

Меня зовут Репников Олег. Я работаю в компании «Вымпелком» – владелец торговой марки «Билайн». На слайде написана моя должность, чтобы вы настроились, что у нас все крупное, все по-взрослому, и должности у нас тоже большие.

О чем я буду говорить? Кратко на слайде написал. Мы поговорим о компании, я расскажу про архитектуру, о том, как мы информируем себя о сбоях системы, о том, что мы используем «Центр контроля качества», про Grafana и про замеры производительности.
О компании «Билайн»
Компания Вымпелком – владелец торговой марки Билайн.
Кроме того, что мы являемся сотовым оператором и входим в большую тройку, у нас есть еще собственная сеть салонов, в которых мы обслуживаем наших абонентов и продаем оборудование. На слайде написано – более 3000 салонов. Полторы недели назад было 3072. Понятно, что часть открывается, часть закрывается. Поэтому так относительно написано.
И больше 8000 клиентских сессий – это означает не количество пользователей в базе, а именно количество одновременных клиентских сессий. Понятно, что некоторые пользователи могут зайти с одной рабочей станции два раза. Но это именно не спящие сессии.
Немного цифр.
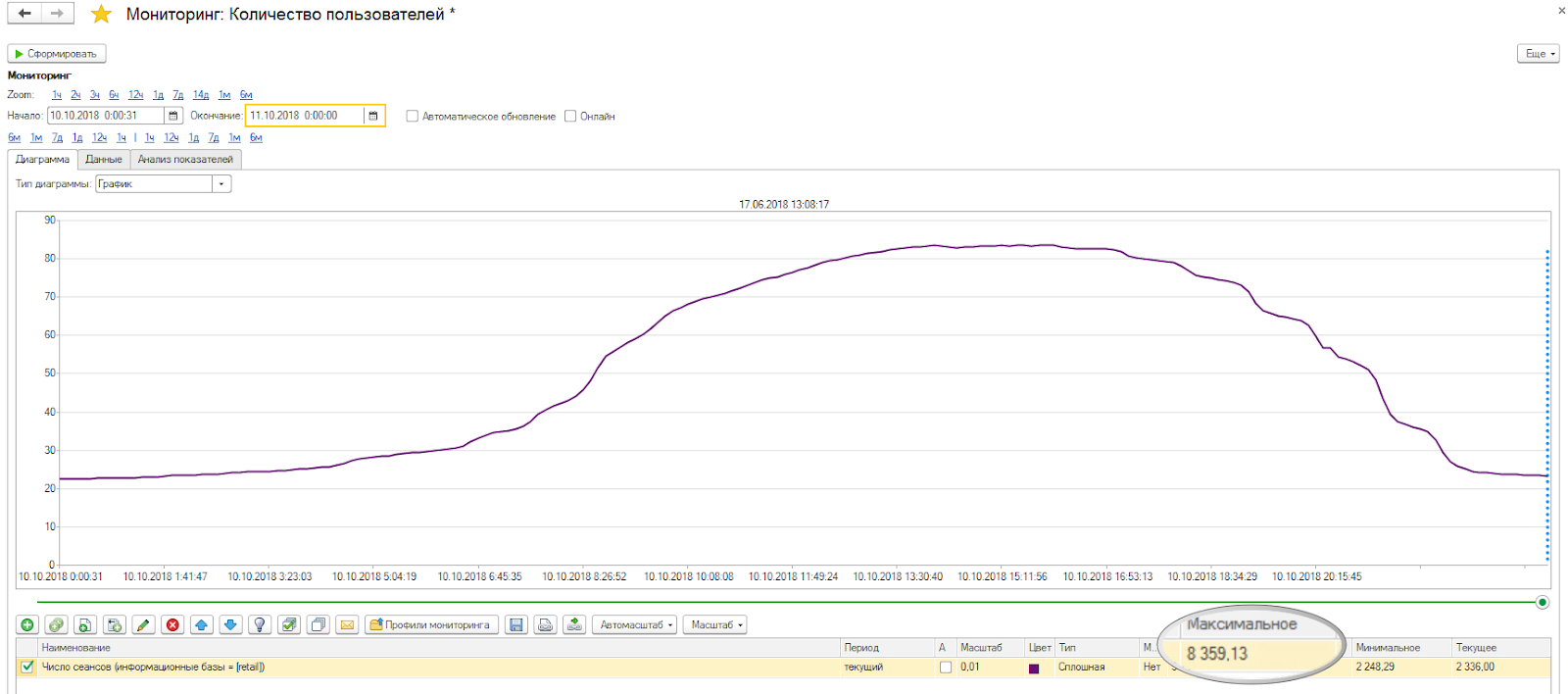
На слайде показан график количества пользователей в базе в течение одного дня. Он начинается от 2000 и достигает пика на 8000. Так как у нас салоны расположены от Камчатки до Калининграда, то количество пользователей растет постепенно – пользователи просыпаются, заходят в систему, а в 10-11 часов утра система достигает пика количества пользователей. И когда засыпает Дальний Восток, Сибирь – пользователи постепенно выходят.
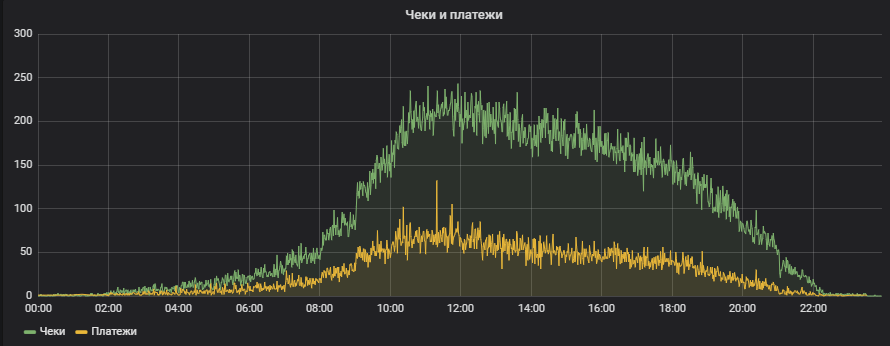
Количество транзакций лучше всего мерить чеками. У нас есть два основных показателя – это количество пробитых чеков и количество принятых платежей. Этот график показывает количество пробитых чеков в минуту. В пике у нас примерно 200-250 чеков в минуту.
Количество чеков мы меряем прямыми запросами к базе данных MSSQL. Это было наше изначальное условие, что система мониторинга никак не обращается к 1С, чтобы, вне зависимости от того, работает 1С или не работает, мы всегда могли получить нужные нам данные. Для этого мы используем прямые запросы. По лицензионному соглашению мы не имеем права этого делать, но, поскольку к основной базе мы не обращаемся, а используем прямые запросы к резервной ноде – таким образом, мы лицензионное соглашение 1С обошли.
