

Бывают ситуации, когда необходимо загрузить выгрузку из сервиса DataDump, но после долгого ожидания процесс прерывается из-за того, что в выгрузке оказалась информация по метаданным, которых нет в вашей конфигурации.
Текст ошибки может начинаться с фразы "При загрузке данных произошла ошибка: Ошибка при чтении данных из файла" и включать фразу "Отсутствует отображение для типа" и далее идет описание типа, которого нет в вашей конфигурации и много букв еще. И если вы загружаете как положено — в тот же релиз, из которого была сделана выгрузка, то ошибка может появиться потому, что в исходной базе были не типовые объекты. А если выгрузка была сделана не из 1С-ного фреша, а из какого-либо другого сервиса, в котором его авторы внесли свои подсистемы в типовые конфигурации, то такое вполне может произойти. Я с таким часто сталкиваюсь. В таком случае можно распаковать архив с дампом, найти нужный файл xml (его наименование обычно сообщается в тексте ошибки), и удалить лишние узлы. Но если проблемных мест много, то эту процедуру можно повторять много раз. Каждая загрузка дампа занимает немало времени (зависит от его размера конечно) и в итоге можно заниматься этим долго.
Для таких ситуаций я накропал для себя обработку, которая ищет имена метаданных в именах, атрибутах и значениях узлов файлов дампа и проверяет, есть ли такие метаданные в данной базе. Если не находит — выводит их имена и файлы, где они находятся.
Таким образом можно сразу исправить все проблемные места.
Выложу ее сюда, если кому пригодится.
Она довольно сырая, буду дорабатывать по мере необходимости и поступления новых проблем с выгрузками.
Как работает
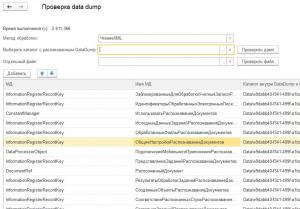
- Распакуйте архив выгрузки (по-умолчанию Data_Dump.zip) в какую-либо папку
- Откройте данную обработку в базе, в которую собираетесь загружать выгрузку
- Для проверки всего дампа выберите папку с распакованной выгрузкой в поле "Выберите каталог с распакованным DataDump ом" и нажмите кнопку Проверить дамп
- Для проверки одного файла выберите его в поле "Отдельный файл" и нажмите кнопку проверить файл
- Дополнительно можно выбрать метод чтения файлов xml — ЧтениеXML или DOM (я сталкивался с тем, что DOM выедает много памяти на больших файлах, так что возможно и ЧтениеXML когда-то пригодится)
- В таблице ниже будут выведены метаданные, которые не были найдены в данной базе и файлы, в которых эти записи находятся.
Остается только отредактировать эти файлы. Этого обработка сделать пока не может.
Помните, если вы удаляете какой-либо файл из папки Data целиком, то нужно удалить запись о нем в файле PackageContents.xml
Обдуманно подходите к удалению данных! Не удаляйте ничего наугад, если не уверены, можно ли это удалять! В противном случае вы можете потерять нужные данные. Всегда делайте резервные копии файлов, которые хотите поломать!
Обработка работает на управляемом интерфейсе, открывается методом файл->открыть, в дополнительные обработки не добавляется (считаю это лишним), так что у пользователя должны быть права интерактивно открывать внешние обработки
Тестировалась на платформе 8.3.15.1656 в бухгалтерии 3.0.72.72.
Не привязана ни к каким БСП и должна работать в любой конфигурации на платформе 8.3.
Код обработки открыт, можно править и копировать.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале