
Стек
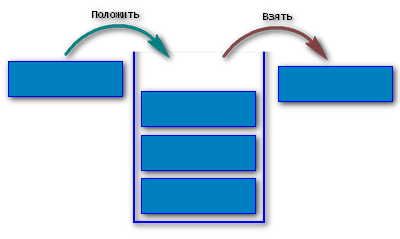
Стек — это абстрактный тип данных, представляющий собой список элементов, организованных по принципу ЛИФО ("последним пришел — первым вышел").
Основные операции со стеком это:
-
Push – вставка элемента наверх стека;
-
Top – получение верхнего элемента без удаления;
-
Pop – получение верхнего элемента и его удаление;
-
isEmpty – возвращает true, если стек пуст.
Для реализации стека будем использовать тип данных Массив. Реализуем вышеописанные операции:
#Область Стек
Функция Стек_Новый()
Возврат Новый Массив;
КонецФункции
// Push
Процедура Стек_Положить(Стек, Значение)
Стек.Добавить(Значение);
КонецПроцедуры
// Top
Функция Стек_ВзятьБезУдаления(Стек)
Возврат Стек[Стек.ВГраница()];
КонецФункции
// Pop
Функция Стек_Взять(Стек)
ИндексПоследнегоЭлемента = Стек.ВГраница();
Значение = Стек[ИндексПоследнегоЭлемента];
Стек.Удалить(ИндексПоследнегоЭлемента);
Возврат Значение;
КонецФункции
// isEmpty
Функция Стек_Пустой(Стек)
Возврат Стек.Количество() = 0;
КонецФункции
#КонецОбласти
Эти операции работают как в тонком так и в других клиентах.
Пример того, как использовать стек
Вроде все просто и быстро работает.
Очередь
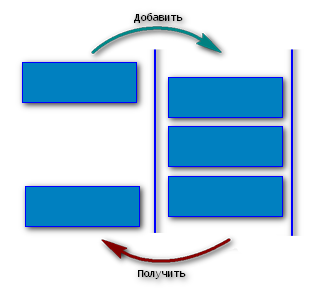
Очередь — это абстрактный тип данных, представляющий собой список элементов, организованных по принципу ФИФО ("первый пришел — первый вышел").
Основные операции с очередью это:
-
Добавить элемент в конец очереди;
-
Получить элемент из начала очереди (без удаления из очереди);
-
Получить элемент из начала очереди (с удалением из очереди);
-
Проверка пустая ли очередь.
Так же как и для стека будем использовать тип данных Массив. Реализуем вышеописанные операции.
#Область Очередь
Функция Очередь_Новый()
Возврат Новый Массив;
КонецФункции
Процедура Очередь_Добавить(Очередь, Значение)
Очередь.Добавить(Значение);
КонецПроцедуры
Функция Очередь_ПолучитьБезУдаления(Очередь)
Возврат Очередь[0];
КонецФункции
Функция Очередь_Получить(Очередь)
Значение = Очередь[0];
Очередь.Удалить(0);
Возврат Значение;
КонецФункции
Функция Очередь_Пустой(Очередь)
Возврат Очередь.Количество() = 0;
КонецФункции
#КонецОбласти
Пример использования очереди
Здесь тоже все просто, но что по скорости? Поскольку отличие в только в способе получения элемента данных, то сравним скорость работы функции Очередь_Получить(Очередь) с Стек_Взять(Стек). Замеры производительности показали:
| Строка кода | 10 000 элементов | 50 000 элементов | 100 000 элементов | |||
| Время чистое | % | Время чистое | % | Время чистое | % | |
| Стек (Стек_Взять(Стек)) | 0,170986 | 43,97 | 0,877694 | 21,25 | 1,703886 | 14,30 |
| ИндексПоследнегоЭлемента = Стек.ВГраница(); | 0,064098 | 16,48 | 0,330289 | 8,00 | 0,639357 | 5,37 |
| Значение = Стек[ИндексПоследнегоЭлемента]; | 0,047934 | 12,33 | 0,244083 | 5,91 | 0,475707 | 3,99 |
| Стек.Удалить(ИндексПоследнегоЭлемента); | 0,058954 | 15,16 | 0,303322 | 7,34 | 0,588822 | 4,94 |
| Очередь (Очередь_Получить(Очередь)) | 0,217842 | 56,03 | 3,253449 | 78,75 | 10,2105 | 85,70 |
| Значение = Очередь[0]; | 0,058589 | 15,07 | 0,333911 | 8,08 | 0,535987 | 4,50 |
| Очередь.Удалить(0); | 0,159253 | 40,96 | 2,919538 | 70,67 | 9,674513 | 81,20 |
| Итого | 0,388828 | 100,00 | 4,131143 | 100,00 | 11,914386 | 100,00 |
Динамика ожидаемая. Поскольку при получении элемента очереди из массива удаляется нулевой элемент, то и работает это дольше из-за того, что массив каждый раз "сдвигает" индексы. Но оказалось, что в 1С метод массива ВГраница() "не дешевый".
