Введение
Довольно часто возникает задача в запросе получить актуальное значение ресурса на каждую дату выбранного периода.
Вот несколько таких случаев:
- Курс валюты на дату каждого документа за выбранный период
- Цену товара на дату реализации по всем реализациям за период
- Должность сотрудника на каждую дату периода
Традиционный подход
Наиболее интуитивный и часто применяемый способ следующий:
/// первый запрос - выбирает все даты документов
ВЫБРАТЬ РАЗЛИЧНЫЕ
НАЧАЛОПЕРИОДА(Товары.Ссылка.Дата, ДЕНЬ) КАК ДатаДокумента
ПОМЕСТИТЬ
ВТ_ДатыДокументов
ИЗ
Документ.Реализация.Товары КАК Товары
ГДЕ
Товары.Ссылка.Дата МЕЖДУ &НачалоПериода И &КонецПериода
;
/// второй запрос - выбирает из нашего регистра сведений измерения и максимальный период на каждую дату
ВЫБРАТЬ
ВТ_ДатыДокументов.ДатаДокумента,
Цены.Номенклатура,
МАКСИМУМ(Цены.Период) КАК ДатаЦены
ПОМЕСТИТЬ
ВТ_ДатыНачалаДействия
ИЗ
ВТ_ДатыДокументов КАК ВТ_ДатыДокументов
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ЦеныНоменклатуры КАК Цены
ПО Цены.Период <= ВТ_ДатыДокументов.ДатаДокумента
ГДЕ
Цены.ТипЦены = &ТипЦены // например, такой отбор, или какой-нибудь другой
СГРУППИРОВАТЬ ПО
ВТ_ДатыДокументов.ДатаДокумента,
Цены.Номенклатура
;
/// третий запрос - выбирает из нашего регистра актуальные значения ресурсов на каждую дату документа
ВЫБРАТЬ
ВТ_ДатыНачалаДействия.ДатаДокумента,
Цены.Номенклатура,
Цены.Цена
ПОМЕСТИТЬ
ВТ_ЗначенияРесурсов
ИЗ
РегистрСведений.ЦеныНоменклатуры КАК Цены
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ВТ_ДатыНачалаДействия КАК ВТ_ДатыНачалаДействия
ПО ВТ_ДатыНачалаДействия.Период = Цены.Период
И ВТ_ДатыНачалаДействия.Номенклатура = Цены.Номенклатура
ГДЕ
Цены.ТипЦены = &ТипЦены // не забываем еще раз указать тот же отбор
;
/// четвертый запрос - основной, который получает нужные данные из временной таблицы, полученной на предыдущем шаге
ВЫБРАТЬ
Товары.Ссылка КАК Документ,
Товары.Номенклатура,
ВТ_ЗначенияРесурсов.Цена * Товары.Количество КАК Сумма // тут делаем что-то нужное нам с полученными значениями
ИЗ
Документ.Реализация.Товары КАК Товары
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ВТ_ЗначенияРесурсов КАК ВТ_ЗначенияРесурсов
ПО Товары.Номенклатура = ВТ_ЗначенияРесурсов.Номенклатура
И НАЧАЛОПЕРИОДА(Товары.Ссылка.Дата, ДЕНЬ) = ВТ_ЗначенияРесурсов.ДатаДокумента
Более продвинутые программисты могут объединить третий и четвертый шаг, что сократит количество временных таблиц. Но в примере оставим четыре шага ради большей наглядности
Также данный запрос может отличаться от автора к автору. Кто-то поймет, что это просто пример и уловит суть, но кто-то бросится в комментариях поправлять, оптимизировать и описывать свой опыт написания подобных запросов.
Но последовательность шагов обычно такая, как в этом типовом примере.
Я и сам по началу долгое время использовал именно такую схему.
