
Кто мы и что мы делаем?
Компания SOFTPOINT занимается производительностью. Наша базовая услуга – это аудит производительности. Мы изучаем систему, смотрим, как она работает, находим узкие точки при работе, а потом рассказываем, как их обойти, устранить, в общем, заставить вашу систему работать на полную.
Кроме того, у нас есть несколько патентованных решений, работающих в связке с MS SQL и 1С. Это распределение нагрузки между несколькими серверами и СУБД, ускорение запросов на лету, онлайн-репликация с минимальной задержкой, в том числе и «active-active» (когда в обеих базах можно изменять данные и проводить документы). То есть, мы немножко разбираемся в том, как работает 1С и как работает MS SQL.
Часто мы видим какие-то странные вещи, какие-то необъяснимые ситуации. О паре таких вещей и о том, что из этого следует, хотелось бы сегодня рассказать.
Распределенные взаимоблокировки
Немного определений. Что такое взаимоблокировка?
Ненадолго окунемся в теорию и начнем со «школьных» определений, что вообще такое дедлоки. Я думаю, многие это знают, но на всякий случай освежу в памяти, чтобы дальше говорить на общем языке.
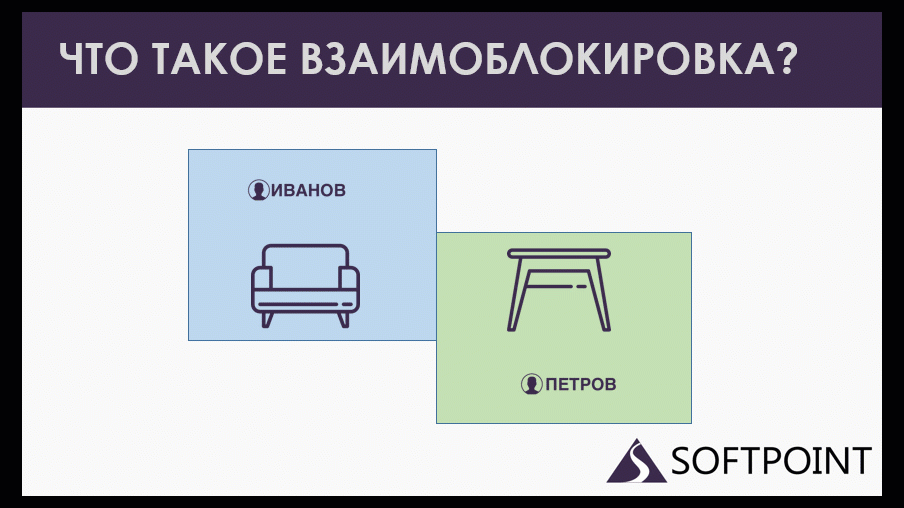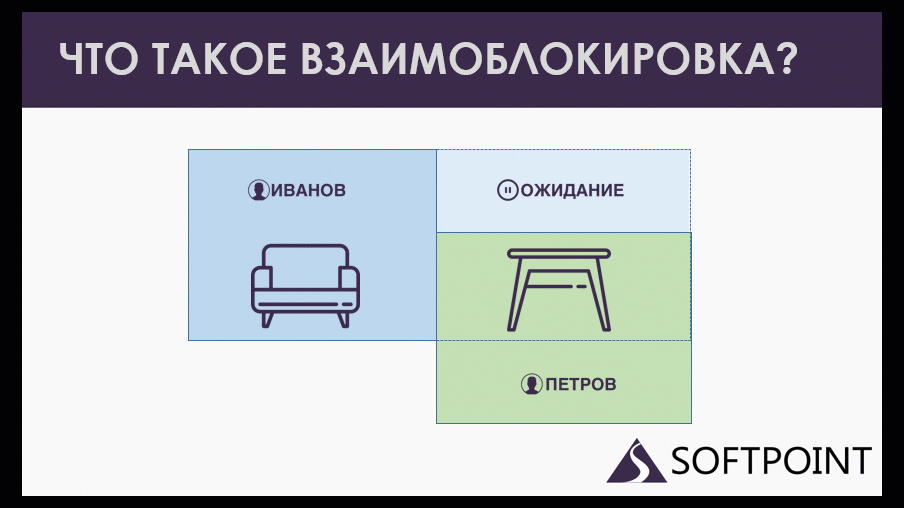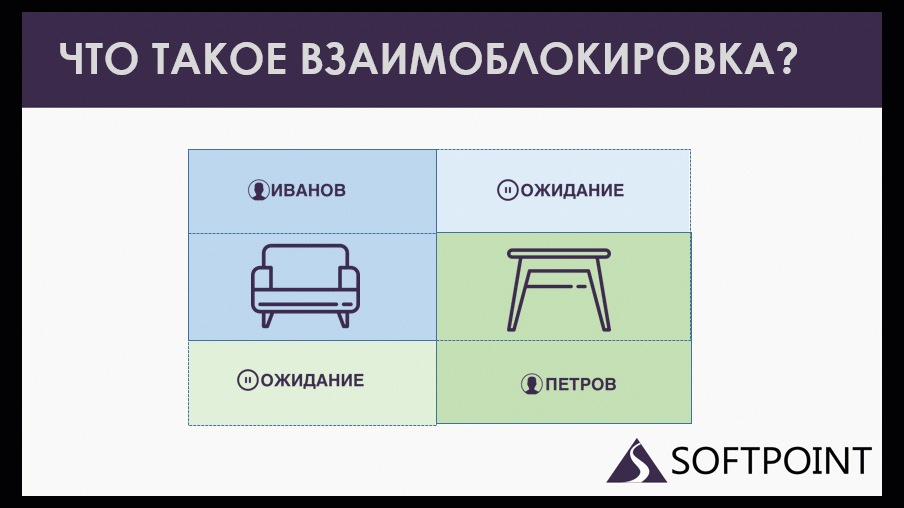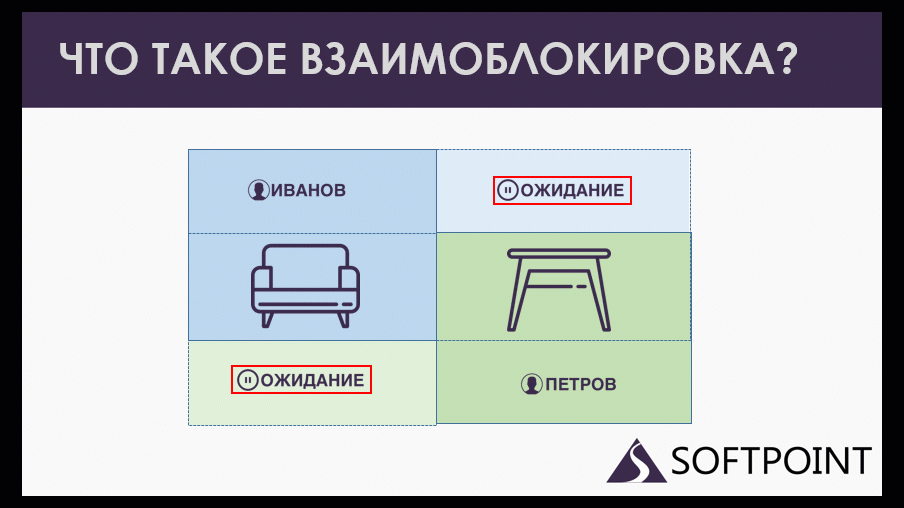
Дедлок или взаимоблокировка – это «уроборос» из транзакций, закольцованная блокировка.