Если размер очереди не превышает 10 000 элементов, то разница в скорости между очередью и стеком не заметна, т.е. такая реализация Очереди работает также быстро как и Стек. В остальном же, чем больше элементов в очереди, тем медленнее будет работать операция получения. А что делать, если у нас могут быть очереди огромных размеров? Способ известен, избавляемся от удаления нулевого элемента в массиве и у нас получается следующее:
#Область Очередь
Функция Очередь_Новый()
Возврат Новый Структура("Данные, Голова, Хвост", Новый Массив, 0, 0)
КонецФункции
Процедура Очередь_Добавить(Очередь, Значение)
Очередь.Данные.Добавить(Значение);
Очередь.Хвост = Очередь.Хвост + 1;
КонецПроцедуры
Функция Очередь_ПолучитьБезУдаления(Очередь)
Возврат Очередь.Данные[Очередь.Голова];
КонецФункции
Функция Очередь_Получить(Очередь)
Значение = Очередь.Данные[Очередь.Голова];
Очередь.Голова = Очередь.Голова + 1;
Возврат Значение;
КонецФункции
Функция Очередь_Пустой(Очередь)
Возврат Очередь.Голова = Очередь.Хвост;
КонецФункции
#КонецОбласти
Сравним скорость работы со стектом
| Строка кода | 10 000 элементов | 50 000 элементов | 100 000 элементов | |||
| Время чистое | % | Время чистое | % | Время чистое | % | |
| Стек | 0,330505 | 43,37 | 1,633625 | 44,14 | 3,288941 | 43,81 |
| Возврат Новый Массив; | 0,000014 | 0,00 | 0,000014 | 0,00 | 0,000015 | 0,00 |
| Стек.Добавить(Значение); | 0,069462 | 9,11 | 0,340238 | 9,19 | 0,680083 | 9,06 |
| ИндексПоследнегоЭлемента = Стек.ВГраница(); | 0,063925 | 8,39 | 0,321949 | 8,70 | 0,649467 | 8,65 |
| Значение = Стек[ИндексПоследнегоЭлемента]; | 0,047449 | 6,23 | 0,239641 | 6,47 | 0,477748 | 6,36 |
| Стек.Удалить(ИндексПоследнегоЭлемента); | 0,05953 | 7,81 | 0,29952 | 8,09 | 0,597924 | 7,96 |
| Возврат Стек.Количество() = 0; | 0,090125 | 11,83 | 0,432263 | 11,68 | 0,883704 | 11,77 |
| Очередь | 0,431625 | 56,63 | 2,067537 | 55,86 | 4,219035 | 56,19 |
| Возврат Новый Структура("Данные, Голова, Хвост", Новый Массив, 0, 0) | 0,000054 | 0,01 | 0,000046 | 0,00 | 0,000049 | 0,00 |
| Очередь.Данные.Добавить(Значение); | 0,09672 | 12,69 | 0,442808 | 11,96 | 0,943409 | 12,57 |
| Очередь.Хвост = Очередь.Хвост + 1; | 0,096046 | 12,60 | 0,4312 | 11,65 | 0,857976 | 11,43 |
| Значение = Очередь.Данные[Очередь.Голова]; | 0,075233 | 9,87 | 0,37646 | 10,17 | 0,752637 | 10,02 |
| Очередь.Голова = Очередь.Голова + 1; | 0,083533 | 10,96 | 0,418471 | 11,31 | 0,835261 | 11,12 |
| Возврат Очередь.Голова = Очередь.Хвост; | 0,080039 | 10,50 | 0,398552 | 10,77 | 0,829703 | 11,05 |
| Итого | 0,76213 | 100,00 | 3,701162 | 100,00 | 7,507976 | 100,00 |
Конечно, очередь все равно работает чуть медленнее стека, но разница не так заметна и она уже не растет при размере более 10 000. Но у нас растет размер массива.
Приоритетная очередь
Приоритетная очередь — это абстрактная структура данных, где у каждого элемента есть приоритет. Элемент с более высоким приоритетом находится перед элементом с более низким приоритетом. Если у элементов одинаковые приоритеты, они располагаются в зависимости от своей позиции в очереди.

Очередь с приоритетом использует такие же операции что и обычная очередь:
-
Добавить элемент в конец очереди;
-
Получить элемент из начала очереди (без удаления из очереди);
-
Получить элемент из начала очереди (с удалением из очереди);
-
Проверка пустая ли очередь.