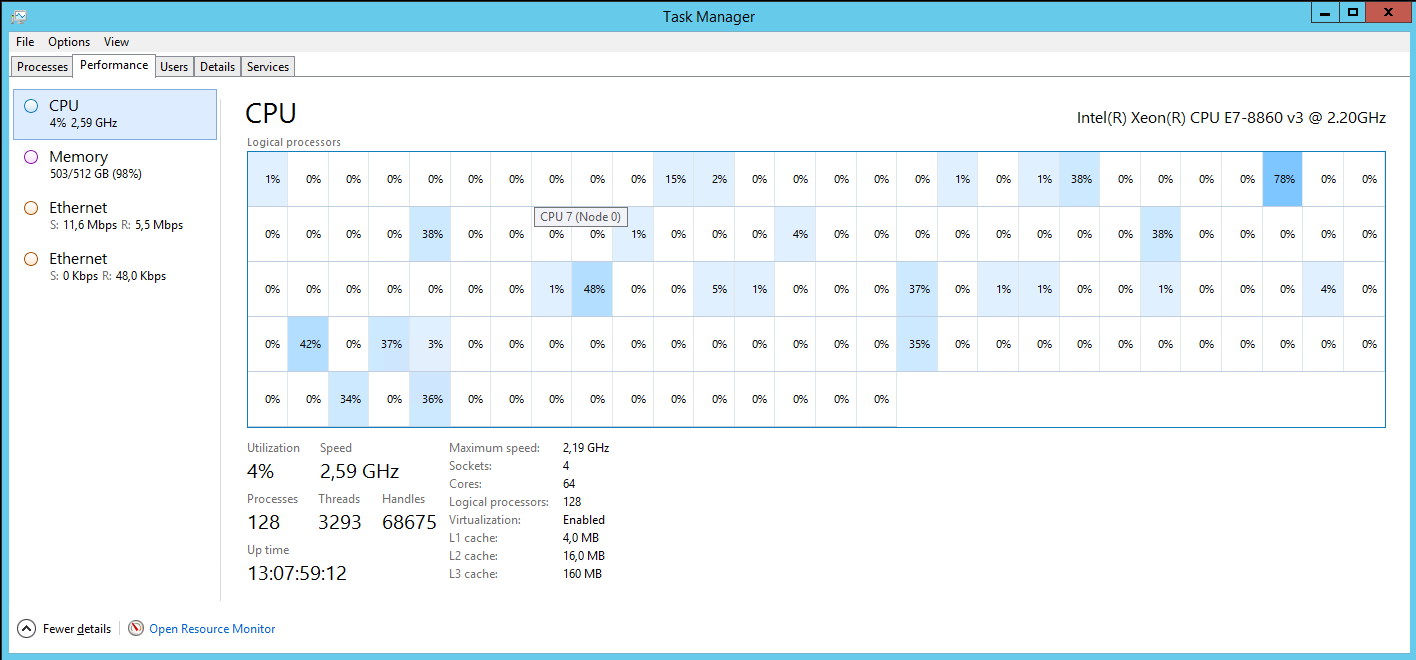
И последняя картинка – это наш график SQL-сервера. На нем видно количество ядер, количество памяти и относительная нагрузка.
Архитектура «крупными мазками»
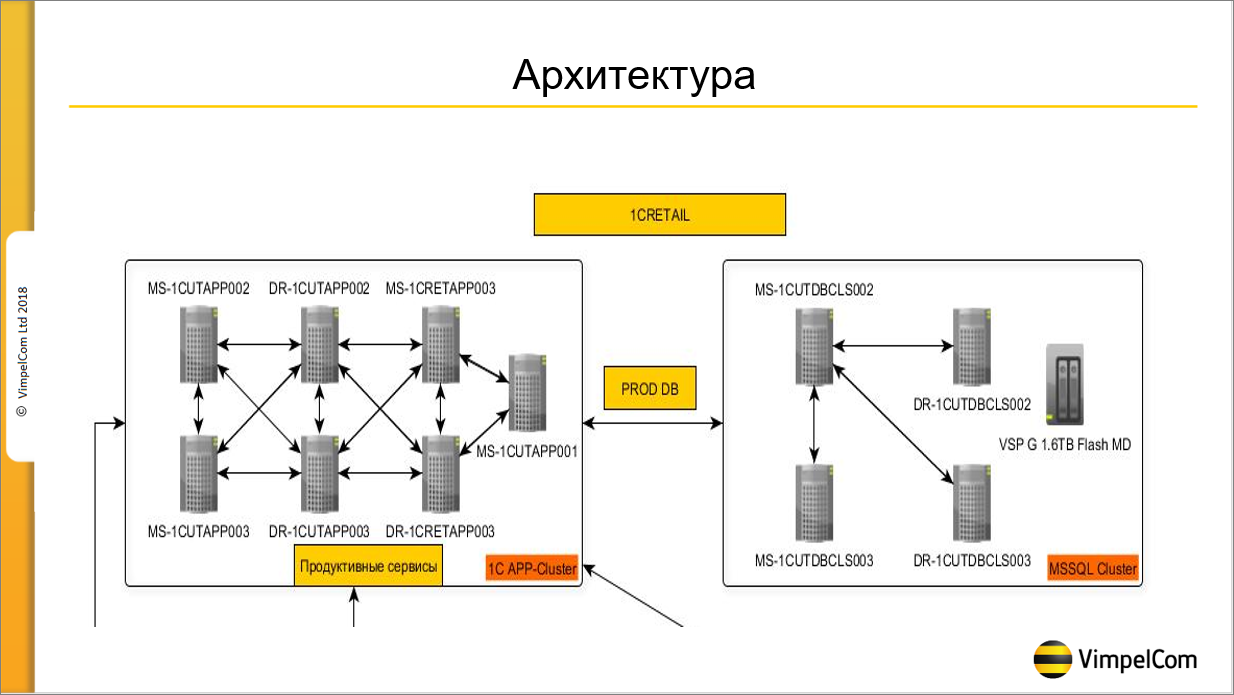
Архитектура у нас достаточно интересная. Мы к ней долго шли. Сейчас мы считаем ее вполне стабильной. На слайде схематично показано, как она выглядит:
Слева application-сервера – 6 application-серверов и один сервер, который обслуживает различные HTTP и веб-сервисы. Application-сервера расположены в двух ЦОДах, которые находятся в разных концах Москвы. У нас есть третий ЦОД, который находится в Ярославле, мы пытались его использовать – поставить на нем application-сервера, но, к сожалению, сетевая задержка оказалась слишком велика, она уже чувствовалась. Поэтому оба ЦОДа у нас находится в Москве – три application-сервера в одном ЦОДе, и три application-сервера в другом ЦОДе. Два сервера центральных, остальные сервера рабочие. Фоновые задания у нас выделены на отдельный сервер, а пользователи обслуживаются оставшимися пятью серверами.
