
Вначале изложу немного теории относительно вычисления логических выражений. То, что будет написано в первом разделе, есть в любом самоучителе по любому современному языку программирования. И если вам покажется, что я описываю “элементарные вещи, которые и так все знают”, то можете смело пропустить первый раздел.
Любое выражение, написанное в коде вычисляется слева направо и согласно приоритету операторов. При вычислении логических выражений приоритет операторов следующий (в порядке убывания):
-
Операции сравнения (=, >, <, <>)
-
НЕ
-
И
-
ИЛИ
Три логических оператора: НЕ И ИЛИ для удобства понимания можно представить как арифметические: унарный минус, умножить, плюс (соответственно). Например, если мы хотим посчитать сумму покупок: 5 яблок по 12 рублей, 3 килограмма гречки по 50 рублей, 2 рулона туалетной бумаги по 25 рублей — запишем в калькулятор все это одной строкой в естественном порядке и без всяких скобок: 5 * 12 + 3 * 50 + 2 * 25. Ведь еще в школе нас научили, что сначала множим, потом плюсуем. Так и здесь мы сначала получим сумму каждой позиции, а затем общую сумму.
Аналогично работает приоритет в логическом выражении. Сначала будут вычислены все И, затем все ИЛИ. Раньше всех применится НЕ, оно инвертирует результат выражения справа от себя, аналогично унарному минусу: -5 — это как 5 только в другую сторону от нуля).
Операторы И и ИЛИ являются бинарными, то есть сравнивают 2 выражения слева и справа от себя и возвращают результат сравнения: Истина или Ложь. Цепочка операторов обрабатывается слева направо. При этом работает сокращенный цикл вычисления логических выражений. Такую фишку добавили в платформе 1с 8. В учебнике по javascript я вычитал замечательную аллегорию на этот механизм:
"Оператор И спотыкается на лжи, а оператор ИЛИ спотыкается на правде”.
Иными словами, когда у нас цепочка из нескольких И, то они будут вычисляться до тех пор пока следующее И не вернет ложь. Все И, что правее от этого выражения вычисляться не будут. С другой стороны, когда у нас цепочка из нескольких ИЛИ, они будут вычисляться до первой истины. Платформа справедливо считает, что если в куче И мы наткнулись на ложь, то все выражение ложное и незачем тратить ресурсы на его вычисление. Эту особенность мы можем использовать для наших нужд.
А теперь практический пример.
Рассмотрим задачу загрузки элемента справочника “Номенклатура” из внешнего источника. Алгоритм действия примерно такой:
-
Создать карточку номенклатуры
-
Создать единицы измерения
-
Записать базовую единицу измерения в карточку номенклатуры
-
Загрузить штрихкоды номенклатуры
-
Загрузить цены номенклатуры.
Простой линейный алгоритм. При этом выполняться он должен именно в этой последовательности. И кроме того должен прерываться, если очередной этап выдал сбой. При этом желательно в конце вернуть общий результат выполнения операции. Мы можем оформить каждый этап в отдельную функцию, которая в зависимости от успешности возвращает Истину или Ложь, а затем написать следующий код:
Если НЕ СоздатьКарточкуНоменклатуры() Тогда
Возврат Ложь;
КонецЕсли;
Если НЕ СоздатьЕдиницыИзмерения() Тогда
Возврат Ложь;
КонецЕсли;
Если НЕ ЗаписатьБазовуюЕдиницу() Тогда
Возврат Ложь;
КонецЕсли;
Если НЕ ЗагрузитьШтрихкоды() Тогда
Возврат Ложь;
КонецЕсли;
Если НЕ ЗагрузитьЦены() Тогда
Возврат Ложь;
КонецЕсли;
Возврат Истина;
Вроде получилось наглядно и понятно. Но смущает часто повторяющиеся блоки Если Тогда КонецЕсли. Теперь вспомним теорию: как себя ведет цепочка И при вычислении, и перепишем код следующим образом:
Возврат СоздатьКарточкуНоменклатуры()
И СоздатьЕдиницыИзмерения()
И ЗаписатьБазовуюЕдиницуИзмерения()
И ЗагрузитьШтрикоды()
И ЗагрузитьЦены();
Код получился значительно короче, при этом сохранил прежний функционал. Выполнение будет происходить в том же порядке и прервется на той функции, которая вернет Ложь.