Но данная схема неудобна по следующим причинам:
- Таблица, из которой мы выбираем даты документов — используется дважды. Если у нас не примитивный случай, а документы нужно брать, скажем, нескольких видов (через конструкцию ОБЪЕДИНИТЬ ВСЕ). То наш запрос вырастает в двух местах
- Но основное неудобство в том, что между основной таблицей (в нашем случае тч Товары) и регистром сведений (в нашем случае Цены номенклатуры) возникает связность в двух местах. То есть сначала мы должны будем написать самый последний запрос, чтобы понять какие даты нам нужны (в рабочем запросе это может оказаться не так просто сделать, как в приведенном примере). Потом повторить эту логику в первом запросе.
Когда пишешь сложный запрос, в котором срез на даты делается по нескольким регистрам (например, цены, валюты), в котором есть еще куча отборов и внутренних соединений, а также объединений, то данную схему использовать крайне неудобно.
Приведу пример. Когда-то в одной из конфигураций заказчика был непериодический регистр связи складов и подразделений. На этот регистр было завязано огромное количество отчетов. И вот однажды заказчик захотел сделать этот регистр связей складов и подразделений периодическим. Пройтись по всем отчетам, написанных разными разработчиками в разные годы и разобраться, как собрать таблицу дат в каждом из случаев — это была очень неприятная и трудоемкая работа. Плюс, конечно, запросы с этим регистром были не только в отчетах.
Подход со слабой связностью
Уже несколько лет для решения подобных задач, я использую другой подход — интервальный.
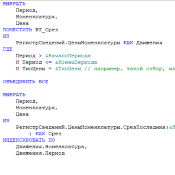
/// первый запрос - вытаскиваем из регистра сведений все что нужно за один раз
ВЫБРАТЬ
Период,
Номенклатура,
Цена
ПОМЕСТИТЬ ВТ_Срез
ИЗ
РегистрСведений.ЦеныНоменклатуры КАК Движения
ГДЕ
Период > &НачалоПериода
И Период <= &КонецПериода
И ТипЦены = &ТипЦены // например, такой отбор, или какой-нибудь другой
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
Период,
Номенклатура,
Цена
ИЗ
РегистрСведений.ЦеныНоменклатуры.СрезПоследних(&НачалоПериода, ТипЦены = &ТипЦены // тут надо повторить отбор
) КАК Срез
ИНДЕКСИРОВАТЬ ПО
Движения.Номенклатура,
Движения.Период
;
/// второй запрос - собираем таблицу с периодами действия ресурса
ВЫБРАТЬ
НачалоПериода.Номенклатура,
НачалоПериода.Цена,
НачалоПериода.Период КАК НачалоПериода,
ЕСТЬNULL(ДОБАВИТЬКДАТЕ(МИНИМУМ(КонецПериода.Период), СЕКУНДА, -1), &КонецПериода) КАК КонецПериода
ПОМЕСТИТЬ ВТ_ЗначенияРесурсов
ИЗ
ВТ_Срез КАК НачалоПериода
ЛЕВОЕ СОЕДИНЕНИЕ ВТ_Срез КАК КонецПериода
ПО НачалоПериода.Номенклатура = КонецПериода.Номенклатура
И НачалоПериода.Период < КонецПериода.Период
СГРУППИРОВАТЬ ПО
НачалоПериода.Период,
НачалоПериода.Номенклатура,
НачалоПериода.Цена
;
/// третий запрос - основной, который получает нужные данные из временной таблицы, полученной на предыдущем шаге
ВЫБРАТЬ
Товары.Ссылка КАК Документ,
Товары.Номенклатура,
ВТ_ЗначенияРесурсов.Цена * Товары.Количество КАК Сумма // тут делаем что-то нужное нам с полученными значениями
ИЗ
Документ.Реализация.Товары КАК Товары
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ВТ_ЗначенияРесурсов КАК ВТ_ЗначенияРесурсов
ПО Товары.Номенклатура = ВТ_ЗначенияРесурсов.Номенклатура
И Товары.Ссылка.Дата МЕЖДУ ВТ_ЗначенияРесурсов.НачалоПериода И ВТ_ЗначенияРесурсов.КонецПериода
Плюсы интервального способа:
- Первые два шага довольно простые и не связаны с бизнес логикой основного запроса.