А справа на слайде показана структура SQL-кластера. Он построен из 4-х нод. Две ноды работают в режиме Synchronous commit (то есть, до тех пор, пока транзакция не закоммитится на обоих серверах, она не завершится). И вторые два сервера работают в асинхронном режиме (Asynchronous commit).
Информирование о сбоях

Мы используем собственную самописную систему информирования о сбоях.
Почему мы не стали использовать промышленную систему – Zabbix, Nagios и пр.? Естественно, что у нас в компании есть крупная корпоративная система мониторинга, которая обслуживается большим количеством сотрудников, вендор этой системы нас поддерживает и т.д. Но, так как у нас обслуживаются десятки тысяч вышек, на каждой из которой есть железное оборудование, подключенное к системе мониторинга, то здесь включаются различные корпоративные правила. То есть, для того, чтобы войти в корпоративную систему мониторинга, нужно выполнить ряд требований, которые мы на старте проекта выполнить не могли. И когда мы пришли и сказали: «Мы хотим мониторить нашу систему», нам сказали: «Напишите метрики, которые вы хотите мерить, и недели через две мы их включим в свою систему мониторинга». Но на тот момент мы еще сами не знали, что мы хотим мониторить. Понятно, что нагрузку на процессор, нагрузку на память, количество транзакций и т.д. – это было очевидно, это стандартные метрики. Но есть ряд метрик, про которые мы не знали, будем мы их мониторить или нет.
Поэтому три года назад мы начали «колхозить» – разрабатывать собственную систему мониторинга. Она у нас полностью самописная, собирается из различных модулей, которые пишутся на C#. Кроме этого мы, естественно, используем «Центр контроля качества».
Как сейчас работает наша система мониторинга?
В случае какого-либо события сообщение о нем приходит по трем каналам – это почта, SMS и RocketChat, который мы используем в качестве корпоративного средства общения. По-моему, в других системах мониторинга по умолчанию такого нет, наверное, это настраивается – отличие нашей системы мониторинга в том, что она – спамер. Когда я показывал свою презентацию моим коллегам, они сказали, что основной вопрос будет – почему она у тебя постоянно спамит?
Что значит спамит?
В случае если система мониторинга видит, что в 1С не пробито ни одного чека, хотя чеки должны пробиваться, она напишет сообщение – в RocketChat, в SMS, в почту. Если через минуту она увидит, что чеки так до сих и не поступают, она напишет еще одно сообщение. И так будет происходить до тех, пока мы систему не починим. Это приводит к тому, что в случае серьезных аварий, которые длятся час, в почте творится полный хаос, потому что все заспамлено. Правильно так делать или неправильно – сложно сказать. Меня, как руководителя техподдержки, такая система устраивает, она не дает расслабляться.

На слайде видно, как выглядит сообщение об ошибке. Мы используем английский язык, так сложилось.
-
Первое слово в теме сообщения – ALARM (может быть либо ALARM, либо SUCCESS – либо ошибка, либо все хорошо). Следующее слово Check показывает, что мы мониторим чеки.
-
Далее – 13:18. Avg 142 (average – среднее значение). Это означает, что на 13 часов 18 минут среднее значение чеков за последний месяц было равно 142.
-
*current 0* – это означает, что за текущую минуту чеков было 0.
-
Далее мы видим минимальное и максимальное значение в эту минуту за последний месяц.
-
Period 30 days – за какой период берется статистика.
-
Threshold 44 – при каком значении система будет срабатывать. Если количество чеков больше 44, система не сработает. Если меньше, то система сработает. Это значение мы подбирали опытным путем, потому что пытались избежать ложных срабатываний. Например, когда среднее значение в эту минуту за последний месяц – 10 чеков, то если пробили 7, не понятно – авария ли это? Поэтому подбирали опытным путем.
Что мы мониторим?
-
Критические аварии – это полное падение системы, когда нет ни чеков, ничего – пользователи не могут зайти, и не могут пробивать.
-
Отсутствие платежей.
-
И, так как мы тесно интегрированы с биллингом (биллинг – это основная система сотового оператора), то, естественно, любая ошибка, связанная с биллингом, для нас тоже является критичной. В этом случае мы получаем сообщения каждую минуту.
Центр контроля качества
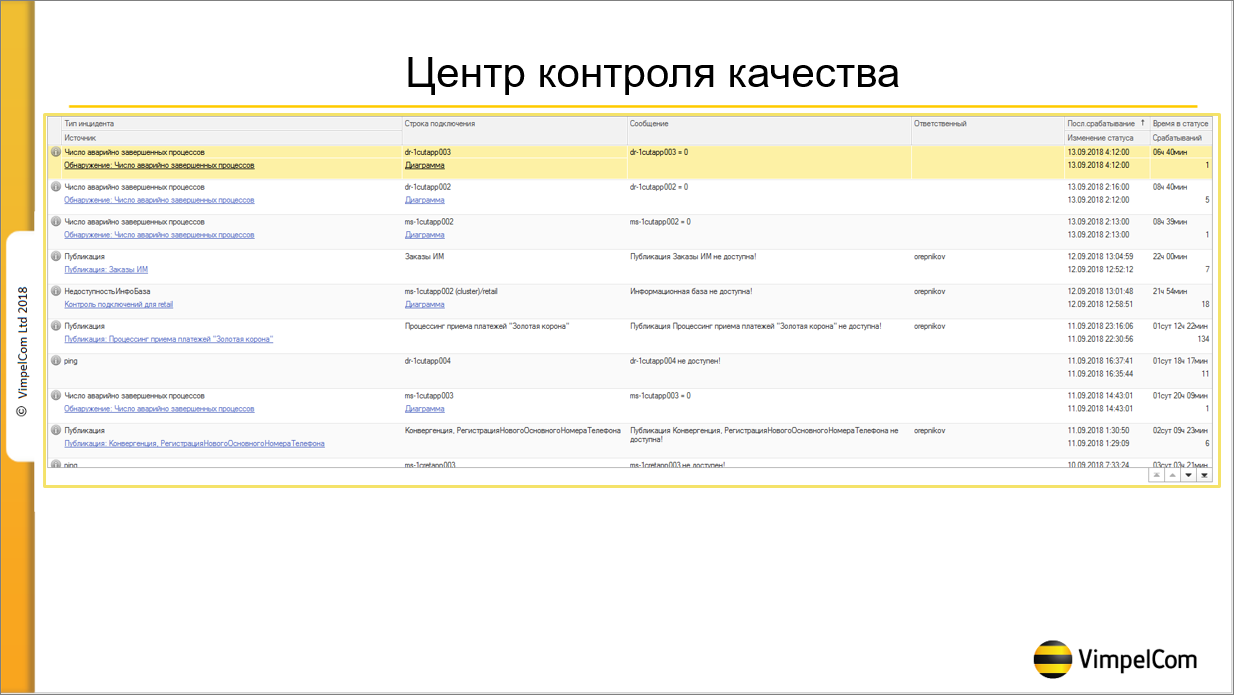
Про «Центр контроля качества»
Когда я пришел на проект, «Корпоративный инструментальный пакет» был нами уже куплен. Я решил посмотреть на «Центр управления производительностью» – инструмент, с помощью которого можно ловить таймауты, дедлоки, искать их причины. Мы его запустили и поняли, что «Центр управления производительностью» на крупных системах использовать нельзя. Конечно, официального ответа от 1С у меня не было, но в неофициальных беседах мне сказали, что не стоит использовать «Центр управления производительностью» на крупных системах, где замеры технологического журнала составляют десятки гигабайт, потому что «Центр управления производительностью» ставит свой технологический журнал, и он не всегда хороший. Структура технологического журнала – серьезная задача, она подбиралась нами около полугода, чтобы получить нужную нам информацию, не нагружая дисковую систему. То есть, мы отказались от «Центра управления производительностью».