Теперь немного усложним задачу. У нас есть разная номенклатура с характеристиками и без, весовая и штучная. Для номенклатуры с характеристиками надо загружать характеристики номенклатуры, для весовой — коды весового товара. В этом случае мы из внешнего источника получаем булевы признаки: ИспользуютсяХарактеристики и ВесовойТовар. Теперь самая длинная цепочка алгоритма должна выглядеть так:
-
Создать карточку номенклатуры
-
Создать единицы измерения
-
Записать базовую единицу измерения
-
Создать характеристики
-
Загрузить коды весового товара
-
Загрузить штрикоды
-
Загрузить цены
Алгоритм перестал быть линейным. Набор операций теперь зависит от флагов: ИспользуютсяХарактеристики и ВесовойТовар. Попробуем записать этот алгоритм в одну строчку:
Возврат СоздатьКатрочкуНоменклатуры()
И СоздатьЕдиницыИзмерения()
И ЗаписатьБазовуюЕдиницуИзмерения()
И (НЕ ИспользуютяХарактеристики ИЛИ СоздатьХарактеристики())
И (НЕ ВесовойТовар ИЛИ ЗагрузитьКодыВесовогоТовара())
И ЗагрузитьШтрихкоды()
И ЗагрузитьЦены();
Для замены конструкции:
Если ИспользуютсяХарактеристики Тогда
Если НЕ СоздатьХарактеристики() Тогда
Возврат Ложь;
КонецЕсли;
КонецЕсли;
Мы использовали конструкцию с ИЛИ. Поскольку мы помним, что ИЛИ запинается на правде, значение флага инвертировали с помощью НЕ. Такое выражение остановится на вычислении значения флага, если он не установлен либо пройдет дальше и вычислит правое выражение и создаст характеристики для товара. Поскольку приоритет ИЛИ ниже, чем И, то эту конструкцию мы заключили в скобки.
Чтобы избавиться от круглых скобок, можно перевернуть все выражение и заменить И на ИЛИ так чтобы вложенные выражения содержали конструкцию И и выполнялись согласно приоритету первыми:
Результат = НЕ СоздатьКарточкуНоменклатуры()
ИЛИ НЕ СоздатьЕдиницыИзмерения()
ИЛИ НЕ ЗаписатьБазовуюЕдиницуИзмерения()
ИЛИ ИспользуютсяХарактеристики
И НЕ СоздатьХарактеристики()
ИЛИ ВесовойТовар
И НЕ ЗагрузитьКодыВесовогоТовара()
ИЛИ НЕ ЗагрузитьШтрихкоды()
ИЛИ НЕ ЗагрузитьЦены();
Возврат НЕ Результат;
Поскольку ИЛИ запинается на правде, то для сохранения функционала мы инвертировали каждый вызов операции. Вложенное условие с конструкцией И выполняется в первую очередь, поэтому круглые скобки уже не нужны. Поскольку И запинается на Лжи, то при снятом флаге ИспользуютсяХарактеристики выражение НЕ СоздатьХарактеристики() вычисляться не будет, и соответственно характеристики не создадутся. В таком виде вложенное выражение читается естественнее. Все полученное выражение возвращает Ложь в случае успешного выполнения всех операций, поэтому значение результата в конце инвертируется. Кстати дополнительный отступ перед И визуально отделяет вложенное условие, что в условии отсутствия круглых скобок облегчает анализ кода.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Логика мужская, с начесом.Я верю что когда нибудь такой код станет стандартом и войдет в бсп и все типовые конфигурации.
Не стоит превращать весь код и особенно логику верхнего уровня в большие логические выражения, состоящие из вызовов многих прикладных функций. Ведь
— точки останова будут работать только в первой строке каждого такого выражения
— пошаговая отладка по вызовам прикладных функций в одном выражении требует некоторой сноровки
— в платформе есть проблемы с некорректным разнесением замеров производительности по строкам многострочных выражений.