- Можно использовать данный запрос как шаблон, что значительно экономит время при разработке.
В итоге вся бизнес логика у нас перенеслась на последний запрос (то есть собралась в одно место). Это большой плюс при модификациях основного запроса.
Ну и конечно, в зависимости от задачи можно накладывать дополнительные отборы в первом шаге, чтобы оптимизировать работу запроса.
Заключение
Само собой у обоих способов могут быть ограничения в применении в каждом конкретном случае в зависимости от задачи. Но в моей практике я почти не использую первый способ, т.к. в подавляющем большинстве случаев применим второй способ.
Я выложил данный шаблон запроса главным образом для себя, т.к. довольно часто он пригождается. Но будет неплохо, если кто-нибудь сочтет его подходящим для себя.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
любопытно… в самом первом запросе
а чуть далее
почему ДАТАВРЕМЯ(3000, 1, 1) , а не &КонецПериода ?
давно уже подобную задачу решают одним запросом (без всяких временных таблиц) с двумя левыми соединениями
Подобные задачи гуглятся по запросу «срез последних на каждую дату». Хорошо бы автору добавить подобное упоминание, иначе способ бесславно утонет.
(1) согласен, это неточность.
Вечером подправлю
(2) ты давай-ка приведи пример.
А то может ты что-нибудь путаешь или не учитываешь.
(3) спасибо. Добавлю в текст
Не вникал в смысл задачи, но срез на дату чего-либо по периоду делается простым 1 запросом без всяких ВТ.
типа
выбрать
ТаблицаОбъекта.Ссылка,
Т1.Период,
Т1.Срез1,
….
Т1.СрезХ,
Т1.Ресурс /// искомое значение
ИЗ ТАблицаОбъекта
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодичностьЧегоТо КАК Т1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодичностьЧегоТо КАК Т2
ПО Т1.Срез1 = Т2.Срез1 И….И Т1.СрезХ = Т2.СрезХ
ПО ТаблицаОбъекта.Дата >= Т1.Период И ТаблицаОбъектов.Ссылка В (&Ссылки)
СГРУППИРОВАТЬ ПО
ТаблицаОбъекта.Ссылка,
Т1.Период,
Т1.Срез1,
….
Т1.СрезХ,
Т1.Ресурс /// искомое значение!!!
ИМЕЮЩИЕ Т1.Период = Масимум(Т2.Период)
З.Ы. Мог где-то ошибиться, это общий вид запроса. думаю смысл его понятен.
(7) ну вот ты и задвоил записи в основном запросе. Теперь представь, что в основной таблице очень много записей, которых теперь может стать на один- два порядка больше ( если формировать, скажем, за месяц). И возможно, что в основном запросе ещё куча показателей, требующих соединения с другими таблицами, при расчете которых ты теперь уже не можешь использовать функцию СУММА ()
Гораздо выгоднее с точки зрения производительности накладывать группировку только на таблицу с периодичностью, чем группировать запрос с кучей соединений.
А с точки зрения удобства работы с основным запросом, не выгодно делать соединения, задваивающие в нем записи без необходимости
Тета-соединение — довольно затратная операция, и накладывать его обычно лучше отдельно
(8)
1. Для разовых операций это не критично, если жесткач, то можно установить порции
2. Для неразовых также можно устанавливать порции. В реальных задачах пользователю что нужно обрабатывать полностью всю таблицу объектов? Он же п.3
3. в 99% случаев есть отбор с х-количеством документов/ссылок и т.д. объем которых редко превышает 40 (динамический список например) или ТЧ документа ну несколько тыс строк
З.Ы. Нада ориентироваться конкретной задачей, нельзя пытаться натянуть любой метод решения на глобус, нет ничего универсального. Например списание партий в запросе — там тоже происходит мерж джоин со своей временной сложностью
(5) вот простенький пример, легко масштабируется на более сложные условия
Показать
получаем такой результат
Дата Номенклатура Цена Период
06.01.2019 0:00:00 Тов1 150 05.01.2019 0:00:00
06.01.2019 0:00:00 Тов2 210 01.01.2019 0:00:00
06.01.2019 0:00:00 Тов3 0
по Тов1 цена взялась от 05,01,2019
а по Тов2 от 01,01,2019
(9) мы с тобой рассмотрели два подхода к решению одной задачи в общем случае.