Какой же тип выбрать для этой структуры данных? Теперь наряду с элементом, необходимо хранить приоритет. Простым способом будет выбрать тип, у которого есть методы сортировки. Очевидно, что массив не подойдет. Что мы имеем:
- Соответствие — при добавлении элемента сортирует данные по ключу, но ключ должен быть уникальным. Нам не подходит, потому как могут быть элементы с одинаковым приоритетом. На самом деле можно сделать ключ уникальным и "правильным" для нас образом сортируемым. Но сейчас я не буду рассматривать его как претендента для реализации приоритетной очереди.
- ТаблицаЗначений — есть метод Сортировать(), а также можно добавлять сколь угодно колонок. Подходит, но есть ограничение — не работает в тонком клиенте.
- СписокЗначений — есть методы СортироватьПоПредставлению() и СортироватьПоЗначению(). Подходит, работает как в тонком, так и в других клиентах.
Поскольку метод сортировки может занимать много времени, то заранее продумаем способ лишний раз его не вызывать. Так же обратим внимание на то, что элементы с одинаковым приоритетом должны располагаться в зависимости от своей позиции в очереди, а методы сортировки таблицы значений и списка значений такого делать не умеют. После сортировки элементов с одинаковым приоритетом позиции будут "случайными". Поэтому нам необходимо хранить позцию в очереди и производить сортировку по ней тоже.
Реализуем приоритетную очередь используя тип ТаблицаЗначений:
#Область ПриоритетнаяОчередь_ТаблицаЗначений
Функция ПриоритетнаяОчередь_Новый()
Очередь = Новый Структура;
Очередь.Вставить("Отсортировано", Истина);
Очередь.Вставить("Данные", Новый ТаблицаЗначений);
Очередь.Данные.Колонки.Добавить("Значение");
Очередь.Данные.Колонки.Добавить("Приоритет", Новый ОписаниеТипов("Число"));
Очередь.Данные.Колонки.Добавить("Позиция", Новый ОписаниеТипов("Число"));
Очередь.Вставить("Позиция", 0);
Возврат Очередь;
КонецФункции
Процедура ПриоритетнаяОчередь_Добавить(Очередь, Значение, Приоритет)
Очередь.Отсортировано = Ложь;
НоваяСтрока = Очередь.Данные.Добавить();
НоваяСтрока.Значение = Значение;
НоваяСтрока.Приоритет = Приоритет;
НоваяСтрока.Позиция = Очередь.Позиция + 1;
Очередь.Позиция = НоваяСтрока.Позиция;
КонецПроцедуры
Функция ПриоритетнаяОчередь_ПолучитьБезУдаления(Очередь)
Данные = Очередь.Данные;
Если Не Очередь.Отсортировано Тогда
Очередь.Отсортировано = Истина;
Данные.Сортировать("Приоритет, Позиция");
КонецЕсли;
Возврат Данные[0].Значение;
КонецФункции
Функция ПриоритетнаяОчередь_Получить(Очередь)
Данные = Очередь.Данные;
Если Не Очередь.Отсортировано Тогда
Очередь.Отсортировано = Истина;
Данные.Сортировать("Приоритет, Позиция");
КонецЕсли;
Значение = Данные[0].Значение;
Данные.Удалить(0);
Возврат Значение;
КонецФункции
Функция ПриоритетнаяОчередь_Пустой(Очередь)
Возврат Очередь.Данные.Количество() = 0;
КонецФункции
#КонецОбласти
Пример использования приоритетной очереди
Стоит отметить, что удаление строки из таблицы значений по нулевому индексу работает немного быстрее, чем удаление последней строки. Т.е. таблица значенией не имеет проблемы "сдвигов" индекса. Таблица значений похожа на структуру данных Связанный список.
Далее реализуем приоритетную очередь на списке значений и уже там сравним скорость работы.