Поэтому такая красота будет совсем не бесплатной.
Лучше не использовать такие методы. Вы закладываете в логику кода особенности реализации ленивых вычислений. А если они изменятся? А если какая-нибудь 1С9 таки начнёт использовать многозадачность и последовательность выполнения станет неопределенной?
Не вижу смысла.
(3) Справедливое замечание. Я даже переспросил у Гугла, чтоб не облажаться с ответом. Логика ленивых вычислений присутствует не только у 1С, точно так же вычисляются выражения && и || в Джава и Джаваскрипт. Не проверял, но скорее всего у других языков тоже такое есть. Похоже, что это уже стандарт и предпосылок к его изменению я не вижу.
Насчет многопоточности. Я думаю, что если в новой платформе включат многопоточность, то это в коде должно как-то по особенному отражаться. Либо какой-то особый признак у модуля, либо особые директивы препроцессора типа &НаКлиентеАсинхронный. Если предположить что в новой платформе код будет выполняться не последовательно, а все функции будут закидываться в стек, а выполняться по принципу кто успел, тот и съел, то не только мой код сломается. Мне кажется в таких условиях любой код на 1С перестанет работать.
(2) Спасибо. Возьму на заметку. Такой стиль я подсмотрел в проекте, который достался нашей фирме по наследству. И только недавно реализовал в своей обработке. Поэтому особо отлаживать его еще не приходилось. Мне в первую очередь понравилось как это выглядит, и как читается.
Так то все конечно выглядит красиво, но в данном примере функции СоздатьКатрочкуНоменклатуры() и СоздатьЕдиницыИзмерения() — должны возвращать ссылку на созданный элемент справочника. Эти две ссылки должны бы передаваться в метод ЗаписатьБазовуюЕдиницуИзмерения().
Иначе придется использовать глобальные переменные. А это не рекомендуется п 3.2
Я к тому, что идея выглядит красиво, но на практике ровно в таком виде — применить получится крайне редко.
Почти всегда придется искать компромиссы.
А вот тема таких компромиссов в публикации не раскрыта
(7) Вы забываете про параметры функций. В данном конкретном примере я бы рекомендовал что-то подобное:
У меня в обработке вместо структуры была строка табличной части, но это не меняет сути. В структуру мы можем записывать любые данные, которые потребуются следущим функциям для работы. А в самих функциях можно проверять наличие значения через метод Свойство(«Ключ», Значение).
(8) Спасибо. Где то писали что в современных языках программирования все параметры функций легко превращаются в одну единственную структуру.
Это следующий уровень абстракции.
(8) ну это конечно снова компромисс, т.к. мы теперь не видим какие ключи должны быть в структуре, в каких методах эти ключи назначаются, а в каких методах используются.
Нужно будет провалиться в каждый метод, чтобы это понять. Если наши проверочные функции не совсем примитивные, то нужно будет потратить время, чтобы разобраться в таком спагети.
Также, мы не сможем просто так взять и отключить любую проверку, т.к. в ней могут рассчитываться переменные для следующих проверок
Еще мы не сможем переставить проверки местами без анализа их самих. А это совсем не очевидно.
Но в принципе, я не критикую. На самом деле у такого подхода есть плюсы и минусы. И каждый их оценивает в соответствии со своим опытом.
Существует несколько аспектов хорошего кода.
Но самый главный из них — его читаемость.
Хороший код пишется один раз, а читается много раз.
И дело не в комментариях к каждой функции, а в самом коде. Читая его, у тебя не должно возникать вопросов «А это откуда, а это куда, а там что происходит, а это зачем?».
Подобные конструкции не улучшают понимание происходящего, а только уменьшают на N количество строк.
С тем же успехом можно писать
И желаемая «лаконичность» будет достигнута.
Ну а эти сложные конструкции из функций, связанных в ИИЛИНЕ — ладно если у тебя там именно проверки, типа
Их еще можно понять сходу.