«Центр контроля качества» мы не использовали, так как писали свою систему мониторинга. Но в один прекрасный день мы запустили проект ЦКТП с 1С, и ребята из ЦКТП сказали, что одно из условий работы в проекте – это использование конфигурации «Центр контроля качества».
Оказалось, что «Центр контроля качества» даже чем-то похож на Zabbix. Там есть агент, который будет собирать информацию – его можно поставить на свои сервера и на рабочие станции. Этот агент умеет собирать из коробки различную статистику, которая нам интересна. Он умеет по умолчанию собирать дампы rphost и т.д. (те самые дампы, в которые иногда падает платформа, и которые нам нужно передать нашему партнеру 1С-Рарус и фирме «1С», чтобы они смогли найти причины). Все это умеет делать «Центр контроля качества». Казалось бы, ерунда, настроим и будем собирать ту информацию, которая нужна. Но, к сожалению, оказалось, что «Центр контроля качества» очень сложен в настройке. Точнее, он неинтуитивно понятен.
Мне повезло – дело в том, что, после того как мы запустили проект ЦКТП, у меня в скайпе появился разработчик «Центра контроля качества». Я задавал ему кучу глупых вопросов, и примерно через месяц мы, наконец, настроили систему так, чтобы она собирала все нужные нам данные. Наверное, если бы я внимательно прочитал документацию, я справился бы самостоятельно, но документацию обычно читают, когда уже все сломалось.
Я рекомендую настраивать «Центр контроля качества» на крупных системах, потому что, немного помучившись, вы сможете собирать много нужной информации. И это хорошо, если она вам не пригодится – потому что, если вам пригодилась информация из «Центра контроля качества», то значит, у вас произошла какая-то авария, и вы пытаетесь разобраться в ее причинах. Поэтому мы ЦКК поставили, полгода в нее не заходили, а потом через полгода, когда у нас происходит какая-то авария, мы смотрим, что изменилось с момента последней аварии.
Итак, для чего мы используем «Центр контроля качества»?
-
С помощью «Центра контроля качества» мы собираем доступность серверов – у нас на всех серверах установлены агенты ЦКК и, соответственно, мы собираем информацию об их доступности.
-
Мы собираем основные метрики – такие, как ЦПУ, память, нагрузка на диск.
-
Мы собираем метрики SQL, такие, как количество дедлоков и количество таймаутов.
-
Кроме этого, есть отличная возможность развернуть в контролируемой базе веб-сервис, вызывая который, можно в «Центре контроля качества» писать любые метрики, которые интересны.
-
«Центр контроля качества» служит у нас базой данных для хранения всех наших метрик. Потому что, кроме того, что мы хотим эти показатели мерить, мы хотим эту информацию где-то хранить – мы ее записываем в ЦКК. Мы меряем количество управляемых блокировок, произошедших за час, среднее время дедлоков. Хранить эту информацию нужно, потому что если пользователи вдруг начали жаловаться, всегда можно зайти, посмотреть, что изменилось за последний час, за последний день, за последние полгода.
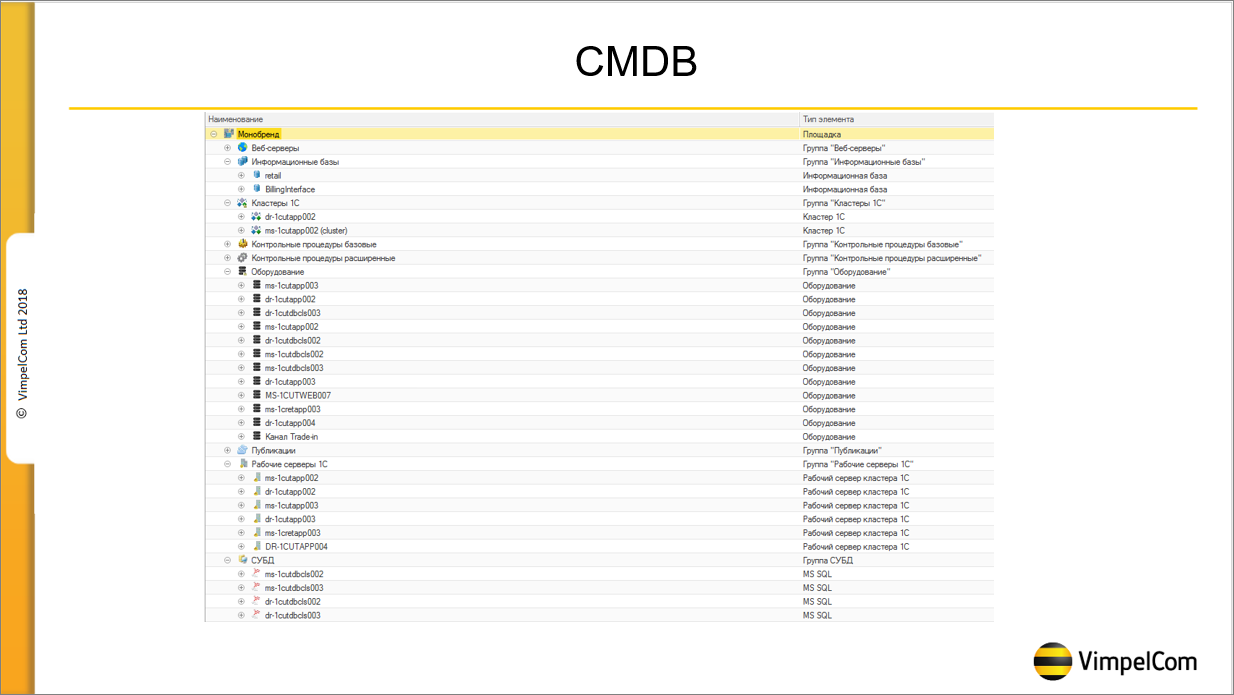
Кроме того, мы используем «Центр контроля качества» как CMDB.