Реализуем приоритетную очередь используя тип СписокЗначений:
В Списке значений для хранения Приоритета будем использовать Представление. И вот здесь наталкиваемся на ограничение — Представление имеет тип Строка, а Приоритет у нас Число. Таким образом Приоритет из Числа преобразуется в Строку и метод СортироватьПоПредставлению() неправильно будет работать для нашей цели (например строки 1, 2, 10, 20, 100, 200 будут упорядочены сделующим образом 1, 10, 100, 2, 20, 200). Чтобы добиться "правильной" сортировки нам необходимо число привести в соответствующий строковый вид, например, числа 1, 2, 10, 20, 100, 200 приводим к строкам 001, 002, 010, 020, 100, 200. Для этого нам необхомо с определиться с длиной (разрядностью) и "дорисовать" лидирующие нули. Длина влияет на скорость сортировки, поэтому будем реализовывать так, чтобы можно было заранее указать разрядность. Вспоминаем еще один момент со "сдвигами" индексов, список значений эту "проблему" имеет, поэтому сортируем по убыванию, а получаем элемент сверху. В результате получаем следующее:
#Область ПриоритетнаяОчередь_СписокЗначений
&НаКлиенте
Функция ПриоритетнаяОчередь_Новый(РазрядностьПриоритета = 16, РазрядностьПозиции = 16)
Очередь = Новый Структура;
Очередь.Вставить("Отсортировано", Истина);
Очередь.Вставить("Данные", Новый СписокЗначений);
Очередь.Вставить("ФорматнаяСтрокаПриоритета", "ЧЦ=" + РазрядностьПриоритета + "; ЧН=; ЧВН=; ЧГ=0");
Очередь.Вставить("ФорматнаяСтрокаПозиции", "ЧЦ=" + РазрядностьПозиции + "; ЧН=; ЧВН=; ЧГ=0");
Очередь.Вставить("Позиция", 0);
Возврат Очередь;
КонецФункции
&НаКлиенте
Процедура ПриоритетнаяОчередь_Добавить(Очередь, Значение, Приоритет)
Очередь.Отсортировано = Ложь;
Очередь.Позиция = Очередь.Позиция + 1;
ПриоритетСтрока = Формат(Приоритет, Очередь.ФорматнаяСтрокаПриоритета) + Формат(Очередь.Позиция, Очередь.ФорматнаяСтрокаПозиции);
Очередь.Данные.Добавить(Значение, ПриоритетСтрока);
КонецПроцедуры
&НаКлиенте
Функция ПриоритетнаяОчередь_ПолучитьБезУдаления(Очередь)
Данные = Очередь.Данные;
Если Не Очередь.Отсортировано Тогда
Очередь.Отсортировано = Истина;
Данные.СортироватьПоПредставлению(НаправлениеСортировки.Убыв);
КонецЕсли;
ИндексПоследнегоЭлемента = Данные.Количество() - 1;
Возврат Данные[ИндексПоследнегоЭлемента].Значение;
КонецФункции
&НаКлиенте
Функция ПриоритетнаяОчередь_Получить(Очередь)
Данные = Очередь.Данные;
Если Не Очередь.Отсортировано Тогда
Очередь.Отсортировано = Истина;
Данные.СортироватьПоПредставлению(НаправлениеСортировки.Убыв);
КонецЕсли;
ИндексПоследнегоЭлемента = Данные.Количество() - 1;
Значение = Данные[ИндексПоследнегоЭлемента].Значение;
Данные.Удалить(ИндексПоследнегоЭлемента);
Возврат Значение;
КонецФункции
&НаКлиенте
Функция ПриоритетнаяОчередь_Пустой(Очередь)
Возврат Очередь.Данные.Количество() = 0;
КонецФункции
#КонецОбласти
Если удобней передавать максимальное число, а не разрядность то фукнция ПриоритетнаяОчередь_Новый() будет выглядеть так:
&НаКлиенте
Функция ПриоритетнаяОчередь_Новый(МаксимальноеЧислоПриоритета = Неопределено, МаксимальноеЧислоПозиции = Неопределено)
РазрядностьПриоритета = ?(МаксимальноеЧислоПриоритета = Неопределено, 16, СтрДлина(Формат(МаксимальноеЧислоПриоритета, "ЧГ=0")));
РазрядностьПозиции = ?(МаксимальноеЧислоПозиции = Неопределено, 16, СтрДлина(Формат(МаксимальноеЧислоПозиции, "ЧГ=0")));
Очередь = Новый Структура;
Очередь.Вставить("Отсортировано", Истина);
Очередь.Вставить("Данные", Новый СписокЗначений);
Очередь.Вставить("ФорматнаяСтрокаПриоритета", "ЧЦ=" + РазрядностьПриоритета + "; ЧН=; ЧВН=; ЧГ=0");
Очередь.Вставить("ФорматнаяСтрокаПозиции", "ЧЦ=" + РазрядностьПозиции + "; ЧН=; ЧВН=; ЧГ=0");
Очередь.Вставить("Позиция", 0);
Возврат Очередь;