Допустим, у нас есть менеджер Иванов, который зарезервировал на складе кресла и собирается зарезервировать еще и табуретки. Он пытается это сделать, но ему приходится ждать. Потому что у нас есть еще менеджер Петров, который табуретки уже зарезервировал и ему потребовались еще те же самые кресла. Получается, они ждут друг друга, оба образуют кольцо ожиданий, которое не завершится никогда. Потому что каждая сессия может завершиться, отдать свои ресурсы, только когда дождется того, чего она ждет.
Но и у 1С, и у MS SQL, и у других популярных баз данных есть встроенные механизмы для понимания и определения таких ситуаций. То есть и 1С, и базы данных могут понять, что произошел дедлок. Они находят какую-то одну сессию, которую выгоднее всего обрубить, и принудительно завершают ее. Иначе этот круг ожидания никак не разрешить, нужно просто кого-то обрубить.
Соответственно, тот, кому не повезло, получает вместо проведенного документа ошибку о том, что произошел дедлок, транзакция откатывается. Он огорчается, уходит пить чай и ругает программистов. Может быть, он через полчаса вернется обратно к работе.

Как я сказал, и MS SQL, и 1С умеет определять взаимоблокировки. SQL умеет нам показывать вот такие красивые графы.
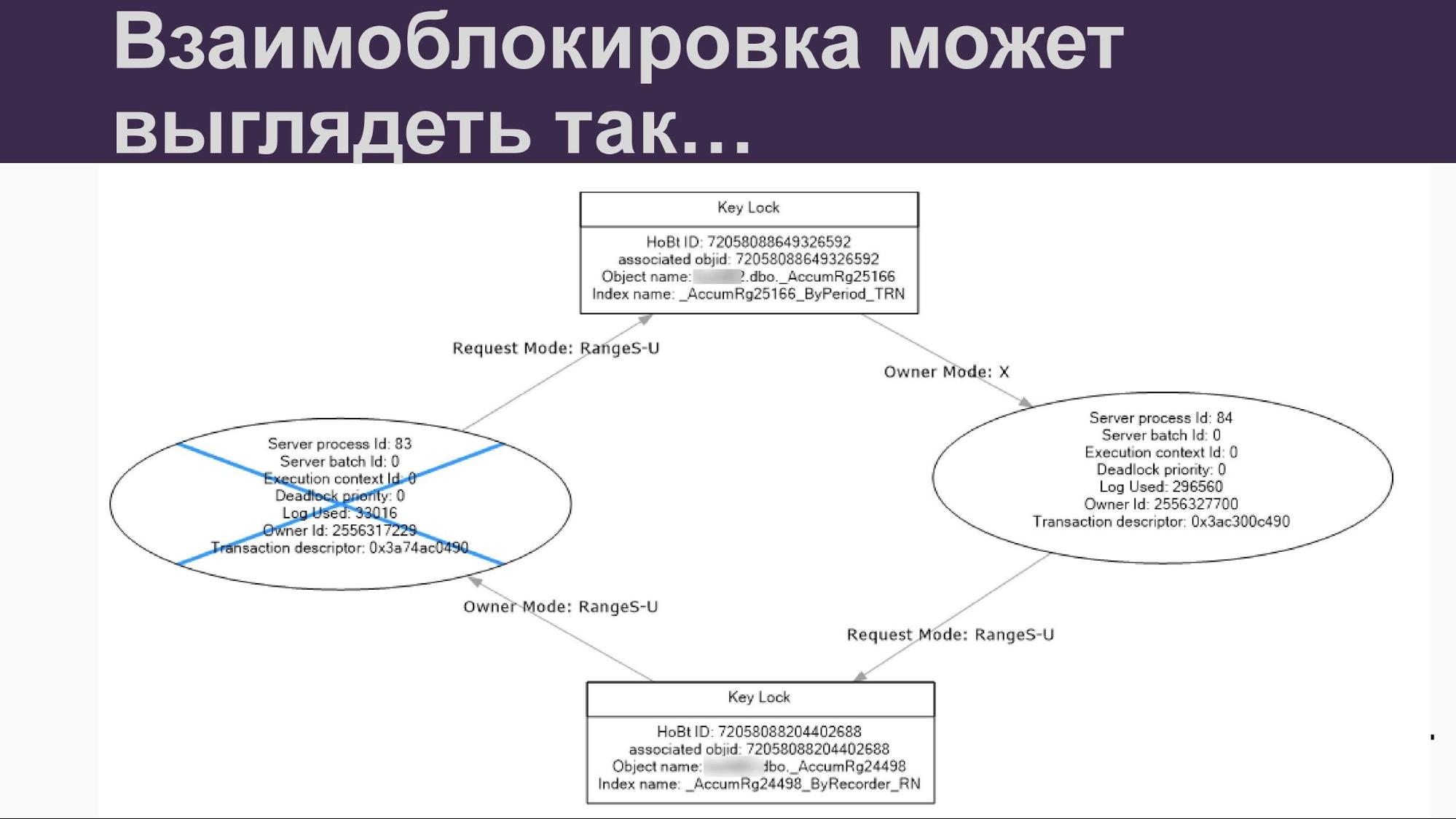
Здесь видны и ресурсы, и кого в итоге оборвали. И в принципе удобно в этом разбираться. 1С тоже не отстаёт. Если мы включаем технологический журнал, у нас там есть специальное событие TDEADLOCK. Мы тоже видим дедлоки, поэтому можем в принципе раскрутить.
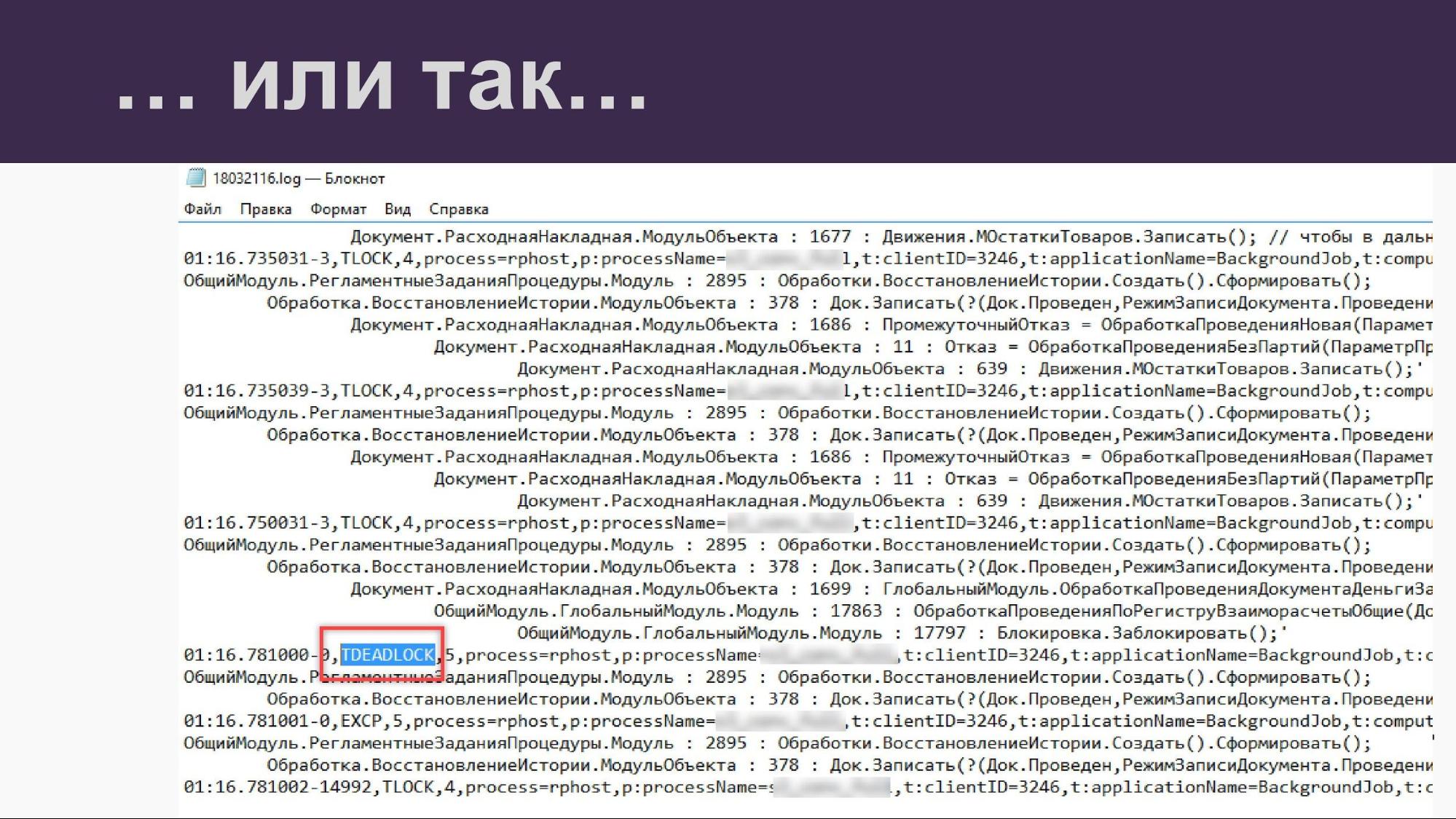
Мы в своей работе используем нашу систему PerfExpert, которая показывает блокировки и дедлоки в виде “графов” или “деревьев”. Расскажу, как это работает.