Можно, конечно, продолжать накидывать аргументы в защиту каждого, но пользы от этого я не вижу.
Вывод такой: оба варианта можно использовать. Каждый выбирает тот, который удобнее и применим в конкретной задаче
(10) уже обсудили этот вариант в комментариях чуть ранее.
Больше ничего не добавлю.
Но приятно, что есть разработчики, которые готовы поддержать свои комментарии кодом, а не просто ради того чтобы покритиковать да сумничать
(0)
Не знал, что у функции НАЧАЛОПЕРИОДА() есть такой параметр «ДАТА». У меня запрос сразу выдаёт ошибку: Неверные параметры … <<?>>ДАТА…
(13) опечатка. Вечером поправлю. Правильно ДЕНЬ, а не ДАТА
(11) Ну имхо 1 запрос более читаем, все сделали в одном месте и сразу. Кроме того, есть преимущество в том, что не нужно создавать индексы во ВТ, а используются физические индексы самих таблиц и как раз то при большом количестве записей будет выигрыш. Вообще всегда нужно использовать именно их
(15) услышал твои аргументы.
Привожу свои:
1. Не согласен, что вариант с двумя левыми соединениями и группировкой более читаемый. Считаю, что в моем варианте первые два запроса — служебные и не требуют чтения и погружения. Зато основной запрос становится более читаемым, гибким и быстрым.
2. У меня как то была задача, чтобы в отчёте пересчитать сумму из валюты документа в валюту, выбранную пользователем. Так вот, моим вариантом эта задача решилась просто, нужно было лишь дважды присоединить таблицу с интервалами. С твоим способом пришлось бы цеплять тета-соединение дважды.
3. Но мой способ не подойдёт для динамического списка, например.
Правильный вывод: знаем все подходы, применяем — наиболее подходящий в каждой конкретной задаче
(16) Ну по поводу читаемости, как на скуле пишу, так флиент юзаю в ентити фреймворк (которые многие терпеть не могут, предпочитая декларативный тип), что руками и в консоли в 1С — не вижу особой разницы в читаемости нескольких соединений. Тут спорить смысла нет, так как на вкус и цвет фломастеры разные 🙂
Для динамического списка есть еще такая фишка как коррелируемый запрос, когда делается соединение с нужной таблицей в подзапросе типа 1 В (выбрать 1 из НужнойТаблицы где Поле1 = ВнешнийЗапрос.Поле1) и получаем сразу нужный срез. Т.е. можно написать тоже самое, что делает EXIST в tsql. Кстати на скуль это так и переносится, если глянуть профайлер. Идеально для получения всяких статусов и прочего непосредственно в запросе ДС, а не при при получении данных. Если ты полностью фиксируешь измерения, то там index seek и работает это шустро. Не раз применял такое при оптимизации всяких костылей.
А как учитывает ваш запрос периодичность по позиции регистратора? Правильно он отработает, если любимый пользователь введёт два документа с одинаковой датой?
(18) чисто гипотетически если такая необходимость будет, то можно доработать запрос.
Но пока не могу придумать пример, где бы такое могло потребоваться в реальной задаче.
(19). Уважаемый, я вам только подготовил картинки по вашему комментарию, а вы его изменили. 😉
Гипотетически — не гипотетически, а такие варианты возможны, и их надо предусматривать. Поэтому хотелось бы увидеть ваш вариант. Мой — очень громоздкий получается.
