





Постановка задачи
Необходимо вывести расходные документы для которых на момент их проведения не хватает остатков на складе. Дополнительно нужно вывести товары, по которым не хватает остатков.
Интересна задача тем, что ее можно выполнить разными способами. Естественно, все они будут на СКД. Но инструменты будут разными:
- Получение данных одним запросом,
- Использование двух наборов данных (вложенные циклы средствами СКД),
- Применение внутренних функций СКД.
В конце статьи сравним эти способы и выберем наилучший.
Получать данные будем из конфигурации ЕРП 2.4, по регистру «Товары организаций». Причем разрез по организациям учитывать не будем. Достаточно разреза по складам и номенклатуре.
Способ первый (традиционный) — получение всех необходимых данных в одном запросе.
Если не знать ничего о возможностях СКД, он будет и единственным.
Для решения задачи используется один набор данных. Запрос, набора данных будет следующим:
Запрос для первого способа
Собственно все решение задачи содержится с этом запросе. По комментариям, думаю, можно без проблем понять его логику. Дальше просто выводим данные в отчет с детализацией по складу и номенклатуре.
На примере с 10000 документов отчет выполнялся достаточно быстро. Однако, при увеличении данных промежуточная выборка (соединение «ВТ_ Движения» самой с собой) будет расти в квадрате. В какой-то момент она может получиться очень большой, и скорость работы отчета будет не удовлетворительной.
Способ второй – использование двух наборов данных
Если честно, мне этот способ первым пришел в голову. Как увидим позже, в результате он является самым не оптимальным.
Помним про связь наборов данных с возможностью передачи параметров из одного набора в другой. Если кто-то забыл – смотрите статьи: Использование нескольких наборов данных в СКД и Простые примеры сложных отчетов на СКД.
Создаем два набора данных с простыми запросами:
1 набор «Документы»
//Выбираем все движения «расход» по регистру «ТоварыОрганизаций», с детализацией по аналитике учета номенклатуры
ВЫБРАТЬ
ТоварыОрганизаций.Регистратор КАК Документ,
ТоварыОрганизаций.АналитикаУчетаНоменклатуры КАК АналитикаУчетаНоменклатуры,
СУММА(ТоварыОрганизаций.Количество) КАК КоличествоВДокументе,
ТоварыОрганизаций.Период КАК Период
ИЗ
РегистрНакопления.ТоварыОрганизаций КАК ТоварыОрганизаций
ГДЕ
ТоварыОрганизаций.Период >= &ДатаНачала
И ТоварыОрганизаций.Период <= &ДатаОкончания
И НЕ ТоварыОрганизаций.Регистратор ССЫЛКА Документ.ПередачаТоваровМеждуОрганизациями
И НЕ ТоварыОрганизаций.Регистратор ССЫЛКА Документ.ПриобретениеТоваровУслуг
И НЕ ТоварыОрганизаций.Регистратор ССЫЛКА Документ.ОприходованиеИзлишковТоваров
И ТоварыОрганизаций.ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Расход)
СГРУППИРОВАТЬ ПО
ТоварыОрганизаций.Регистратор,
ТоварыОрганизаций.Период,
ТоварыОрганизаций.АналитикаУчетаНоменклатуры
УПОРЯДОЧИТЬ ПО
ТоварыОрганизаций.Период
2 набор «Остатки»
//Формируем остатки по переданной аналитике на переданную дату.
//Используем связь с таблицей КлючиАналитикиУчетаНоменклатуры так как остатков может и не быть вовсе.
//Накладываем отбор КоличествоОстаток < &КоличествоВДокументе, чтобы оставить только необходимые строки.