Наверху графа находится блокирующая сессия, та, что блокирует всех, это долгая транзакция. Внизу – подчиненные, те, кто попали на блокировку, те, кто ждут. Но если у нас дедлок, то можно внезапно обнаружить ту же самую 120-ую сессию, которая наверху, еще где-то посередине. Так у нас ожидание закольцевалось.
Необычный инцидент
Однажды я расследовал сложный инцидент, странные блокировки. Выглядело это примерно также – как какое-то огромное дерево ожиданий. Проблема в том, что блокировки были долгими, длились минутами и непонятно из-за чего. Причем эта условная блокирующая «120-ая сессия» даже процессор не использовала, ничего не делала. Что-то странное происходило.
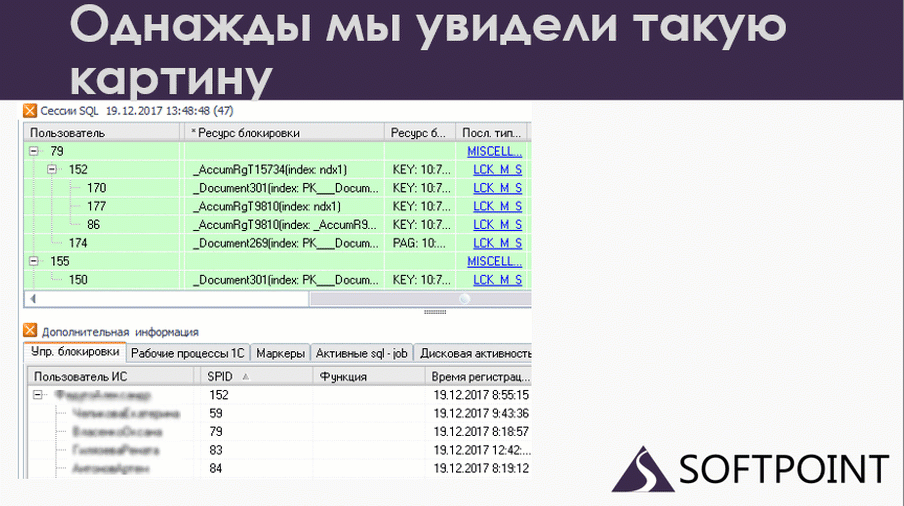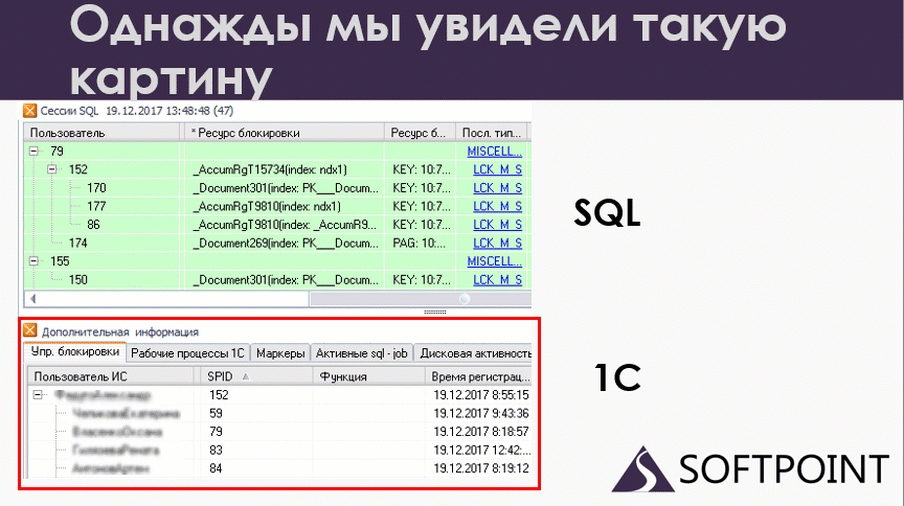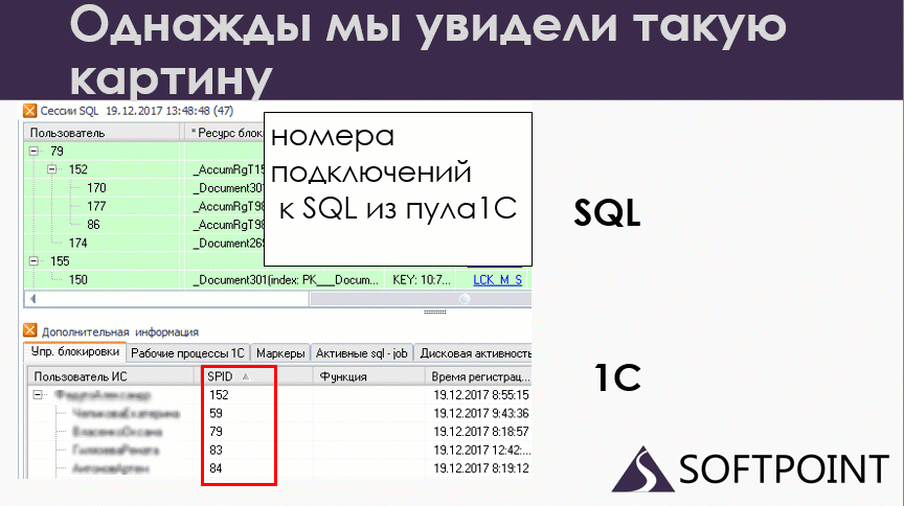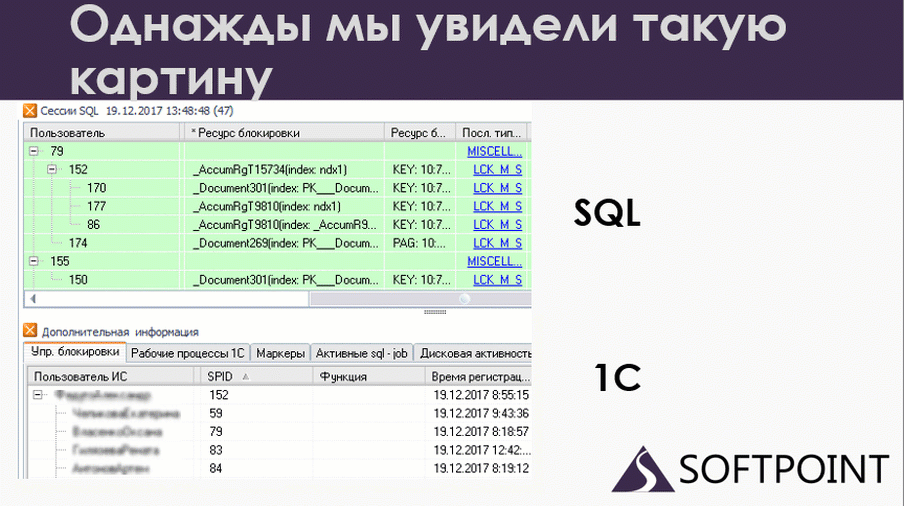
В какой-то момент я сопоставил данные 1С и SQL. На слайде в верхней части показаны данные по SQL. Это сессии, которые в данный момент работали. Внизу – те же самые сессии с точки зрения 1С. Вверху мы видим номера подключений SPID, внизу те же самые SPID’ы. То есть это одни и те же пользователи на 1С и на SQL, но с разных точек зрения.