КонецФункции
Сравним обе реализиции приоритетной очереди по скорости:
| Строка кода | 10 000 элементов | 50 000 элементов | 100 000 элементов | |||
| Время чистое | % | Время чистое | % | Время чистое | % | |
| Приоритетная очередь (таблица значений) | 1,1063 | 35,81 | 6,100376 | 37,26 | 12,214519 | 37,28 |
| Очередь = Новый Структура; | 0,000014 | 0,00 | 0,000013 | 0,00 | 0,000014 | 0,00 |
| Очередь.Вставить("Отсортировано", Истина); | 0,000023 | 0,00 | 0,000022 | 0,00 | 0,000022 | 0,00 |
| Очередь.Вставить("Данные", Новый ТаблицаЗначений); | 0,000025 | 0,00 | 0,000023 | 0,00 | 0,000024 | 0,00 |
| Очередь.Данные.Колонки.Добавить("Значение"); | 0,000049 | 0,00 | 0,000071 | 0,00 | 0,000046 | 0,00 |
| Очередь.Данные.Колонки.Добавить("Приоритет", Новый ОписаниеТипов("Число")); | 0,000049 | 0,00 | 0,000049 | 0,00 | 0,000048 | 0,00 |
| Очередь.Данные.Колонки.Добавить("Позиция", Новый ОписаниеТипов("Число")); | 0,00004 | 0,00 | 0,000041 | 0,00 | 0,000041 | 0,00 |
| Очередь.Вставить("Позиция", 0); | 0,000014 | 0,00 | 0,000014 | 0,00 | 0,000014 | 0,00 |
| Очередь.Отсортировано = Ложь; | 0,059319 | 1,92 | 0,296483 | 1,81 | 0,599376 | 1,83 |
| НоваяСтрока = Очередь.Данные.Добавить(); | 0,128262 | 4,15 | 0,758155 | 4,63 | 1,073491 | 3,28 |
| НоваяСтрока.Значение = Значение; | 0,066091 | 2,14 | 0,332992 | 2,03 | 0,672613 | 2,05 |
| НоваяСтрока.Приоритет = Приоритет; | 0,060047 | 1,94 | 0,305085 | 1,86 | 0,610112 | 1,86 |
| НоваяСтрока.Позиция = Очередь.Позиция + 1; | 0,098084 | 3,17 | 0,461481 | 2,82 | 0,903573 | 2,76 |
| Очередь.Позиция = НоваяСтрока.Позиция; | 0,060872 | 1,97 | 0,298918 | 1,83 | 0,616223 | 1,88 |
| Данные = Очередь.Данные; | 0,06077 | 1,97 | 0,305511 | 1,87 | 0,603819 | 1,84 |
| Если Не Очередь.Отсортировано Тогда | 0,050897 | 1,65 | 0,252758 | 1,54 | 0,499659 | 1,52 |
| Очередь.Отсортировано = Истина; | 0,000004 | 0,00 | 0,000005 | 0,00 | 0,000004 | 0,00 |
| Данные.Сортировать("Приоритет, Позиция"); | 0,127592 | 4,13 | 1,042711 | 6,37 | 2,588318 | 7,90 |
| КонецЕсли; | 0,029566 | 0,96 | 0,148514 | 0,91 | 0,290742 | 0,89 |
| Значение = Данные[0].Значение; | 0,10961 | 3,55 | 0,583075 | 3,56 | 1,152302 | 3,52 |
| Данные.Удалить(0); | 0,142949 | 4,63 | 0,738205 | 4,51 | 1,485553 | 4,53 |
| Возврат Очередь.Данные.Количество() = 0; | 0,112023 | 3,63 | 0,57625 | 3,52 | 1,118525 | 3,41 |
| Приоритетная очередь (список значений) | 1,983387 | 64,19 | 10,273666 | 62,74 | 20,553372 | 62,72 |
| Очередь = Новый Структура; | 0,000016 | 0,00 | 0,000016 | 0,00 | 0,000025 | 0,00 |
| Очередь.Вставить("Отсортировано", Истина); | 0,000022 | 0,00 | 0,000023 | 0,00 | 0,000024 | 0,00 |
| Очередь.Вставить("Данные", Новый СписокЗначений); | 0,000019 | 0,00 | 0,000019 | 0,00 | 0,000019 | 0,00 |
|
Очередь.Вставить("ФорматнаяСтрокаПриоритета", "ЧЦ=" + РазрядностьПриоритета + "; ЧН=; ЧВН=; ЧГ=0"); |
0,000063 | 0,00 | 0,000052 | 0,00 | 0,000051 | 0,00 |
| Очередь.Вставить("ФорматнаяСтрокаПозиции", "ЧЦ=16; ЧН=; ЧВН=; ЧГ=0"); | 0,000014 | 0,00 | 0,000014 | 0,00 | 0,000014 | 0,00 |
| Очередь.Вставить("Позиция", 0); | 0,000014 | 0,00 | 0,000014 | 0,00 | 0,000014 | 0,00 |
| Очередь.Отсортировано = Ложь; | 0,056188 | 1,82 | 0,284132 | 1,74 | 0,560949 | 1,71 |
| Очередь.Позиция = Очередь.Позиция + 1; | 0,104786 | 3,39 | 0,443424 | 2,71 | 0,866142 | 2,64 |
|
ПриоритетСтрока = Формат(Приоритет, Очередь.ФорматнаяСтрокаПриоритета)+ Формат(Очередь.Позиция, Очередь.ФорматнаяСтрокаПозиции); |
0,951056 | 30,78 | 4,927951 | 30,10 | 9,781007 | 29,85 |
| Очередь.Данные.Добавить(Значение, ПриоритетСтрока); | 0,125726 | 4,07 | 0,630631 | 3,85 | 1,257842 | 3,84 |
| Данные = Очередь.Данные; | 0,052208 | 1,69 | 0,261573 | 1,60 | 0,51975 | 1,59 |