(20) да я изменил свой комментарий, потому что понял, что был не прав ))
Попробую набросать и выложить, посмотрим, что получится (и получится ли)
Есть ещё вариант с помощью коррелирующего подзапроса (производительность нужно проверять, но запрос достаточно красивый):
Показать
(22) Я такой использую в отчете «выручка и с/с продаж», производительность устраивает.
меня зарубили на одном собеседовании за то, что я на бумажке не смог написать данный запрос, а попросил сесть за комп.
(24) обычно там требуют не срез на каждую дату, а срез на дату 🙂
(25)у меня требовали срез на каждую дату)
а почему не рассматривается вариант для курсов валют
Показать
В случае цен конечно такой вариант не прокатит =)
(27) потому что в теме фигурирует «срез последних». В твоем запросе нет среза.
И так к сведению, есть валюты, для которых курс изменяется не каждый день. Самый банальный пример такой валюты — это рубль, у которого курс = 1 и задан один раз. Но есть и другие более экзотические валюты
Слабая связанность, тета-соединение — прекрасные варианты.
Но все это перестает работать, когда в регистре цен овер 100 млн строк…
И тогда на сцену выходит тот самый Ваш первый вариант (где 3й и 4й пакет сделаны 1м пакетом).
Потому как на таких объемах данных уже играет роль способность сервера БД в целом переварить такую выборку, а также дисковая подсистема и особенно tempdb
(29) не буду переубеждать
(30) так и не надо. Я все это проверял на как раз таких данных, и не раз
(31) если бы ты был известным экспертом в области производительности, то я бы тебе конечно поверил.
Но ты заявляешь, насколько я понимаю, что для любой задачи с любыми данными какой-то один способ лучше. Это подозрительно.
Я очень сильно сомневаюсь, что ты проверял каждый из перечисленных здесь способов.
Все что у тебя есть это твои предположения, которые ты не подтвердил цифрами.
Если бы ты хотя бы привел пример, то можно было бы уже предметно подискутировать. Тогда я бы с тобой согласился бы или нет.
Но мне не известно что ты там и на каких данных проверял.
Хотя бы привел пример, что за такой периодический регистр сведений со 100 млн. записей ? Что вы в нем такого храните? И что за задачи ты там решал где «проверял на как раз таких данных, и не раз»?
На практике бывает так, что когда у тебя есть трудности с производительностью, то пробуешь все более менее подходящие способы. И очень часто самым лучшим оказывается не тот, на который ты думал вначале.
Так что благодарю за ценные замечания. Твоя информация оказалась весьма полезной и содержательной.
(32) во-первых, не ты, а Вы. Мы с Вами водку на брудершафт не пили. Элементарная вежливость, нет? Во-вторых, если Вы бд видели таблиц со 100 млн записей, это не значит, что их нет. Продажи, множество типов цен, множество позиций товара, цены меняются каждый день, вот и ответ. И да, я проверял работу тета-соединения для получения среза цен на каждую дату. И первый запрос (первый подход, точнее) выиграл у него по скорости в 2.5 раза. И я всего лишь поделился реальным опытом. Доказывать что-то лично Вам желания нет (с учётом Вашей неадекватной реакции на вполне спокойный комментарий). Хотя изначально хотел сделать скриншоты из консоли. Общение общением, хамить то зачем?
(33)
Насчет ты-вы. Я считаю нормальным, когда коллеги общаются на ты, это обычно упрощает коммуникацию. Когда ко мне обращаются на ты, для меня это норма и я в ответ тоже перехожу на ты. Очень редки случаи, когда кто-то говорит шаблонную фразу, что «мы с тобой что-то не делали». Обычно это говорит о том, что человек не настроен на конструктивное общение. Но это уже не моя проблема.
Насчет хамства. Давай-ка процетируй какие именно слова из моих комментариев ты посчитал хамством.