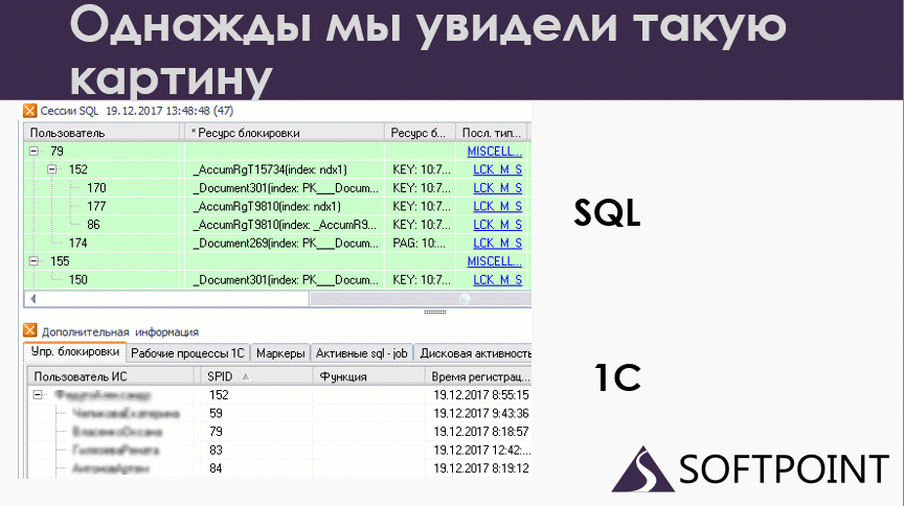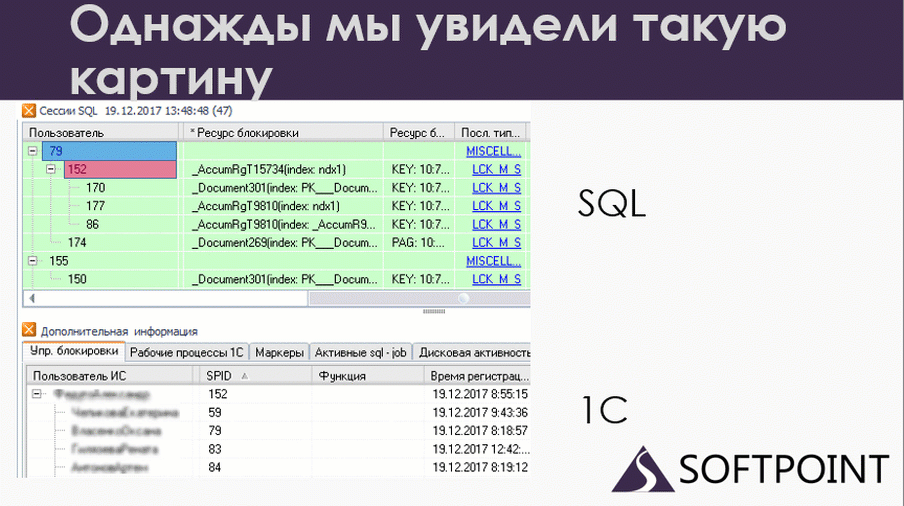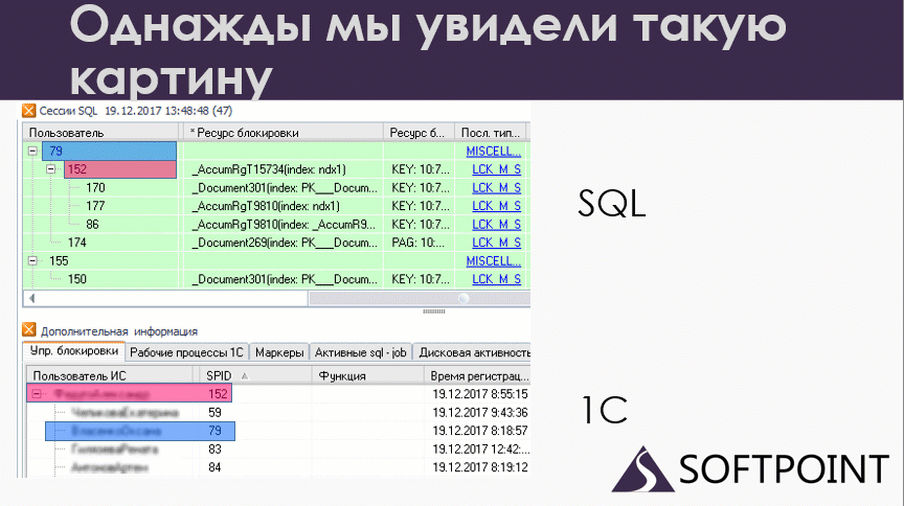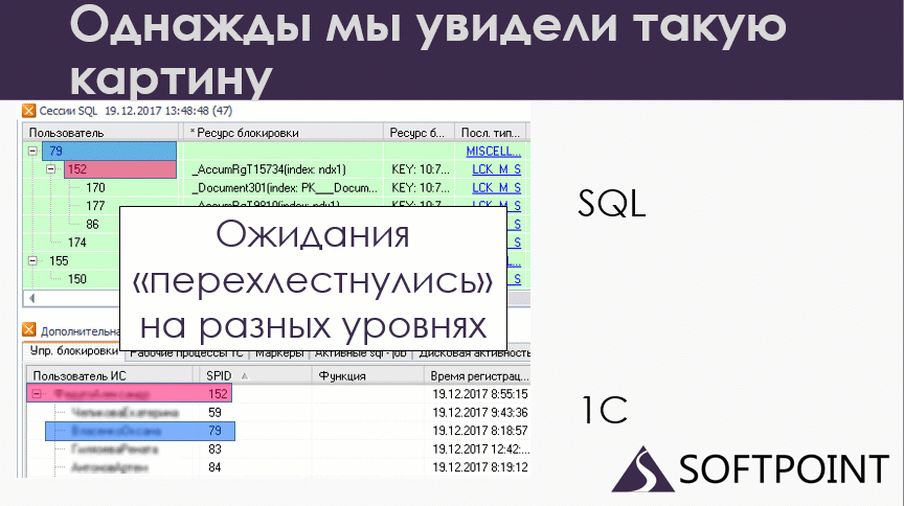
По сути, это одно и то же, но что мы здесь видим? У нас есть 79-ая сессия, которая блокирует 152 на уровне SQL. А если мы посмотрим на 1С, мы увидим, что все ровно наоборот: 79 ждет 152. Вот и дедлок. Но он у нас развалился на две части. Одна половина дедлока произошла на SQL, а вторая половина – на 1С.