//Параметры &Период и &КоличествоВДокументе – необходимы в выходных полях, иначе их нельзя использовать для связей
ВЫБРАТЬ
ЕСТЬNULL(ТоварыОрганизацийОстатки.КоличествоОстаток, 0) КАК КоличествоОстаток,
&Период КАК Период,
&КоличествоВДокументе КАК КоличествоВДокументе,
КлючиАналитикиУчетаНоменклатуры.Ссылка КАК АналитикаУчетаНоменклатуры
ИЗ
Справочник.КлючиАналитикиУчетаНоменклатуры КАК КлючиАналитикиУчетаНоменклатуры
ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.ТоварыОрганизаций.Остатки(&Период, АналитикаУчетаНоменклатуры = &Аналитика) КАК ТоварыОрганизацийОстатки
ПО (ТоварыОрганизацийОстатки.АналитикаУчетаНоменклатуры = КлючиАналитикиУчетаНоменклатуры.Ссылка)
ГДЕ
КлючиАналитикиУчетаНоменклатуры.Ссылка = &Аналитика
И ЕСТЬNULL(ТоварыОрганизацийОстатки.КоличествоОстаток, 0) < &КоличествоВДокументе
Далее настраиваем связи между наборами как на картинке:
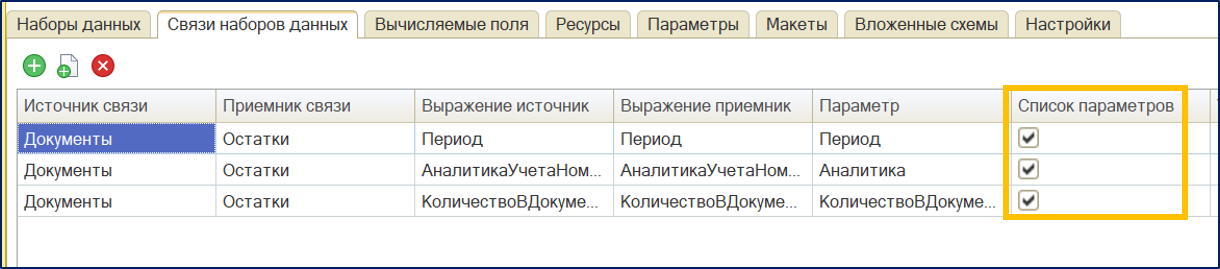
Данная конструкция является не чем иным, как запросами в цикле средствами СКД.
На моих данных (10000 документов) отчет выполнялся ЗНАЧИТЕЛЬНО дольше первого варианта. Однако, при увеличении объема данных, возможно разница по времени будет снижаться.
Есть еще один момент, который не делает второй вариант оптимальным. К сожалению, нет возможности передать во второй набор значение типа «МоментВремени», приходится передавать дату. Это значит, что если два расходных документа были проведены в одно и то же время, с точностью до секунды, расчет остатков не будет учитывать документ, проведенный в ту же секунду.
Способ третий – использование внутренних функций СКД
Система компоновки данных имеет много достаточно полезных встроенных функций. Более подробно, смотрите об этом в статьях: Внутренние функции СКД, Вычислить выражение и Агрегатные функции СКД, о которых мало кто знает.
Для решения текущей задачи очень удобно использовать встроенные функции СКД «ВычислитьВыражение» и «ВычислитьВыражениеСГруппировкойМассив».
Используем один набор данных и достаточно простой запрос:
Запрос для третьего способа
Дальше начинается самое интересное.
Создаем структуру отчета как на картинке:
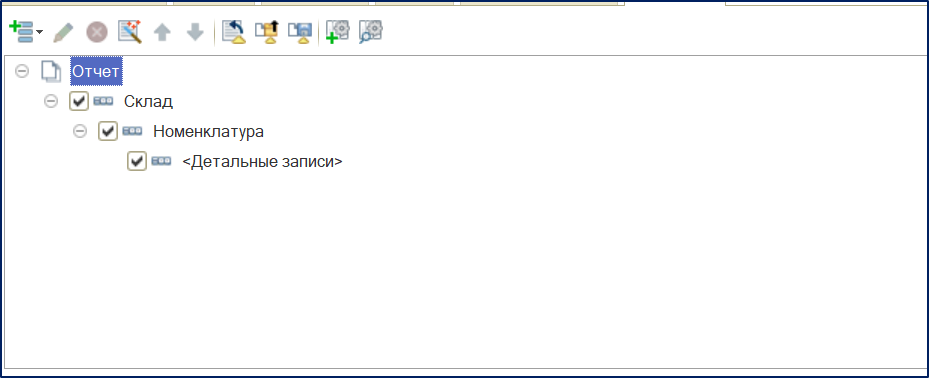
Создаем вычисляемое поле:
ОстатокПоДокументу = ОстатокНаначало + ВычислитьВыражение("Сумма(КоличествоПоДокументу)",,,"Первая", "Текущая")
Для каждой строки детальных записей будет рассчитан остаток нарастающим итогом (с первой по текущую запись).