| ИндексПоследнегоЭлемента = Данные.Количество() — 1; | 0,092614 | 3,00 | 0,508852 | 3,11 | 0,949622 | 2,90 |
| Если Не Очередь.Отсортировано Тогда | 0,049787 | 1,61 | 0,239129 | 1,46 | 0,478487 | 1,46 |
| Очередь.Отсортировано = Истина; | 0,000005 | 0,00 | 0,000005 | 0,00 | 0,000005 | 0,00 |
| Данные.СортироватьПоПредставлению(НаправлениеСортировки.Убыв); | 0,1789 | 5,79 | 1,101879 | 6,73 | 2,400442 | 7,33 |
| КонецЕсли; | 0,027553 | 0,89 | 0,134654 | 0,82 | 0,271737 | 0,83 |
| Значение = Данные[ИндексПоследнегоЭлемента].Значение; | 0,069322 | 2,24 | 0,344562 | 2,10 | 0,690922 | 2,11 |
| Данные.Удалить(ИндексПоследнегоЭлемента); | 0,159925 | 5,18 | 0,774589 | 4,73 | 1,612728 | 4,92 |
| Возврат Очередь.Данные.Количество() = 0; | 0,115169 | 3,73 | 0,622147 | 3,80 | 1,163592 | 3,55 |
| Итого | 3,089687 | 100,00 | 16,374042 | 100,00 | 32,767891 | 100,00 |
Важное замечание — метод сортировки во всех случаях запускался 1 раз. Сначала набиралась очередь до нужного количества элементов (10 000, 50 000 или 100 000), а потом при при первом получении происходила сортировка. Как видим, что сортировка занимает не мало времени.
У списка значений большую часть времени зняло вычисление проиоритета — перевода чисел в строку. При тестировнии я не указывал разрядность и она по умолчанию была 16, т.е. длина сортировочной строки была 32 символа (16 приоритет и 16 позиция в очереди). В тестируемых примерах я мог указать разрядность 6 и тогда сортировочная строка была бы 12 символов, что, в свою очередь, должно положительно сказаться на сортировке (а может еще и на вычислении приоритетной строки).
ПС: тесты проводились на платформе 1С 8.3.10 в файловом режиме и на процессоре Core 2 Duo 2,33GHz. И соответственно, при тестировании на другом компьютере чистое время будет другим, но процентное соотношение должно остаться прежним.
ПСС: Конструктивная критика приветствуется.
Обновлено: избавился в коде от конструкции Попытка — Исключение. Считаю, что проверка на пустую коллекцию лишняя, потому как у каждой структуры данных есть метод Пустой(), которым и должен пользоваться разработчик.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Показать
тут (и в других методах) не так сложно проверить количество элементов в массиве, зачем все эти попытки исключения ? code smells в общем
(2) При желании можно найти применение , например с помощью стека проверяют соответствие открывающихся и закрывающихся скобок (или тех же кавычек) в выражениях. В любом случае это полезные структуры
(2)
возможно его стоит предложить старшему воспитателю группы детского сада
Я, например, использую стек для организации последовательности завершения вложенных асинхронных процедур:
(4) я имел ввиду
, то что многие используют подобные алгоритмы я не сомневаюсь.
(1) Страсть как захотелось использовать здесь попытку вместо условия. Кому code smells используйте так:
Показать
(6)
В 1С не рекомендуется в общем случае перехватывать исключения.
(7) Не знал, спасибо. Теперь страсть свою поумерю.
(6)
Страсть чем-то объясняется или просто «страсть»?)
Ещё момент — Неопределено теоретически может быть правильным значением элемента. Т.е. Неопределено и «Такого элемента не существует» будут разными случаями.
а если сделать раелизацию на списке.
те на структуре, где один из элементов — другая структура?
(6)Дурацкий вопрос: Если заменить Стек.ВГраница(), на Стек.Количество()-1. Шустрее не будет?
Или вообще не использовать метод Количество() для подсчета элементов в очереди, а Один раз посчитать, а потом уменьшать это число на единицу
(9) Я думал по поводу Неопределено, можно возвращать NULL, но это также теоретически может быть правильным значением.