Ни одна из систем – ни 1С, ни SQL – не понимает, что это дедлок. Каждая из них думает, что это просто обычное ожидание. И мы не увидим ни красивого графа в xml, ни события TDEADLOCK в техжурнале.
В этот момент происходит гонка таймаутов. У кого он короче, у 1С или у MS SQL, тот первым выдаст ошибку, что произошла блокировка, не удалось закончить транзакцию. Пользователь увидит, что произошла блокировка, скажет об этом программисту. Программист поймет, что это блокировка, и пойдет ее искать. И никогда не поймет, насколько вообще серьезна вся эта ситуация.
Почему такие взаимоблокировки случаются?
Вариантов может быть несколько. Пару из них разберем для примера.
Первый вариант – мы просто забыли наложить управляемую блокировку. Это больше актуально для старых конфигураций, начиная с 8.0, которые давно и долго переделывались, и в какой-то момент переписывались под управляемые блокировки. Конечно, есть guidelines (руководства), но остаются нюансы, про которые все забывают.
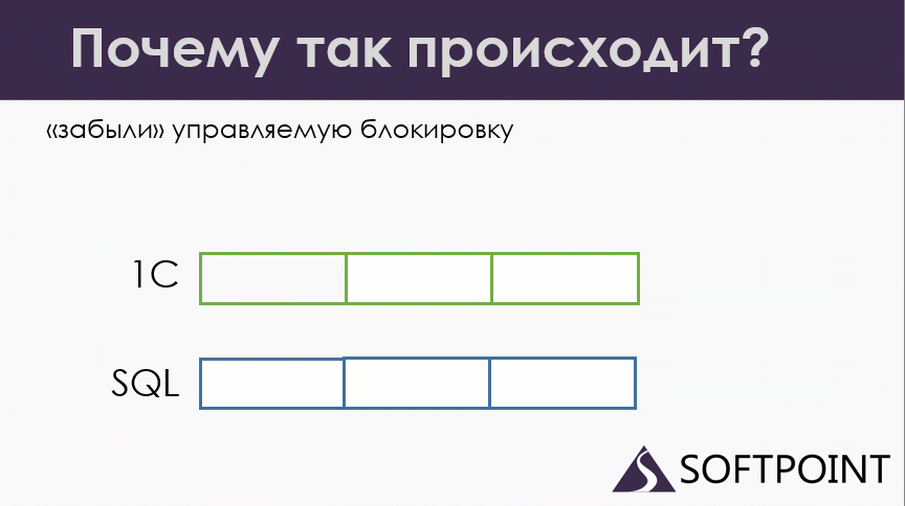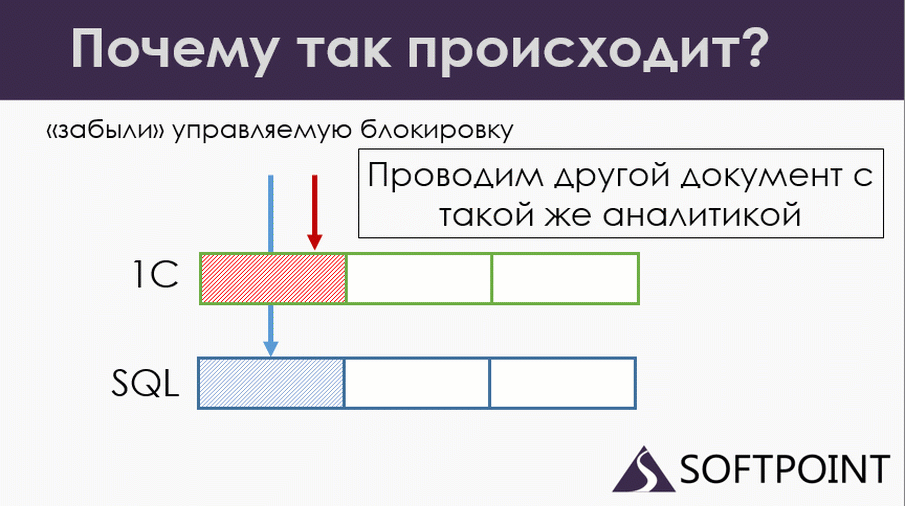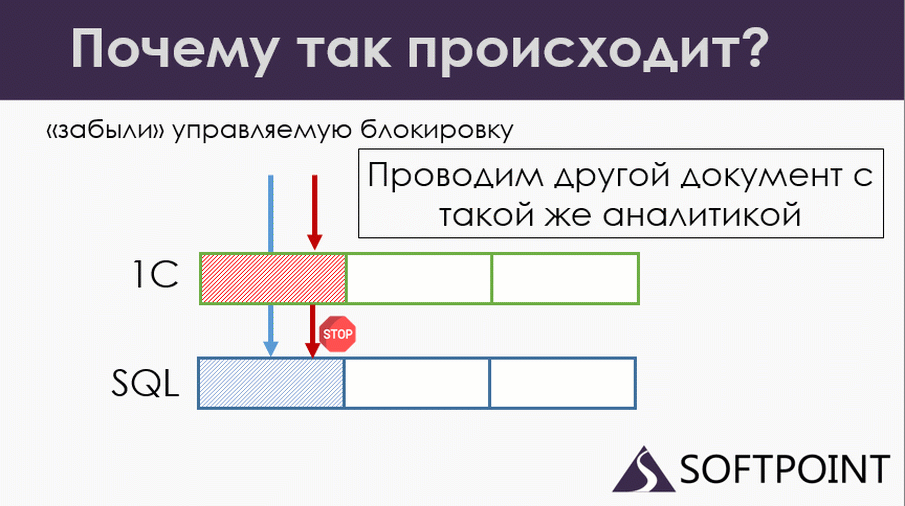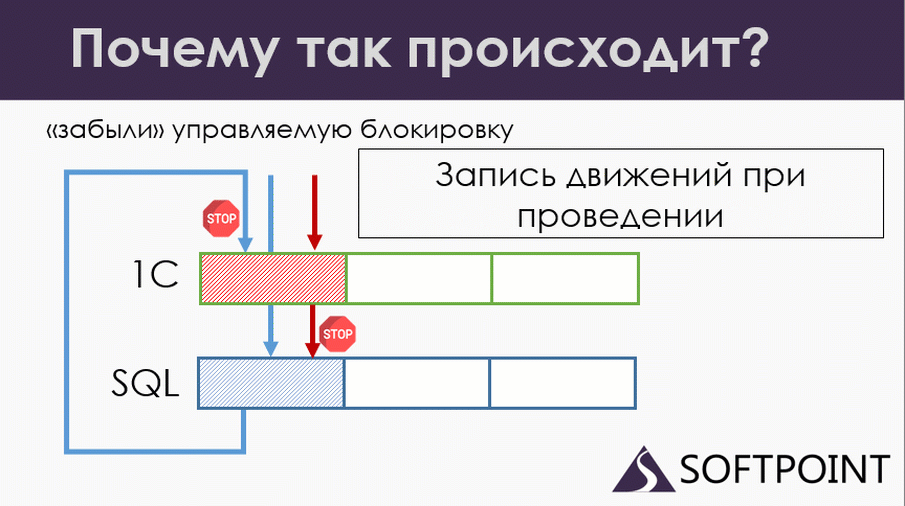
Например, многие забывают про отмену проведения. Допустим, у нас документ перепроводится, и программист просто забыл закрыть отмену проведения, удаление движений, управляемыми блокировками. Происходит следующее:
-
Мы сразу удаляем движение, накладываем блокировку на SQL, все работает нормально.