Создаем один ресурс с разными выражениями для группировок «Склад» и «Номенклатура»:
Для группировки по Номенклатуре
МИНИМУМ(ВычислитьВыражениеСГруппировкойМассив("ОстатокПоДокументу", "Регистратор"))
Рассчитываются выражения поля «ОстатокПоДокументу» для каждой строки, и выбирается минимальное значение.
Для группировки по Складу
МИНИМУМ(ВычислитьВыражениеСГруппировкойМассив("МИНИМУМ(ВычислитьВыражениеСГруппировкойМассив(""ОстатокПоДокументу"", ""Регистратор""))", "Номенклатура"))
Выбираем минимальное значение из результата расчета по номенклатурам. Используем вложенные друг в друга функции СКД. По сути мы берем расчеты для каждой номенклатуры и выбираем из них минимальное значение.
Наверно дотошный читатель скажет, а почему бы не сделать так:
МИНИМУМ(ВычислитьВыражениеСГруппировкойМассив("ОстатокПоДокументу", "Номенклатура , Регистратор"))
Отвечаю:
Если сделать таким образом, то расчет функции «ВычислитьВыражение» будет выполняться не в контексте группировки по номенклатуре, а в контексте всего склада целиком. Это даст не верный результат, так что нужно именно так, как написано выше, используя вложенные функции.
И теперь самое интересное. Как наложить отбор на поле «ОстатокПоДокументу»?
Если отбор наложить на уровне отчета в целом (на уровне детальных записей) – будет выдано сообщение об ошибке типа «Выражение не может быть вычислено…».
Это связано с тем, что для детальных записей поля используется функция «ВычислитьВыражение», и отборы запрещены.