Вообще эти структуры данных используют программисты, а не пользователи, поэтому мне кажется, что проверки на пустую структуру данных внутри методов _Получить() излишни. Для проверки предполагается использовать метод _Пустой(), который возвращает вполне себе однозначный ответ 🙂
Здесь «страсть» объясняется тем, что с одной стороны мне не нравится проверка на пустую структуру данных внутри методов, а с другой стороны нужно предусмотреть появление ошибки, не нагромаждая код. Хотелось сделать как можно меньше кода.
(12)
Я думаю, тут можно просто разделить сущности. Т.е. возвращаемое значение — это возвращаемое значение, а сама функция возвращает (или устанавливает переданный) флаг того, что что-то было найдено или ничего не было найдено.
(11) Вопрос, кстати не дурацкий, я им сам задавался :). Стек.Количество()-1 будет медленней.
(14)тогда в методах Пустая нужно использовать Стек.Вграница()+1
(15)Но ИМХО , когда в 1С стали приходить true программеры с ООП, то стало конфы стали тормознее, заморочитей, менее логичны и сложны для отладки. ))))
(15) Стек.Количество() = 0; будет работать чуть-чуть быстрее нежели Стек.ВГраница() = -1; Почему-то
(16) Согласен. с ООП тоже есть проблемы, и часто всё превращается в лапшу.
Поэтому «Простота требует проектирования и хорошего вкуса» Линус Торвальдс.
(13) Как бы вы реализовали?
(10) Тогда необходимо подумать что будет ключами структуры? И для получения первого элемента необходимо вызывать конструкцию типа Для каждого Из Цикл. Мне кажется это будет затратно по времени, но надо тестить.
Перенёс ответ ниже
(19)
Показать
Или наоборот:
Показать
(22) Понял, получается 2 в одном. Почему бы и нет.
(23) попытка получить значение из пустой коллекции всегда должна бросать исключение. Любое значение встроенного языка может храниться в коллекции, поэтому не допустимо использовать «особое» возвращаемое значение как признак невозможности получения жначения
для проверки стека и организации цикла стеку необходим метод, возвращающий количество элементов в нем:
Показать
p.s. Подумайте на досуге, а так ли нужна вообще операция получения без удаления (peek)? Когда вы ею последний раз пользовались и зачем?
(6)
мб так?
(25) Спасибо за ссылки
(24) Совсем недавно использовал операцию без удаления из приоритетной очереди. Необходимо было найти вершину графа, которая ближе всех расположена к углу (по оси х и у). Обход вершин графа с правильным вычислением приоритетов дал результат и вконце требовалось только получить один элемент с наивысшим приоритетом. Поэтому использовал получить без удаления, хотя мог использовать и с удалением. Выигрыш конечно микро секунды, но все же.
Думаю могут быть ситуации, когда это будет полезно.
Хорошая статья. Твою бы статью, да когда я LRU кэш организовывал…
Получилась очень сложная конструкция из таблицы значение, соответствия и пары параметров. Зато без проблем кэширую http запросы с контролем памяти.
(28) Спасибо. LRU это круто.
priority queue — моя любимая структура данных по изяществу и эффективности.
К сожалению, в 1С возможно реализовать лишь модели такого рода структур. Вся прелесть эффективности их реализации недоступна в 1С.
(31) Вначале статьи я указал, что буду использовать готовые типы данных 1с. Как бы намекая на то, что не буду пытаться реализовывать кучи для приоритетной очереди :). Хотя мне очень интересно посмотреть реализацию «по классике» в 1с.
(32) На массиве делается вполне аутентично. Но вот эффективность может хромать вследствие тормознутости 1С как скриптового языка (вполне может оказаться, что использование библиотечной сортировки на больших коллекциях более эффективно, чем «ручные» операции на массиве, несмотря на O(log N)).
(32) Вот тут глянь в самом начале:
Там все очень просто и красиво.
(34) Спасибо
Ну спасибо! Теперь вопросы на собеседования новые выдумывать 🙁
(20) ссылку на последний можно хранить в первом.
Если эта куча то вообще ни чего этого не нужно
(22) Лучше ни каких проверок не делать. Пусть возникает исключение, а программист должен сам его обрабатывать на своё усмотрение. Тогда получиться так:
Показать
(40)
Кому лучше?
Тем более, мы рассматриваем ситуацию, когда Неопределено может быть значением. У вас, по-моему, другая ситуация описывается.
(40) Я уже убрал в статье какие либо проверки. В данном случае считается, что программист сам решает как ему обработать исключение, либо вообще не допустит такой ситуации. Есть функция Пустой()
(36) Огромное спасибо за реализацию. Одно дело понимать теорию, а другое реализовать, да еще и в 1с 🙂
(43) Не за что. Самому было интересно 🙂 Я практически один к одному передрал ключевые моменты принстонской реализации из их книжки по алгоритмам.