-
Параллельно у нас проводится другой документ (красная транзакция). Он проводится по всем правилам, то есть там программист накладывает управляемую блокировку, пытается записать данные и попадает на блокировку на уровне сиквела. Ждем.
-
В этот момент у нас первый документ (синий) наконец-то удалил все старые движения, посчитал, что ему нужно посчитать, попытался записать данные. И в этот момент он попал уже на управляемую блокировку.
Еще раз: у нас документы проводятся по правилам: управляемая блокировка, физическая SQL блокировка. Проблема в том, что у нас при удалении движений движение не было закрыто от управляемых блокировок. Поэтому ожидания перехлестнулись.
Второй вариант. Допустим, у нас две транзакции, но только одна из них — это транзакция обмена. Мы парсим большой долгий файлообмен с несколькими документами, парсим его в одной транзакции, чтобы потом было проще убирать мусор: если какая-то ошибка случилась, мы сразу откатываем всю транзакцию с этими документами и потом перечитываем этот файл.
Поехали!
-
Проводим первый документ из нашего файлообмена. Накладываем управляемую блокировку.
-
Параллельно у нас другой документ проводится, потому что сами регистры тоже накладывают свою управляемую блокировку. Все хорошо.
-
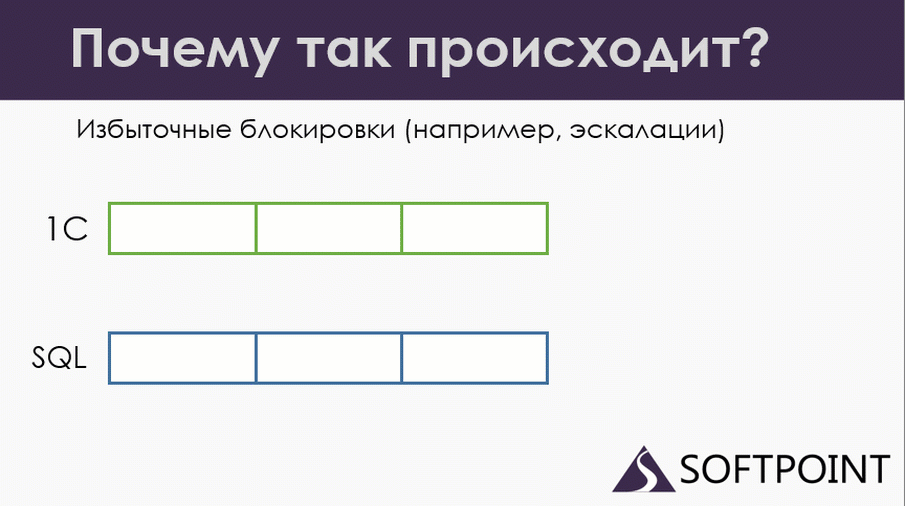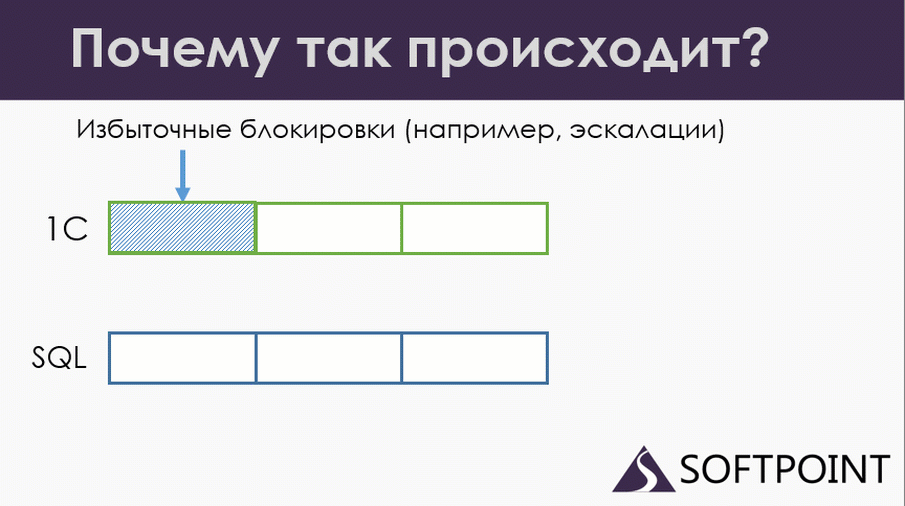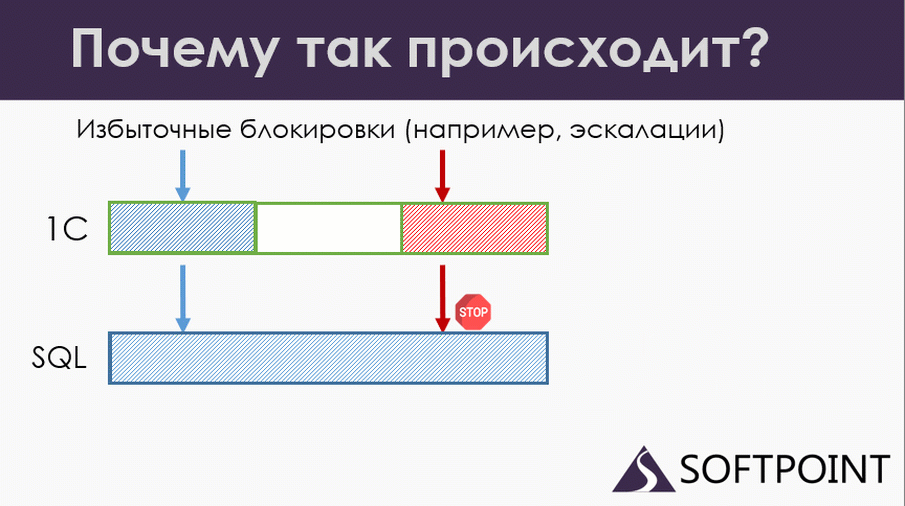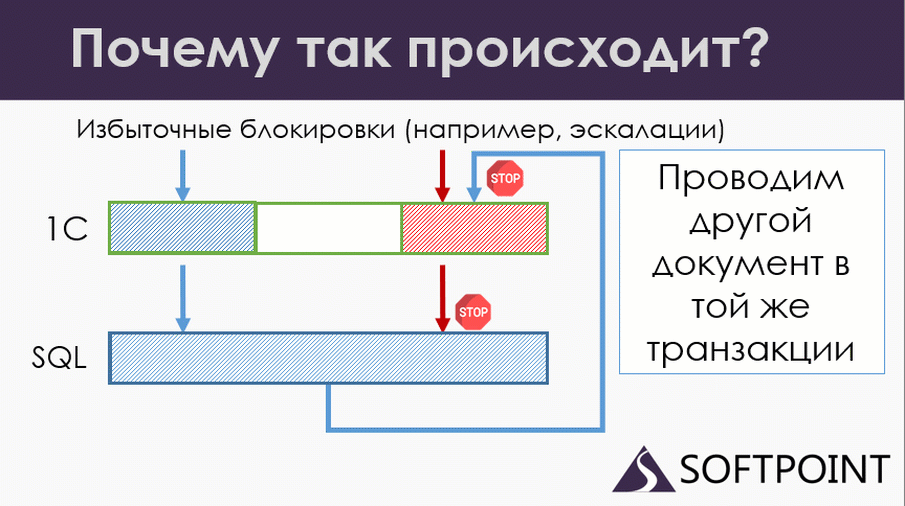
Первый документ из обмена пишет данные в SQL. И в этот момент у нас возникает эскалация блокировок.
