого размера — не быстрое дело. Хотя и не бесконечно долгое. При этом дело не в «РАЗЛИЧНЫЕ» (это простая и линейная по отношению к размерам таблиц операция), а в соединениях (которые должны делаться через hash-match). Чуть позже я проведу эксперимент и покажу результаты на таком объеме данных и также покажу как без всякого обхода результатов вывести всех родителей одного элемента.
Не могу поверить, что справочник из 100 элементов обрабатывается 10 секунд. Тут у вас какая-то ошибка. Обработки на основе данного метода используются в самых разных задачах и в большинстве случаев показывают приемлемое быстродействие. Справочники до 5-10 тысяч элементов обрабатываются быстро.
Область применения данного метода, конечно, не безгранична, но все же достаточно широка. Например, контроль зацикливания или определение максимального уровня справочника или определение родителя верхнего уровня каждого элемента, где по любому требуется анализ всех связей. Ну или обработка справочников небольшого и ли среднего (до нескольких тысяч элементов) размеров в задачах определения связей даже одного элемента.
Еще практические примеры применения данного метода можно найти в статьях и .
(89)
Сергей, поддержу for_sale с одной стороны: вы когда-то начинали все эти матричные умножения с реальной задачи найти все спецификации и сделать полное разузлование. И в процессе ушли от этой задачи в область теории. Т.е. самая что ни на есть практическая задача с миллионами связей (может, единственная, может, нет, но точно — самая лежащая на поверхности) — так и осталась без должного внимания.
Я все ждал, когда вернетесь к практическим задачкам — но вы наоборот, все дальше уходите от практики 🙂
(92) AlexO, честно говоря, не помню, чтобы я собирался заниматься разузлованием, использую запросную технику. Наоборот, в споре с Ish_2 в обсуждении я стоял на стороне решения этой задачи с использованием кода. Да и сейчас остаюсь на тех же позициях, если говорить о практике. Из соображений гибкости и кучи всевозможных параметров спецификации в УПП сделались слишком сложными, чтобы анализировать их чисто в запросе. У меня нет клиентов, которые имеют проблемы с временем разузлования. Так что кажется, что эта задача на данный момент свою актуальность потеряла. Во всяком случае, для меня.
Насчет ухода от практики — стараюсь как могу не уходить от нее.
Присоединю ссылку на статью по данной теме: . Closure Table — это и есть таблица, получаемая методом транзитивного замыкания. В указанной статье ее предлагается хранить в БД, чтобы упростить выборку иерархических данных. Довольно очевидное решение.
Сергей,
ссылка не рабочая…
(95) hornet_X, извиняюсь, вот правильная ссылка: .
Интересно, что этим способом можно считать нарастающий итог, если в качестве исходных данных взять линейный граф, на дугах которого будут слагаемые. Расстояние от первой вершины и будет нарастающим итогом.
Конечно, это очень не эффективный способ именно для нарастающего итога, но если требуется рассчитать нарастающий итог не для сумм, а для произведений, то такое решение уже может принести пользу.
Вот запрос, считающий таким образом ряд степеней двоек до 16-ой степени включительно:
Показать
Если в таблицу дано записать рядом с номерами строк не двойки, а другие множители, то и получится нарастающий итог произведений без всяких логарифмов.
Если ряд большой (сотни элементов), то уже имеет смысл воспользоваться методом , который решит ту же задачу без избыточных операций.
Коллеги, а что думаете о таком варианте решения:
ВЫБРАТЬ
Номенклатура1.Ссылка КАК Ссылка,
ВЫБОР
КОГДА Номенклатура.Ссылка = Номенклатура1.Ссылка
ТОГДА 0
КОГДА Номенклатура.Ссылка = Номенклатура1.Родитель
ТОГДА 1
КОГДА Номенклатура.Ссылка = Номенклатура1.Родитель.Родитель
ТОГДА 2
КОГДА Номенклатура.Ссылка = Номенклатура1.Родитель.Родитель.Родитель
ТОГДА 3
КОГДА Номенклатура.Ссылка = Номенклатура1.Родитель.Родитель.Родитель.Родитель
ТОГДА 4
КОНЕЦ КАК Вложенность
ИЗ
Справочник.Номенклатура КАК Номенклатура
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура КАК Номенклатура1
ПО (ЛОЖЬ = Номенклатура1.ЭтоГруппа)
И (Номенклатура.Ссылка = Номенклатура1.Ссылка
ИЛИ Номенклатура.Ссылка = Номенклатура1.Родитель
ИЛИ Номенклатура.Ссылка = Номенклатура1.Родитель.Родитель
ИЛИ Номенклатура.Ссылка = Номенклатура1.Родитель.Родитель.Родитель
ИЛИ Номенклатура.Ссылка = Номенклатура1.Родитель.Родитель.Родитель.Родитель)
ГДЕ
Номенклатура.Ссылка = &КорневойЭлемент
Показать
Текст так же можно собирать циклом, а дописывание соединений в запросе к СУБД оставляем платформе и ее механизмам.
В отличии от метода автора, правда, за пределами языка запросов 1C неприменимо.
(41) вот так и кочуют ошибки по базам клиентов…на копипаст надейся да сам не плошай!))