






В предыдущей статье Введение в DOM или объектная модель документа было описано понятие объектной модели документа (DOM), раскрыты плюсы и минусы использования модели при разборе файлов XML, приведено сравнение с построчным последовательным разбором. Были представлены варианты выборки данных с помощью объекта 1С ДокументDOM. Теперь настало время познакомить читателей с самым, на мой взгляд, интересным способом извлечения данных из XML — при помощи языка запросов xPath (XML Path Language).
Модель DOM имеет древовидную структуру, зачастую ей проводят аналогию с организацией хранения файлов в папках, где каждый конечный узел сравнивают с файлом, нахождение которого заранее известно по пути до него через папки и подпапки. Не зря в названии языка присутствует слово «путь» (path в переводе с английского означает путь). Именно определение пути к данным лежит в основе xPath.
На вход конструкции xPath подается выражение, определяющее путь до искомых узлов, например такое «/someTag/someSubTag» (означает выборку всех элементов с именем someSubTag внутри элементов someTag, расположенных на первом уровне документа). На выходе образуется список найденных узлов. Список представляет собой коллекцию, которую можно обойти циклом и произвести манипуляции с узлами-элементами списка, например извлечь их значения.
Давайте подробнее остановимся на выражении xPath, определяющем путь, и его составных частях. Выражение состоит из так называемых шагов адресации (имен тегов), разделенных слэшем — косой чертой «/» и как уже было сказано выше — очень похоже на путь к файлу в файловой системе. Если путь начинается с «/», то это задает абсолютный путь к заданному элементу (от корня документа). Если же путь начинается с «//», то это означает произвольное (любое) количество уровней (от корня документа) перед искомым путем. Символ «*» в пути означает любой элемент, тот же символ в конце пути означает, что нужно выбрать все элементы по пути, указанному до этого символа, например «//someTag/someSubTag/*» (выбрать все элементы по пути /someTag/someSubTag, при этом расположение начала пути от корня документа не имеет значения и может начинаться на любом уровне).
Также в адресации могут использоваться квадратные скобки, которые задают более четкие критерии поиска, например «/someTag/someSubTag[1]» (первый элемент из найденных) или «/someTag/someSubTag[last()]» (последний элемент из найденных). Как видно, в квадратных скобках могут использоваться еще и специальные функции. Также в квадратных скобках могут задаваться условия на наличие у узлов атрибутов, на значение атрибутов, условия-отрицания и многое другое. Ниже приведена ссылка, по которой можно посмотреть различные варианты условий.
В 1С работа с xPath реализована через метод объекта ДокументDOM ВычислитьВыражениеXPath. Вариант синтаксиса языка 1с для работы с xPath приведен ниже:

Теперь для наглядности работы выборки xPath выражения посмотрите скриншоты ниже:




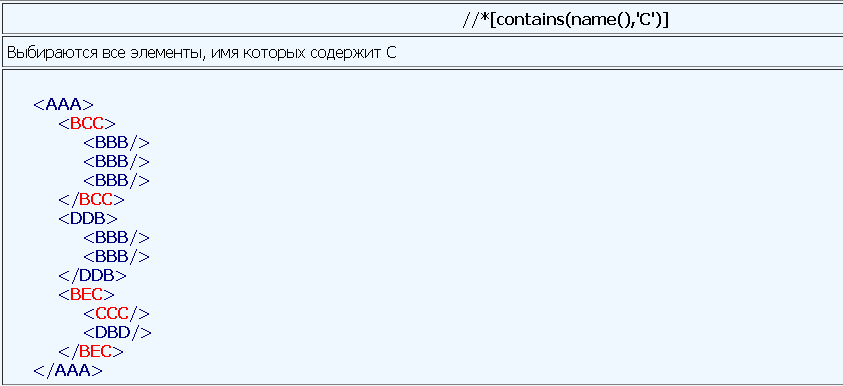
Углубиться в тему и посмотреть примеры (в т.ч. и более сложные) различных xPath выражений можно по этой ссылке.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Все классно, но как-то суховато. И еще непонятно где потерялся пример на языке 1с?
(1) пример есть в предыдущей статье
вы считаете, что нужно здесь повторить?
Оч короткие статьи. Это для того чтобы рейтинга больше срубить?
Тема хорошая, но не раскрыта совершенно.. ссылка на «углубиться» — вообще не «вставила».. но + пока авансом — в надежде на дополнение статьи..
Тихо «скиздил» и ушел — называется нашел? Это ссылка, а не статья.
Статья есть, а примеров кода нет. Пример файла отсутствует.
Единственный плюс от статьи — само понятие «ДокументDOM»
код как для эксполйтов написан, чтоб без напильника не работал — изначально не рабочий, т.к. половина определений пропущена в самом интересном месте «ВычислитьВыражениеXPath».
кармы не хватает, а так бы минусанул…
а примеров кода в 1с нету?
Тема абсолютно не раскрыта.Приведите пример из 1с
Исходный файл:
Показать
Код в 1с:
Показать
Результат окна сообщений:
Со звездочками уже сами поэкспериментируйте как-нть
Добрый день не могли бы вы проконсультировать один вопрос по статье , и использование xPath, вопрос заключается в том что есть узел
<point x=»529″ y=»82″>
мне надо найти его
если я пишу
.ВычислитьВыражениеXPath(«//shape/point[@x=»529″@y=»82″]»,…
выдает ошибку, как правлеьно задать выражение для поиска?
(11) glime, могу ошибаться, но похоже надо просто экранировать кавычки
.ВычислитьВыражениеXPath(«//shape/point[@x=»»529″»@y=»»82″»]»,…
или вообще их убрать
.ВычислитьВыражениеXPath(«//shape/point[@x=529@y=82]»,…