Что такое эскалация? Есть такой механизм в SQL server: когда сиквел видит большое число блокировок или когда ему не хватает памяти для блокировок, он принимает решение о том, что вместо того, чтобы управлять большим роем каких-то мелких страничных единичных блокировок, он может взять одну большую, но на всю таблицу. (В документации механизм подробно описан в старой статье и вскользь упоминается в более актуальной версии)
Винить СУБД его в этом преждевременно, потому что если у нас есть какая-то большая долгая транзакция, очень много движений и так далее, то эта табличная блокировка может ускорить выполнение транзакции процентов на 10, не меньше. И это может быть действительно полезным. Ну и не забываем про экономию системных ресурсов.
Итак, мы попадаем на эскалацию блокировок. Синяя транзакция у нас записывает документ. Она не знает о том, что у нас заблокируется таблица, ей все равно. Она записала, пошла дальше. Красная сессия пытается записать данные, попадает на заблокированную таблицу, ждет. Пока еще ничего страшного.
-
Продолжаем. Синяя транзакция переходит к следующему документу и проводит его по правилам: начинает его проводить с управляемой блокировкой, и, естественно, попадает на блокировку красной транзакции.
И вот у нас опять два ожидания на разных уровнях. Ожидания пересеклись, но ни одна из сессий не понимает, что происходит. Тот самый распределенный дедлок, с которого я начинал.
Что делать?
Как это происходит, более-менее стало понятно. Что теперь с этим делать? Во-первых, для начала нужно просто быть готовым к тому, что такие вещи могут быть. Если у вас какие-то странные долгие блокировки, надо понимать, что, может быть, ситуация чуть сложнее, чем вам кажется на первый взгляд. Может быть, нужно поискать в другом каком-то месте.
Применительно к тому, что я сейчас рассказал, как это ни банально звучит, нужно просто соблюдать правила одинакового захвата ресурсов. Да, этому всех учат, это все знают. Но иногда забывают. Это нужно проверять, это действительно помогает. То есть всегда и везде, где бы мы ни писали, всегда пишем все ресурсы, все регистры в одном и том же порядке.
Надо проверять, что управляемые блокировки защищают все записи: отмену проведений, перепроведений, все, что угодно. Ни одной дыры не оставляем. Если уж у нас есть управляемые блокировки, они всегда должны стоять перед любой записью, чтобы нам потом не приходилось ломать голову, искать, где дыра.
Надо еще следить за порогами эскалации, которые могут происходить не только на сиквеле, но и на 1С. У 1С тоже есть свои пороги эскалации блокировок, и нужно учитывать, что у вас могут быть избыточные блокировки, табличные, страничные…
Но более глобальное правило, более глобальный вывод из всего этого: если вы видите какую-то долгую транзакцию, которая держит всех, и есть признаки того, что она ничего не делает, возможно, она действительно кого-то ждет, но на другом уровне. Это необязательно может быть 1С или SQL. Ситуации могут быть совершенно разные. Это может быть, например, ожидание какой-нибудь веб-сервиса, ответа от веб-сервиса, который, в свою очередь, кого-то ждет. Это могут быть какие-то блокировки на файловом доступе, если мы что-то пишем в файл, он чем-то занят и так далее. Мы один раз видели даже такую ситуацию, что были блокировки из-за обращения к аппаратному ключу. То есть может быть все, что угодно. И если вы не видите какого-то простого выхода из своей ситуации на одном уровне, нужно смотреть, что происходит вокруг. Возможно, где-то с другой стороны есть какое-то дополнительное ожидание.
Предел аппаратных ресурсов
Второй кейс, о котором хотелось поговорить – это предел аппаратных ресурсов. Тут ситуация начиналась чуть более просто, чуть более обычно. Поступила заявка, что есть тяжелый отчет, тяжелый запрос, который нужно ускорить, чтобы он выполнялся за какое-то приемлемое время. Запрос мы с помощью нашего мониторинга очень быстро нашли, он выполнялся две с половиной минуты, даже чуть больше. И встал вопрос, что же с ним делать.
Какой самый простой и быстрый выход из ситуации? Всегда можно попытаться откупиться от этого запроса железом. То есть покупаем ssd, добавляем оперативной памяти, процессоров, ядер, частоты. В принципе это понятно, потому что облака уже не то что на пороге стоят, они уже давно по-хозяйски сидят в гостинной, они уже везде. И вместо того, чтобы следить 2 часа за программистом и потом ждать окна для обновления конфигурации, гораздо проще и быстрее кликом мышки накинуть еще 100 гигабайт оперативной памяти и потом пытаться не вспоминать, какой счет придет за хостинг.
Собственно, первая реакция была – нарастить железо. Но потом мы схватились за калькулятор и начали считать, но не цены, а байты. И что мы видим?
У нас есть 392 миллиона чтений, а сиквел читает данные всегда по 8 килобайт, страницами. То есть 392 миллиона чтений это почти 3 терабайта данных.

Смотрим дальше. У нас на проблемном сервере стояла память DDR3. Читаем её спецификации: эта память может дать максимальный поток 19 гигабайт в секунду, это предел шины.
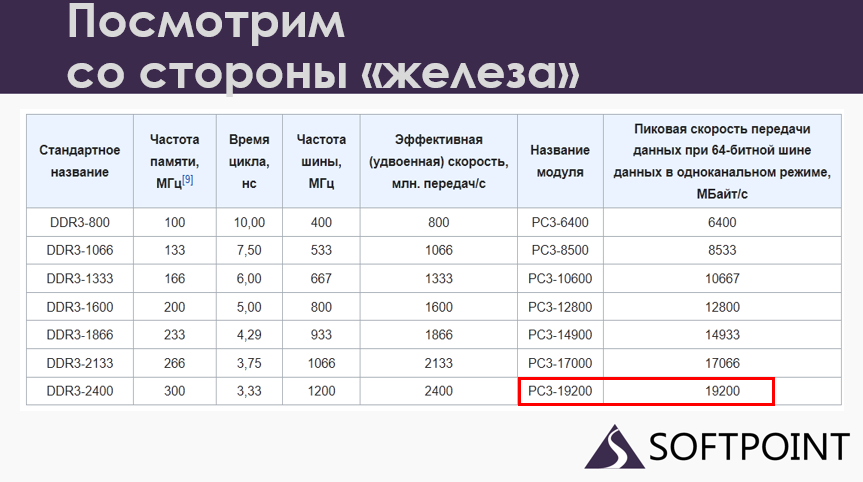
Берем калькулятор, делим 3 терабайта на 19 гигабайт и получаем те самые 2,6 минуты. Это то, что мы и видели. Получается, сколько сейчас не добавляй ssd, оперативки, чего-то ещё, мы нисколько этот поток не ускорим. Мы уперлись в потолок.

Еще одна плохая новость, что этот предел, 19 гигабайт, эта шина делится на всех. И даже если одному пользователю повезло, и он захватил всю шину, и он ждет 2,6 минуты вместо 10, как обычно, это просто означает, что эти 2,6 минуты все остальные пользователи ждут, пока он освободит шину. Они вообще ничего делать не могут. То есть страдают все.
И единственный выход, поскольку железо не поможет, – надо ждать программистов и оптимизировать запрос. Другого выхода здесь нет. Так – при помощи трассы и калькулятора и без вкладывания денег в железо – мы заранее поняли, что нужно сразу переходить к оптимизации.
Что объединяет эти два кейса?
То, что не надо замыкаться при поиске проблемы на каком-то одном уровне. Что распределенные дедлоки, где не надо искать причины только на том уровне, который вы видите, что в этом запросе, где, казалось бы, мы сразу увидели, как его можно решить.
Нужно всегда помнить, что есть и другие ограничения. Есть ограничение железа, есть ограничение каких-то блокировочных пространств, есть ограничение пропускной способности и так далее. Важно очень помнить, что система – это не разрозненные какие-то кубики, а их сумма. И эти кубики могут не только помогать, но и негативно влиять друг на друга.