Насчет твоих выводов.
В комментарии 29 ты упомянул три способа, а в комментарии 33 ты пишешь, что сравнивал только два из них. То есть как я и написал в комментарии 32, ты не проверял ВСЕ способы. Но при этом ты уже сделал вывод о производительности.
Почитай комментарий 8, где я как раз и писал, что вариант с двумя соединениями к периодическому регистру (который ты называешь тета-соединение), является менее производительным. Что собственно и совпадает с приведенными тобой примерами.
Но каких-то оснований для того, чтобы сделать вывод о производительности варианта с интервалами, я в твоих комментариях не увидел, хотя ты сделал такой вывод в комментарии 29. Поэтому я изначально постарался избежать бесполезной дискуссии в комментарии 30.
Насчет приводимых тобой примеров и доказательств.
К сожалению, твои комментарии содержат очень мало конкретных убедительных аргументов.
Аргументы типа «Я все это проверял», «изначально хотел сделать скриншоты» и т.д. в таком духе — это не аргументы.
Насчет 100 млн. записей.
Я видел регистры накопления и с миллиардом записей. Но регистр цен на 100 млн. записей — трудно представить. По моей оценке это 10 лет нужно устанавливать цены на 5000 позиций по 5 видам цен ЕЖЕДНЕВНО.
Я себе с трудом могу представить отрасль, в которой было бы 5000 АКТИВНЫХ позиций номенклатуры на которую ЕЖЕДНЕВНО меняют цены.
Собственно это и выглядит неправдоподобно.
А судя по твоему комментарию 29, в варианте с интервалами вроде как нужно выгружать эти 100 млн. записей во временную таблицу. Или тогда я не понимаю, почему этот аргумент приводится к этому способу в комментарии 29.
Насчет неадекватной реакции
Цитирую: «с учётом Вашей неадекватной реакции на вполне спокойный комментарий».
Не понял в чем проявилась неадекватность? Всего навсего задал вопросы для уточнения и не более того.
Тут на ИС очень много разработчиков, которые считают себя спецами. Но когда начинаешь задавать конкретные вопросы, то объяснить не могут.
Я понимаю, что ты не тролль и отношусь к тебе с уважением. Но если ты хочешь покритиковать (в данном случае ты покритиковал производительность приведенного в статье метода), то будь добр приведи убедительные аргументы и технические подробности, иначе может возникнуть недопонимание
(34) 10 тыс позиций, 100 и более типов цен. По сути, для каждого клиента делается свой тип цен. Это спорно с точки зрения архитектуры решения, но мне лично досталось вот в таком виде, приходится жить с этим. 3 измерения в регистре: товар, тип, спецусловия. Цены меняются каждый день! Ежедневный прирост строк в таблице рс — 1 млн! Цены ставят как руками, так и из файлов загружают. А в некоторых региональных базах и более. Запросы к ценам у нас — самое узкое место в системе. И есть ряд хитрых архитектурных решений, призванных облегчить эти запросы (в 2 словах не описать, тянет не отдельную публикацию). В том числе каждые несколько месяцев средствами бд формируется срез последних (содержит 1.5-2 млн уникальных строк), движения этого среза крепятся к регистратору с пустой тч. Все цены до регистратора — удаляются. Если этого не делать — таблица регистра просто становится неперевариваемой. Мы пробовали разные способы — и отдельные итоги для среза последних и да, тета-соединение в запросе. Будет полчаса лишних на работе — покажу Вам замеры. Кроме того, при интерактивном подборе товаров в заказы, менеджеры всегда хотят видеть актуальные цены, для этого есть механизм кэширования по ключам аналитики, где каждый ключ — Товар+НаборАналитик+ТипЦены. Так что, коллега, ситуации бывают всякие. Слабую связанность ещё не проверял толком, но так как там есть большая выборка плюс срез, потом их джойн — думаю, что проиграет первому подходу. А первый подход хорош тем, что попадает в кластерный индекс регистра.