Здесь указаны все наши сервера, все наши площадки – у нас есть тестовая площадка для разработчиков, есть площадка для нагрузочного тестирования, есть боевая площадка.
Я не разработчик, я больше администратор, девопсер. И когда разработчики просили поднять SQL-базу для тестирования (нужно было что-то потестировать, а на файловой базе не получалось) у нас была большая проблема, потому что через полгода этих баз становилось 50, и разобраться в них было нельзя – нужны они или не нужны. А с тех пор, как мы стали сначала заводить базу в CMDB и только после этого отдавать ее в разработку, у нас более-менее установился порядок, потому что в CMDB можно прописать, кому принадлежит база, до какого времени ее хранить и прочее.
Что мы не используем в «Центре контроля качества»?
-
В «Центре контроля качества» мы не используем работу с инцидентами, потому что у нас есть своя корпоративная система.
-
И мы не используем графики – я за это долго боролся с 1С, потому что графики в 1С вырвиглазные. Вроде они что-то поправили в последних релизах платформы, но мы к тому времени уже договорились с ними, что в качестве графиков используем Grafana (благо, она настраивается за полтора часа и в пятой версии умеет поддерживать MS SQL).
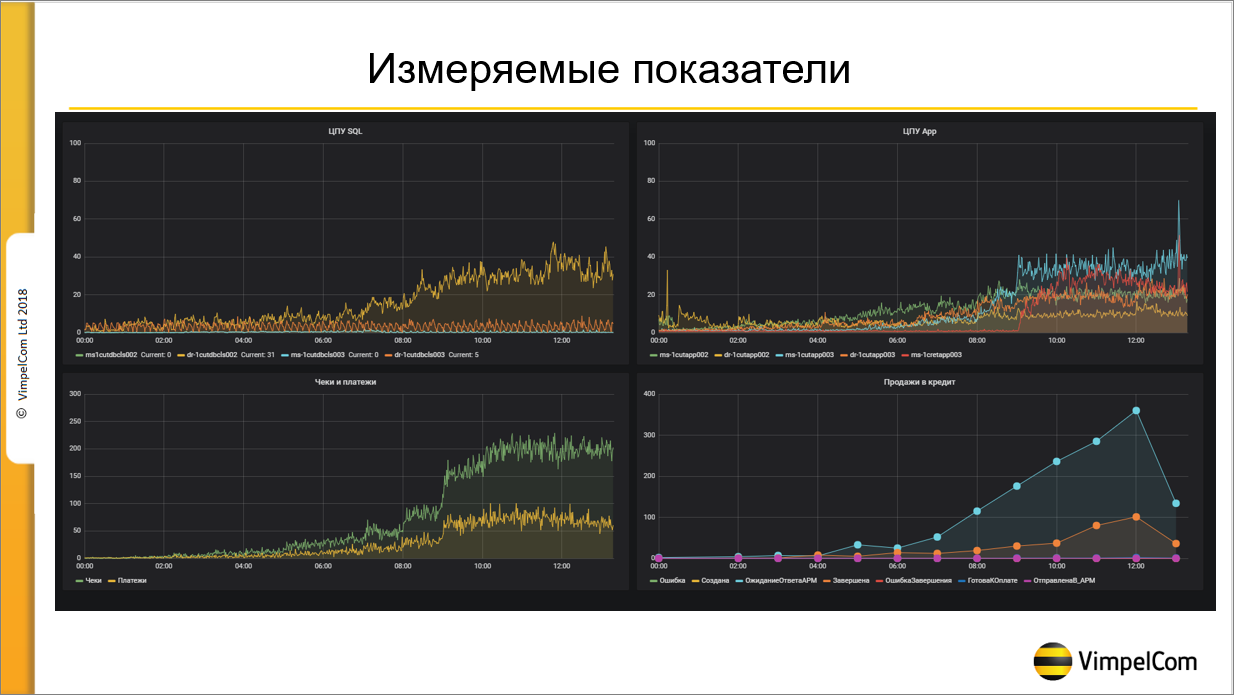
Вот как раз Grafana. Здесь видны измеряемые показатели – это всего лишь 4 графика, на самом деле их гораздо больше.
Видно, как отражается нагрузка на ЦПУ, на Application-сервера, чеки, платежи и количество продаж в кредит – это тоже один из показателей, который нам достаточно важен.