Очень важно не замыкаться в одном контуре, на одном уровне разбора проблемы, а стараться смотреть в комплексе.
Спецификации DDR3 SDRAM взяты в Википедии https://ru.wikipedia.org/wiki/DDR3_SDRAM
В презентации использовались иконки www.flaticon.com (CC-BY 3.0)
**************************************************************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 EDUCATION. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Надеюсь что не скоро достигну предела DDR3 SDRAM )
А так все логично- Порядок бьёт класс
Отличное подтверждение этой фразы.
Если писать код изначально хорошо, можно на многие грабли и не наступать
Интересно что при поиске англоязычного эквивалента Порядок бьёт класс выводится
Football is a simple game; 22 men chase a ball for 90 minutes and at the end, the Germans win.
)
Странно, мне даже в голову не приходило оптимизировать запрос увеличением железа не посмотрев сначала на код.
Добавление памяти решает проблему объединения доработанных конфигураций.
Если около часа идёт только сравнение метаданных, а тестирование базы проходит за 20-25 минут, то какие могут быть претензии к СУБД ? Это даже близко не хайлоад.
Только неумение дорабатывать конфигурации вероятно.
Конфигурации с расширениями надеюсь менее требовательны к железу.
(0) Отличный доклад и статья. +
Прошу прояснить и уточнить терминологию в статье:
Простите, но очень неоднозначная и неаккуратная фраза. Что это значит? Перед какой такой «любой» записью? Речь об управляемых блокировках 1С? Или о транзакционных СУБД? НаборЗаписейРС.Записать() — какая тут нужна блокировка «перед записью» по Вашему?
Еще, в том же духе:
Что значит «не закрыл»? Как надо «закрывать»? О чем речь? Надо ли «закрывать», если у документа свойство «Удаление движений = удалять автоматически при отмене проведения»? Вот честно, с 1С уже много лет работаю, ни разу никакую отмену проведения дополнительными блокировками «закрывать» не приходилось.
Я то смысл понял на самом деле и звучит он так:
1 документ при удалении движений в ходе перепроведения наложил исключительную транзакционную блокировку СУБД на большой пул строк в таблице. Блокировка эта держится до конца транзакции, разумеется.
2 документ запросом в обработке проведения анализирует какие-то данные, перед чтением ставит управляемую блокировку 1С (которая тоже держится до конца транзакции конечно же), что-то вычисляет, пытается записать полученные данные в ту же саму таблицу БД, которую держит документ 1. Натыкается на транзакционную X блокировку. Включается тайм-аут СУБД для документа 2.
1 документ к этому моменту времени уже успел добраться в ходе своей транзакции до того же самого запроса и до того же самого наложения блокировки 1С перед чтением. Разумеется, система ему пересекающуюся управляемую блокировку 1С наложить не дает. Включается тайм-аут 1С для документа 1.
Ну и дальше — какой из тайм-аутов первый истечет — та сессия и отвалится.
Ну и насчет неочевидности.
Вот прекрасная статья:
Автор — издатель известного курса по оптимизации производительности.
Так что про «закрывать» непонятно.
Сколько не расследовал причин тормозов и долгого выполнения чего-то — в большинстве случаев виновником был 1С (платформа, кривой код программистов 1С). Памяти не хватало по причине утечек памяти из-за цикличных ссылок в той же БСП, в самой платформе. В раздутых метаданных ролей. Дорогущий сервер — постоянно «холодный», а работа идет со скрипом.
Кстати сам SQL сервер от Microsoft тоже сюрпризы приподносит. Простая ситуация — в базе одна… база. Есть процедура использующая CTE и временные таблицы. Из таблицы в 1 млн строк — создает таблицу на 30 млн строк. Ограничение по памяти выставлено в 30Гб. Первый запуск процедуры выполняется 30 минут и заполняет память до 25Гб. Второй запуск процедуры (после удаления всего что она нагенерила) — 5 часов. Память SQL сервером не освобождается. Если после каждого запуска процедуры перезапускать SQL сервер, то процедура всегда выполняется за 30 минут (чистка процедурного кэша, обновление статистики не помогает, добавление индексов к таблице усугубляет ситуацию еще больше)…
Был один случай недавно. Пользователи Windows XP жаловались на долгий запуск 1С, который долгим стал после перехода на новую платформу. Первая мысль — если XP, значит мало ресурсов, значит слабые компьютеры, надо модернизировать. Вторая мысль — но раньше у них проблем ведь не было?
Причина оказалось в том, что админы порезали прохождение пакетов протокола SMB1 (netbios), чтобы предотвратить распространение вируса типа WannaCry. А ходить пакеты перестали именно в ту подсеть, где располагался новый сервер под новую платформу. В XP в этом случае идет 2-х минутная задержка, после чего идет использование другого протокола (более защищенного). Выяснилось все это только с помощью настроенного ТЖ на стороне клиента. С другими программами на той же машине таких проблем нет. Стало быть дело в механизме создания защищенного соединения на стороне 1С.
(5)
Ок, по пунктам:
Тут «они» явно указывают на предыдущее существительное с прилагательным — то есть, на «управляемые блокировки».
— значит, не убедился, что управляемая блокировка будет установлена (им самим или платформой)
— тут нужна управляемая блокировка. Если код выполняется в платформе 8.3, платформа сама поставит эту блокировку (что не означает, что блокировка «не нужна»). Если, как в примере из доклада, мы говорим о старой конфигурации на старой платформе, управляемую блокировку поставить не получится.
К слову, транзакционная блокировка СУБД тут, конечно, тоже нужна, но она сама появится непосредственно при выполнении записи.
—см. выше, закрывать не надо, но помнить, про то, что управляемая блокировка есть, необходимо.
— я тоже видел такие ситуации от силы пару раз. Именно поэтому доклад называется «неочевидные проблемы» и именно поэтому хотелось рассказать о любопытном случае, чтобы коллеги потом меньше ломали голову.
(2) Ну я и не говорил, что заливать проблему железом — правильный путь.
Да и вообще смысл этого случая — не показать, как ловко можно оперативкой ускорить плохой запрос, а наоборот, продемонстрировать предел такой «оптимизации»
(6) Мой опыт как минимум 6 последних лет работы в Софтпоинт с обращениями заказчиков говорит о том, что проблемы могут быть где угодно — и на 1С, и на СУБД, и на уровне железа… И ваш последний пример отлично это иллюстрирует (и, кстати, ложится в тему статьи). Действительно, первая реакция в таком случае — это обвинить во всех проблемах обновленную платформу. Хотя более глубокая причина лежит в другой плоскости, в настройках сети.
(9) Только это не проблема сети, а то как ведет себя 1С при таких настройках, с другим софтом проблем нет.
Вот еще один пример — есть виртуалка на Hyper-V, в момент снятия бэкапа средствами Volume Shadow Copy возникают проблемы с таймаутом на драйвере диска. При этом менеджер кластера — зависает совсем не надолго. Агент кластера видит, что завис менеджер кластера и его…. убивает. При этом 1С не предоставляет никаких настроек для увеличения времени ожидания отклика менеджера и т.д. Другой софт реагирует адекватно, ничего не падает и не завершается.
(10)
Есть настройки запуска службы агента, которые вероятно Вам помогут, посмотрите
/pingPeriod <время> /pingTimeout <время>
(11) Эта настройка работает только для рабочих процессов, агент сервера (ragent) не пытается пинговать менеджер клстера (rmngr), а просто его убивает, если тот решил «подвиснуть» на пару секунд. Настройка pingTimeout уже давно стоит и суммарное время там больше минуты. Не действует она на менеджер, хоть тресни.