Однако можно использовать отборы по группировкам, и по группировке «Детальные записи» в том числе. Читайте об этом подробнее в статье Работа с настройками СКД. Для групповых отборов, можно использовать настройку «Применение — После группировки или для иерархии». Настройка позволяет корректно отрабатывать отборам по полям, в которых используются внутренние функции: «ВычислитьВыражение» и «ВычислитьВыражениеСГруппировкойМассив».
Используем этот механизм. Нам придется наложить отбор на уровне всех трех группировок: «Склад», «Номенклатура», «ДетальныеЗаписи»:
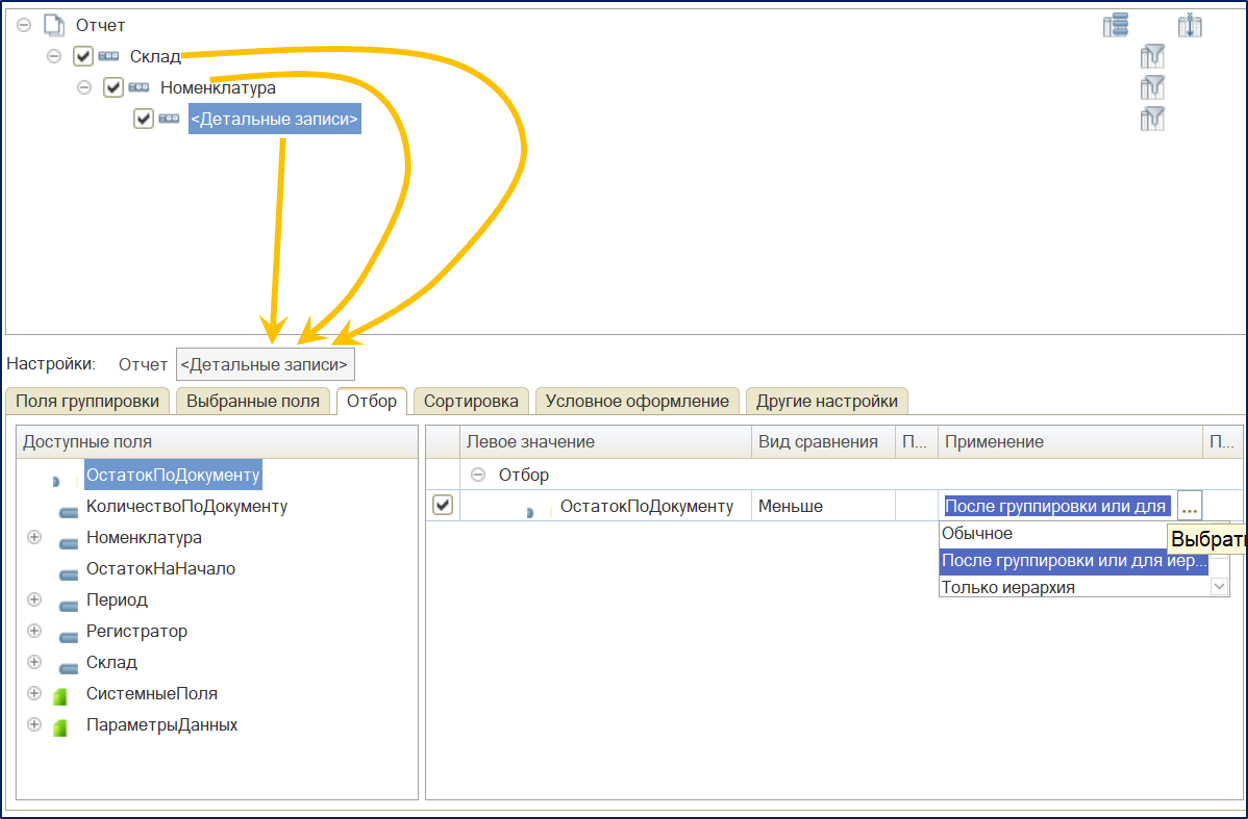
Чтобы информация об отборах не засоряла отчет, нужно указать в других настройках на уровне всех трех группировок «Вывод отборов = Не Выводить»:
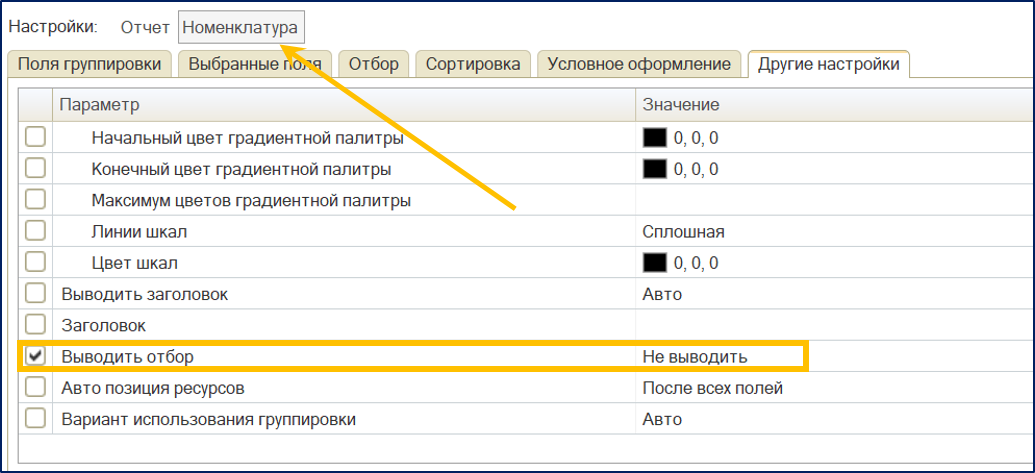
Но это еще не все. Если оставить отчет в таком виде, он будет выдавать данные в следующем виде:

После установки отбора по группировке «Склад» перестают корректно рассчитываться итоги по нижестоящим группировкам, и в отчет попадают лишние записи. Это связано со спецификой работы встроенных функций. Я склонен считать это ошибкой, возможно, это будет исправлено в будущих релизах.
На данный момент, чтобы убрать эти лишние записи, нужно добавить дополнительные отборы на уровне группировок:
- Номенклатура – «СистемныеПоля.Уровень = 2»
- Детальные записи – «СистемныеПоля.Уровень = 3»
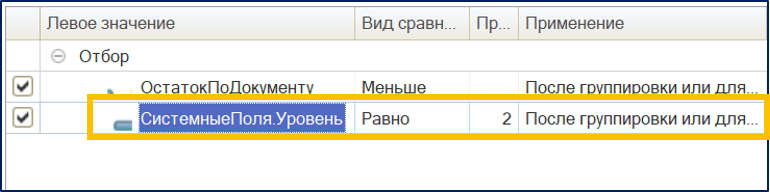
Вот теперь никакие лишние записи в отчет попадать не будут и он будет работать корректно.