(46)
>»Всплытие» и «погружение» элементов происходит именно «по дереву», между дочерними и родительскими элементами.
Ну что ж, попробую разобраться повнимательнее — в механизме отображения дерева на массив… возможно, будет интересно. А то когда я вижу в коде Цел(ИндексЭлемента/2), я вижу обычное половинное деление, даже если назвать переменную ИндексРодительскогоЭлемента 🙂 в дереве всё же наполнение веток может быть сильно неравномерным, да и связи где-то должны храниться (или хотя бы неизменно определяться). А тут мы всё время середину интервала берём.
Но мой код всё равно короче и в общем быстрее 🙂
(47) Здесь не середина интервала берется. Здесь вычисляется адрес дочерних/родительских элементов умножением/делением на 2. Проще всего разобраться с бумажкой и ручкой. 1 2 3 — 2 и 3 это листья 1. 1 2 3 4 5 6 7 — 4 и 5 — это листья 2, а 6 и 7 — это листья у 3 и так далее.
Нашли чем хвастаться 🙂 А если использовать встроенную сортировку списка значений, то может получиться еще быстрее чем половинным делением на определенном размере очереди.
1С — это тормознутый скриптовый язык без низкоуровневых примитивов. Оптимизация на нем как правило упирается не в знание базовых алгоритмов, а в эффективное использование библиотечного функционала.
Даже массив в 1С — это достаточно высокоуровневая динамическая структура данных под капотом. Оригинальный алгоритм priority queue строится поверх неизменяемых массивов (фактически просто непрерывных кусков памяти) и оптимизирован под минимальное количество перестановок и копирований. Реализовывать ее с помощью динамического массива — это уже смешно. Эти алгоритмы и структуры данных как раз и составляют «потроха» реализации библиотечной функциональности высокоуровневых языков.
(45) в пункте 4 «Массив и двоичное дерево» можете более детально посмотреть как на массиве отобразить двоичное дерево
Зачем вот это вот всё ? А если на С написать тоже подобное или С++ с шаблонами STL, где всё это уже реализовано и позасекать время?
(3)
это легче проверить по количеству символов — четность для кавычек, равенство для скобок
(51) ((([(((([)))))
(51) В приведенном примере количество скобок четное , но для [ нет закрывающей скобки , так что по количеству не проверишь
(53) странный пример
((([(((([)))))
((((((( 7
[[ 2
))))) 5
7 <> 5 для ()
2 <> 0 для []
т.е. по количеству проверяется элементарно
Другое дело, что со строкой типа ([)] есть некоторые проблемы. Но все то же самое — считаем количество квадратных скобок между круглых скобок — получаем не сходимость.
(54) Со стеком проще гораздо , просто если будут [({)]} т.е. 3 вида скобок как тогда измениться ваш способ ? А при стеке — изменения минимальный. Поэтому стек в данном случае удобнее
(54) Со стеком это решается так — кладем в стек только открывающие скобки, а когда встречается закрывающая, то берем из стека и смотрим соответствие вида скобки.
Вконце стек должен быть пустым, т.е. в стеке не должно остаться открывающих скобок. Так же, если встречается закрывающая скобка, а стек пустой, то тоже ошибка.
Мне кажется здесь проще и надежнее использовать стек, нежели подсчет скобок.
(56)а кавычки? Когда класть и забирать?
Я решал задачу разбора файлов 1С с фигурными скобками и кавычками — решение получилось без стека.
Т.о. практического применения описанных механизмов не понимаю, хотя и не отрицаю возможность применения.
Но как я уже говорил — это частные задачи и они требуют индивидуального подхода.
(55) я задачу разбора такой строки решал бы рекурсией
(57) Если есть открывающая и закрывающая («»), то можно также. А можно с помощью состояний или флага.
Мне больше нравится состояние, получится конечный автомат. Встретилась кавычка — кладем ее в стек и переходим в состояние, например ЦИТАТА. Когда в этом состоянии еще раз встретилась кавычка — берем из стека и переходим в прежнее состояние. В состоянии ЦИТАТА можно, например, не считать скобки, все зависит от поставленной задачи.
(58) Кстати, использование стека — это один из способов избавления от рекурсии :).
(61) Ну это как посмотреть. Я считаю, что первый добавленный элемент кладется на «дно», следующий на него. Если по другому представить массив, то у него есть голова и хвост, я считаю, что новый элемент увеличивает хвост, вы же считаете, что новый элемент увеличивает голову. А слово «вставка» пусть не вводит вас в заблуждение.
(5) вот здесь примеры практического применение этого кода (очередь и приоритетная очередь)