Почему мы не используем Apdex, и как мы измеряем SLA
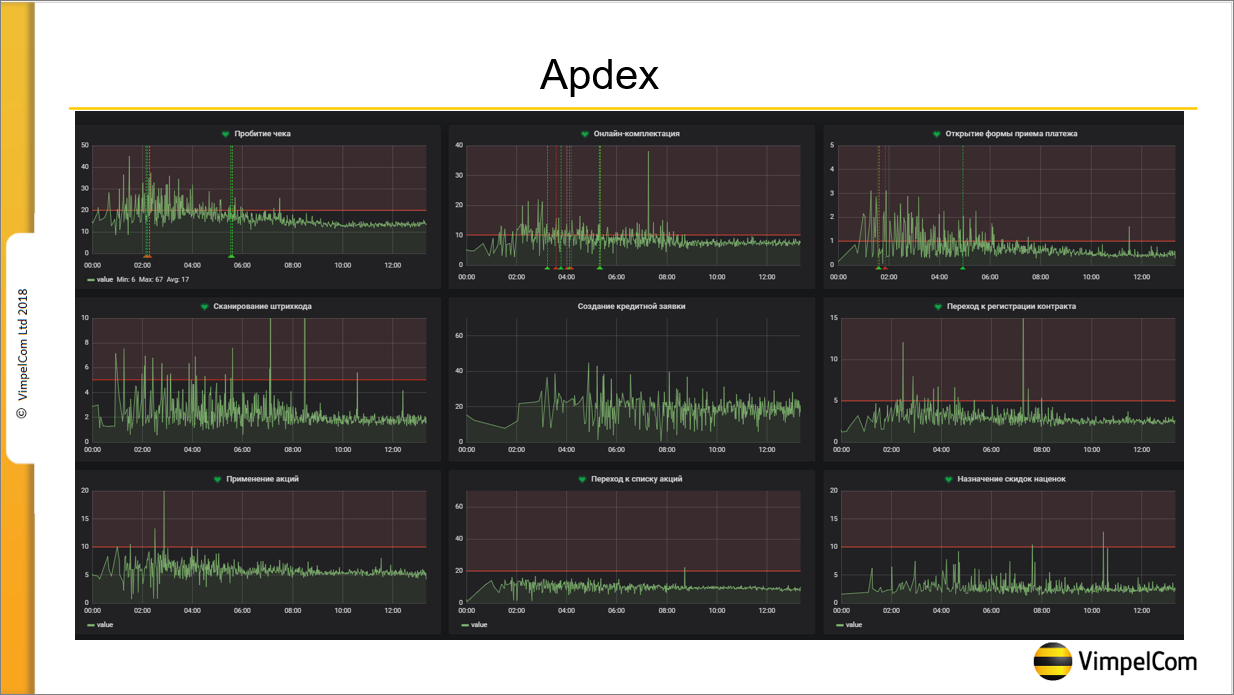
Немного про Apdex
С Apdex в терминологии 1С (когда мы что-то складываем и делим на 4, и в итоге получаем какую-то цифру, которую показываем бизнесу и говорим, что это – хорошо, нормально или плохо) у меня отношения не сложились изначально.
Дело в том, что Apdex можно использовать, когда у вас есть заказчик, который говорит, что он, допустим, хочет, чтобы чеки пробивались за 2 секунды. У нас такого заказчика в компании нет – у нас нет человека, который будет готов за это заплатить. Потому что оптимизация может стоить больших денег. Желающих, чтобы все было быстро – много, а людей, готовых за это платить – не очень. Поэтому мы Apdex не используем.
Мы используем 1С-ные замеры, по которым у нас меряются ключевые операции. На данном слайде у нас 9 ключевых операций, на самом деле их порядка 40.
Все эти замеры мы выводим в Grafana, и, глядя на график, в случае аварии можно определить момент ее начала. Например, на графике видно, что до 8 часов утра показатели не очень хорошие – это связано с тем, что в это время работает Дальний Восток и Сибирь, а сервер у нас находится в Москве, каналы связи не идеальные, код не идеальный, большое количество серверных вызовов. Поэтому до 8 часов утра показатели не самые лучшие. Но после 8 часов утра, когда просыпается Москва, графики выравниваются.
Красные линии, которые видны – это показатели, к которым мы стремимся. Это то, о чем мы договорились с бизнесом, что мы стараемся не нарушать эти показатели. Формально – это те самые замеры Apdex, но саму итоговую цифру мы не смотрим.
Замеры производительности основных операций
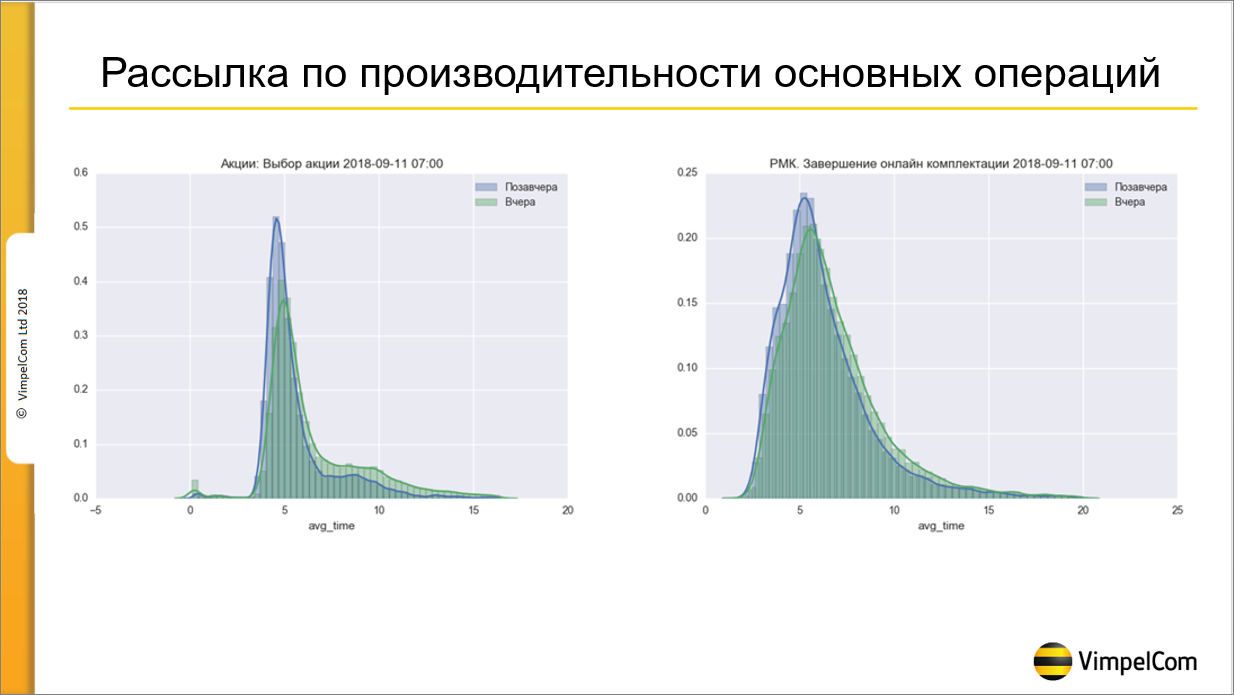
Вот такая рассылка у нас приходит ежедневно. Здесь – два графика. Сейчас их приходит порядка 40. Рассылка отправляется на ключевого заказчика от бизнеса, на меня и на ведущих администраторов системы.
Здесь два графика – как вел себя замер вчера и позавчера. С помощью него можно увидеть, что, например, за вчерашний день мы провалились по производительности, или, наоборот, у нас улучшилась ситуация.