Сравнение
Ну что же давайте сравнивать три описанных выше способа создания отчета:
По скорости:
|
Расчет в запросе |
Два набора данных |
Внутренние функции СКД |
|
10000 док. – 4,5 сек. 60000 док. – 62 сек. |
10000 док. – 90 сек. 60000 док. – 13 мин. |
10000 док. – 5 сек. 60000 док. – 45 сек. |
По сложности реализации:
|
Расчет в запросе |
Два набора данных |
Внутренние функции СКД |
|
Необходимо время на написания и отладку запроса. Скорость создания отчета зависит от умения строить сложные запросы. |
Средняя скорость создания отчета. Необходимо уметь работать с несколькими наборами данных. |
Если есть навык работы с внутренними функциям, отчет строиться очень быстро. |
Прочие нюансы:
|
Расчет в запросе |
Два набора данных |
Внутренние функции СКД |
|
Может получиться очень большая промежуточная выборка данных. |
Нельзя получить остатки на момент времени. Только с точностью до секунды. |
Нельзя менять структуру отчета. Алгоритм построения жестко привязан к структуре. |
Первый и третий способы на малом количестве данных по времени формирования идентичны. При увеличении объема данных, третий способ становиться быстрее, но не значительно. Но очень большом объеме картина может быть другая – не проверял. Третий способ самый быстрый в реализации (если конечно уметь пользоваться встроенными функциями СКД). Но есть нюанс – нельзя менять структуру выводимых данных. Тем не менее первый способ (традиционный) получился совсем не так плох, как могло показаться на первый взгляд. Ну а второй способ – по всем параметрам получился самым не оптимальным.
Пишите свое мнение в комментариях. Какой способ, на Ваш взгляд, является самым предпочтительным? Составим рейтинг J.
Ну или просто пишите свое мнение по поводу описанных выше вариантов решения.
Спасибо за внимание.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
как возможности вариантов реализации — добротная инструкция
детали, в которых кроется сами знаете кто
1. запросы во всех трех вариантах похожи по логике, но различны по содержанию.
посему статистика сравнения по этой причине имеет статус НЕ факта, а скорее статус декорации «ну вот так получилось»
2. Расчет остатков методом нарастающего итога в запросе хорош в примерах и методичках всяких там курсов, но на биг-дате — вешалка.
3. Важно насколько «шусрый» сервер СУБД который выполняет запросы и насколько шустры сервера приложений, которые
принимают на обработку в СКД, то что выдал первый. Иногда первый отработал шутсряком, а вторые не могут «скушать».
Я хочу сказать, что размеры БД конечно имеют значение и результаты на биг-дате могут быть совсем иные.
…
n. при оптимизации запросов в каждом варианте результаты также могут стать иными.
В общем, как инструкция хорошо, как догма не-не-не — в нашем мире все относительно, как говорил классик.
Первый способ!
Первый способ не всегда возможен. Например сумма более чем 20 полей превышает допустимую размерность длины формулы или колонки.
Способ второй – использование двух наборов данных — это запрос в цикле, что замер производительности и показывает. Выполняется запрос основного набора, далее для каждой строки результата выполняется запрос подчиненного набора данных. На продуктиве такое лучше не делать. И обычно можно второй способ свести к первому.
Также автор лукавит в таблице сравнения, можно например и так написать:
Внутренние функции СКД
Необходимо время на написание и отладку схемы компоновки. Скорость создания отчета зависит от умения строить сложные отчеты СКД.
Расчет в запросе
Если есть навык написания подобных запросов, отчет строиться очень быстро.
По сути, автор предлагает расчет нарастающего итога вынести на клиент и использовать для это ВычислитьВыражениеСГруппировкойМассив.
Это действительно будет работать. Но, во-первых, раз это клиент — скорость работы отчета будет зависеть и от параметров ПК клиента (ОЗУ, ЦП). А что, если это будет веб-клиент и запуск базы на планшете, к примеру?
Кроме того,
«После установки отбора по группировке «Склад» перестают корректно рассчитываться итоги по нижестоящим группировкам, и в отчет попадают лишние записи. Это связано со спецификой работы встроенных функций. Я склонен считать это ошибкой, возможно, это будет исправлено в будущих релизах.»
— не согласен.
Это не ошибка. СКД делает ровно то, о чем Вы ее просите. Вы ей сказали «считай вот это поле вот так, с учетом вот таких вот отборов». Как работают все эти функции СКД? Система получает результат запроса в виде плоской таблицы, затем начинает группировать строки так, как ей сказали, при этом рассчитывая вычисляемые поля тоже так, как ей сказали и накладывая те отборы (часть отборов может транслироваться в сам запрос при этом), которые ей дали. Так что никакой ошибки тут нет и надеяться на исправления в следующих релизах незачем.
Есть вопросы по второму способу.
Во-первых, Вы обращаете внимание читателя на флажки «Список параметров», однако в самом запросе используется условие на равенство аналитик, а не оператор «В». Мне не известно, СКД сама заменит «=» на «В», или же условие равенства так и останется?
Во-вторых, не могу сообразить, зачем связь со справочником ключей аналитики и условие сравнения с количеством прямо в запросе? Почему бы не получить остатки те, которые есть, а уже потом используя вычисляемые поля и отборы отфильтровать записи, где количество больше остатка?
Развейте, пожалуйста, мои сомнения, но кажется, что запрос второго набора данных составлен некорректно. Использование флажка «Список параметров» должно было привести к оптимизации получения данных, выбирая их разом для порции записей из основного набора данных. Но из-за условий в запросе подчиненного набора этого могло не произойти, и сам запрос в итоге выполнялся для каждой строки основного набора. Отсюда и следует столь длительное формирование отчета.
Есть вопрос по второму подзапросу в первом способе:
откуда вязалась ВТ_Документы ?
Четвертый способ — использование вложенных схем, пользовательских полей, ….
(7)Опечатка. Поправил.
(5)
Почему Вы считаете, что расчет нарастающего итога будет выполнятся на клиенте, не понимаю…
(5)
Может и не ошибка, а «нюанс» — грань тонкая.
(6)
Вы совершенно правы, СКД сама ничего не заменяет. Для оптимизации нужно условие в списке, я проглядел этот момент. Хотя в данном конкретном случае, оптимизации все равно не будет, так как есть еще отбор по количеству. Может быть будет быстрее, если сделать отбор по товарам списком и вынести отбор по количеству на уровень настроек СКД — не проверял.
(6)
А зачем выбирать лишние записи? Номенклатуры может быть очень много и для каждого документа будут выбираются остатки по всем товарам…
(8)Примерчик не напишете?
(11)
Как раз для того, чтобы выбирать данные порциями, а не для каждого значения параметра «Количество».
Тут еще остается, конечно, «темный» вопрос, связанный с параметром «Период». Помнится, на курсах по СКД Белоусов рассказывал, что флажок «Использовать список» также оптимизирует запрос и для параметра «Период», но каким именно образом не расшифровал. Моя догадка такая: СКД собирает из основной таблицы все значения периода и выполняет столько запросов подчиненного набора данных, сколько различных значений периода удалось собрать. Если это так, то в представленной Вами задачи такая оптимизация будет бесполезна — повторяющихся периодов практически нет, ведь мы выбираем в основном наборе все движения за указанный временной интервал.
Необходимость знания большого количества нюансов лично для меня отталкивает варианты использования всех возможностей СКД. Если браться за СКД раз в полгода, то лучше использовать более простой, но зато «железный» вариант (чтобы не пошел отчет в «пешее эротическое путешествие» при применении какого-нибудь отбора). Ну а если постоянно заниматься СКД и владеть всеми нюансами на кончиках пальцев — тогда да, раз-два — отчет готов и он оптимален.
(14)Согласен с Вами.
(13)
Так в любом же случае отбор по аналитикам учета нужен или по одной позиции или списком. Если список, тогда отбор по количеству нужно переносить на уровень настроек компоновки.
(13)
Тоже слышал о такой оптимизации. Но как она точно работает нигде не нашел информации. Возможно, как Вы написали, возможно нет — загадка компании 1С.
(16)
Ну так о том я и толкую в первом своем сообщении. 🙂
(12) вложенные схемы? Ну вот есть у вас отчет, например, по разным группам доходов и расходов, собираемый из разных мест. Можно городить кучу объединений, а можно сделать несколько вложенных схем и их скомпоновать в один макет. Собсно, ничего сложного…
(18) Может статью набросаете? Интересно было бы посмотреть.
А в 3-м способе менять группировки местами можно будет ?
(20)Нет, структура жесткая. Иначе отчет нужно будет переделывать.
(0) А индексация временных таблиц в 1-м и 3-м варианте разве не уменьшит время выполнения запроса? Или СКД самостоятельно индексирует временные таблицы?
(22)На счет индексации временных таблиц вопрос очень не однозначный. С одной стороны есть ускорение, но с другой стороны нужно время на создание самого индекса. Нужно пробовать, и смотреть что получается.
Я не пробовал.