Мониторинг журнала регистрации
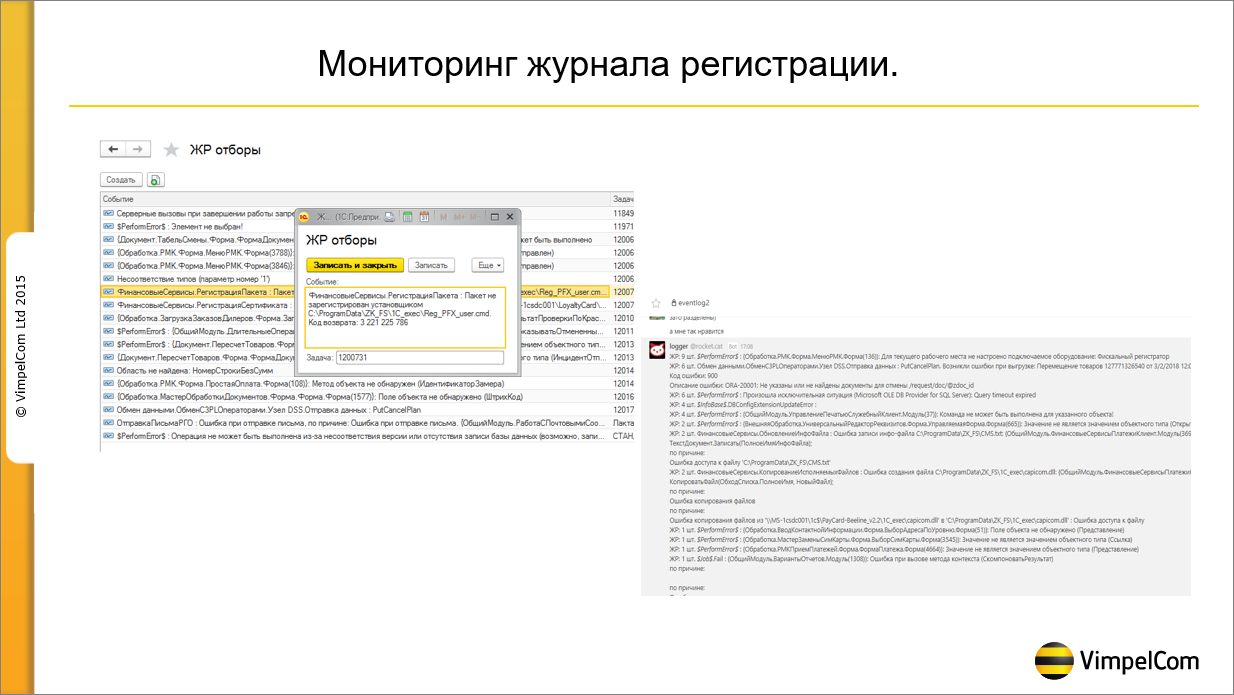
Кратко – про мониторинг журнала регистрации.
Этот мониторинг мы прикрутили за неделю. Как это работает? Мы в журнал регистрации пишем только ошибки. Глазами его читать тяжело, так как ошибок большое количество, поэтому мы делаем следующее – мы парсим журнал регистрации, группируем его по событиям и выводим в RocketChat (правая картинка).
Дальше – что должен сделать администратор системы или проблем-менеджер, который занимается задачей?
-
Он видит конкретную ошибку и заводит на нее дефект в системе багтрекинга.
-
После этого он прописывает в «Центре контроля качества» запись, что на конкретную строку заведен конкретный номер дефекта, после чего эта строка перестает выходить в мониторинге.
Фактически, когда мы разберем полностью все текущие ошибки, у нас будет заведено 30 дефектов, которые по стандартной процедуре отправятся в работу, а в журнале регистрации у нас не будет ни одной неизвестной ошибки. Ошибок много, но все они известные, и по всем ним заведены дефекты.
Примеры проблем, при решении которых нам помог мониторинг
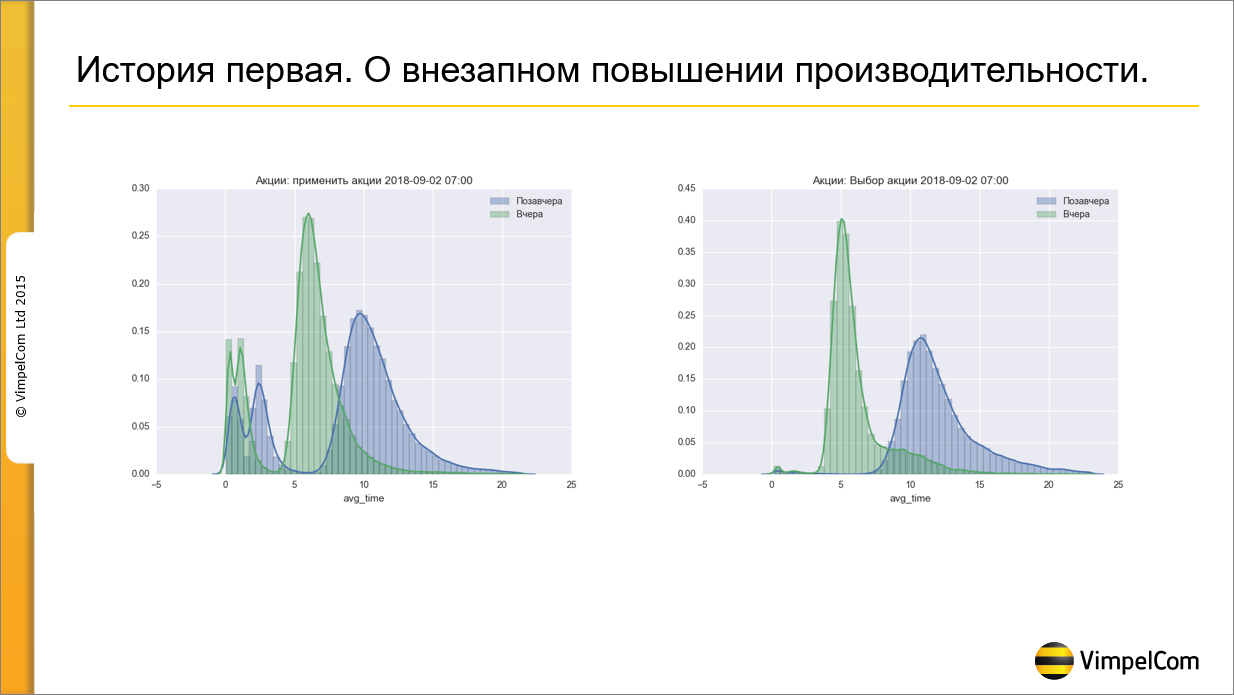
История первая – о внезапном повышении производительности.
2 сентября мне приходит на почту график, в котором я вижу такую картинку. Я вижу, что у меня по какой-то причине резко выросла производительность. Если раньше при нажатии на кнопку «Применить акции» продавец ждал 10-15 секунд, то сейчас стал ждать 5 секунд.
Когда производительность резко увеличивается, а ты ничего не делал, это пугает больше, чем, если она ухудшилась. Это значит, что ты перестал контролировать ситуацию. Мы полдня разбирались, в итоге догадались спросить у техподдержки, что они делали. И оказалось, что вчера закончился срок действия 600 акций. Всего у нас действующих акций 800, 600 из них закончили свой срок действия. Соответственно, все видно на графике. Чем больше акций – тем хуже производительность.
Какие мы сделали выводы?
-
Что у нас есть проблема с акциями, нам нужно оптимизировать код.
-
И второй вывод – что бизнесу надо как-то донести, что 800 акций – это плохо. Давайте попытаемся обойтись 200, а лучше 10. За это сейчас идет битва уже на административном, а не на техническом уровне.
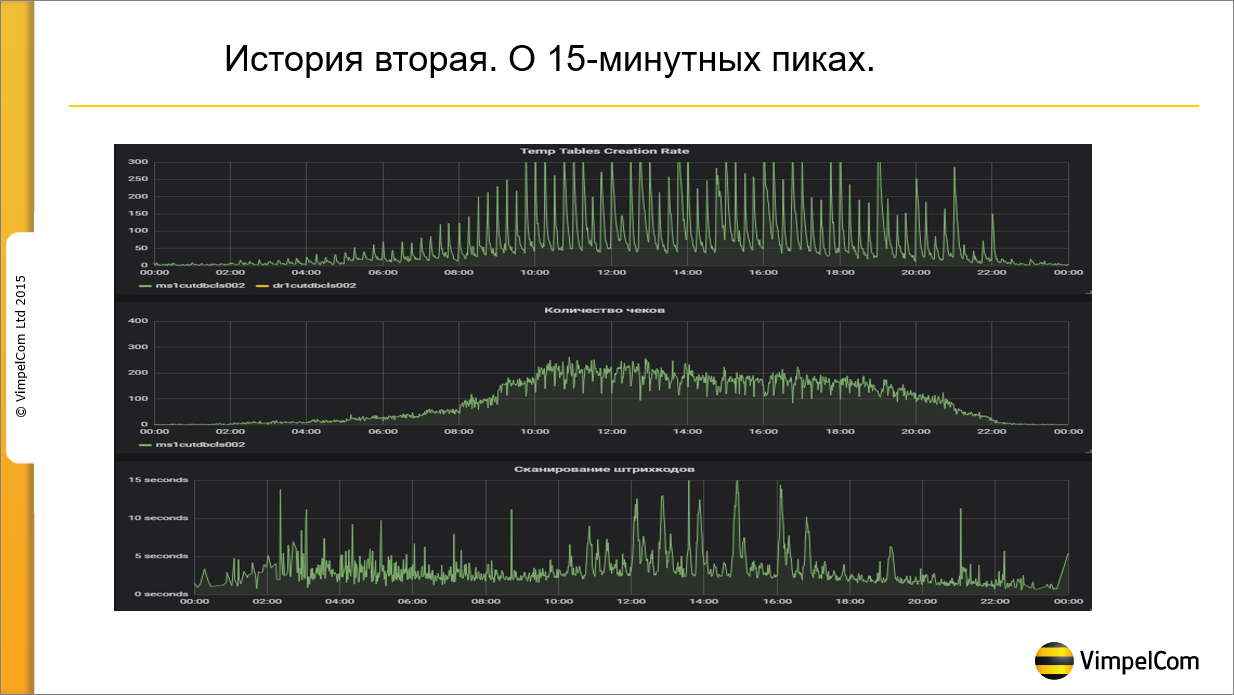
Вторая история – моя любимая.
В июле этого года мы заметили, что каждые 15 минут у нас происходит провал по производительности где-то секунд на 20. Начали искать причину, поставили счетчик на временные таблицы.
На верхнем графике показано количество создаваемых временных таблиц – видно, что каждые 15 минут у нас создается большое количество временных таблиц. Очевидно, что работает какой-то регламент, который каждые 15 минут что-то создает, из-за чего мы проваливаемся по дисковой подсистеме и получаем провал по производительности на основной системе. Нашли регламентное задание, которое создает порядка 50 тысяч временных таблиц, завели дефект, отдали разработчикам, сказали: «исправляйте». Они исправили, но стало еще хуже, пики стали еще выше.
Мы вообще перестали что-либо понимать – полтора месяца искали причину, не могли найти. В итоге завели инцидент и отправили его на системных администраторов – людям, которые занимаются железом. Говорим: «Ребята, мы уже все перепробовали, не можем понять причину». Через 15 минут приходит ответ: «Да у нас там баг в процессоре, он под высокой нагрузкой каждые 15 минут засыпает. Мы вам сейчас в биосе это отключим, он перестанет засыпать». В итоге они отключили засыпание, и все нормализовалось. Я сейчас уже не помню, как называется этот баг, не помню, как называется режим энергосбережения, который отключается в биосе, но суть была в том, что мы искали вообще не в том месте, где нужно.
После этой истории сделали вывод, что когда ищешь причину аварии, нужно привлекать как можно больше людей.
Планы
Какие у нас планы?
-
Мы хотим сделать автоматический парсинг технологического журнала, чтобы дефекты в системе багтрекинга создавались автоматически. Сейчас мы все это делаем вручную, но этот процесс интересно автоматизировать.
-
Хотим поставить агентов «Центра контроля качества» на всех клиентов. Потому что агент «Центра контроля качества» – это прикольная штука, которую можно использовать, в том числе, для решения проблем. Смотреть, например, что после выхода релиза на клиентах резко выросла нагрузка ЦПУ. Для 8000 клиентов это ничем кроме как агентом ЦКК не посмотришь. Либо агента Zabbix ставить.
-
И собираемся использовать мобильный клиент. Это к мониторингу не относится, просто хотел похвастаться.
****************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 EDUCATION. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Хм… должность как должность…
Коротко и понятно: «начальник ОКиПСДДРСДДпУЗБпРИ»
(1) Кровавый энтерпрайз на уровне отдела кадров )
Спасибо за статью. Всегда интересно читать про большие системы.
Есть вопросы по анализу журнала регистрации.
Журнал регистрации в каком формате хранится?
Анализ журнала регистрации выполняется прямыми обращениями к файлам или с помощью методов платформы?
Мы используем старый формат ЖР, который хранится в виде текстовых файлов. Анализ делаем средствами платформы (методом ВыгрузитьЖурналРегистрации()