Так нет же, ты предлагаешь таки образом оформлять процедурный код с отслеживанием результатов его выполнения.
Вот тебе еще пример
Первый вариант ты прочитаешь как абзац книги и даже не задумаешься.
Второй — ты будешь, пускай и несколько секунд, но осмысливать. Изречение Йоды мастера как.
(11) Мне вот так читается как абзац книги:
Согласен, не совсем удачный пример.
Для меня тоже как абзац. Сейчас.
Я думал, будет очевидно, что речь не про a и b, а в том, что a=?(b<=0,None,’asdasd’) предлагают писать как
Проблема в том, что не нужно изображать какую-то изысканную акробатику там, где это не принесет ничего, кроме эстетики.
Да, тебе будет приятно, что ты такой умный и написал код «вот так изощренно». Пройдет пару лет и твой код откроет кто-то другой. И не поймет, что ты пытался этим сказать, зачем выпендривался, к чему эти условности и абстракции.
Не говоря уже о том, что если ты делаешь что-то посерьезнее печатных форм и линейных обработок, тебе нужно возвращаться к своему коду снова и снова, и читать его снова и снова. Дебаггинг таких конструкций будет просто невыносим. И каждый раз, натыкаясь на них, ты будешь еще и время тратить вспоминая или осознавая, что же тут так красиво зашифровано в этих перипетиях логической пляски.
я бы попросил не писать много этажных конструкций если а использовать явное указание на «прекращение» вычисдения
Вместо
цикл Услвоие
если чтото1 Тогда
если чтото2 Тогда
//тут много кода длинного и хз что там в конце как делается
пишите покороче.
цикл Услвоие
Если НЕ чтото1 Тогда Продолжить; КонецЕсли;
Если НЕ чтото2 Тогда Продолжить; КонецЕсли;
//тут линейный код который не зависит от условий
(14) прикольно, я тоже этот совет многим начинающим даю… 🙂
еще такой, например:
Если чтото Тогда
//мало строчек кода
Иначе
//много строчек кода
КонецЕсли;
потому, что когда наоборот, то наглядность логики падает…
а в своём языке программирования, который я сейчас делаю, я придумал операторы
Цикл
ПрерватьЕсли что-то;
ПродолжитьЕсли что-то;
КонецЦикла;
мне кажется красивые операторы 🙂
Код пишется для человека, а не для машины.
К чему такой рефакторинг «лишь бы без скобок»?
Я лучше отдельными блоками напишу код, тогда мне хватит одной секунды понять как тут все работает.
Проблемы с подобным у вас начнутся, когда например возникнет ошибка в параметрах передаваемых в последнюю функцию
По самым скромным прикидкам потребуется в два три раза больше времени, чем на отладку обычного кода
Вариант №1
Вариант №2
Показать
первый вариант достаточно легко читается, во втором 9 человек из 10 сходу не сможет сказать что будет результатом на выходе функции
в среднем логическое отрицание (НЕ) значительно усложняет простоту восприятия логических выражений
Я, конечно, дико извиняю, но имена функций, возвращающих булево, просто жесть.
Вот, пожалуй, оставлю это здесь.
Автор поднял обсуждение проблематики, молодец!
Но если спросить любого квалифицированного много лет программирующего ПРАКТИКА, а не Теоретика Кода, то лучше писать многоуровневые условия, как в (14). Это будет «научно неправильно», но 1000% удобно для поддержки.
Код должен быть а) понятен даже новичку б) легко модифицируем в) легко отлаживаем
А подход, предлагаемый в статье, описывает некоего «сферического коня в вакууме», просто как идею. Автор, поверь, через некоторое время ты вернешься к тому, от чего пытался уйти, но за попытку разобраться ставлю +
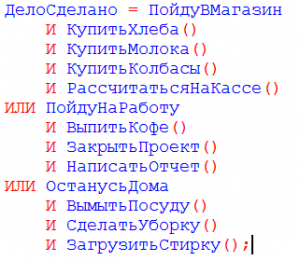
Пришел к мнению различных веяний, что легко читаемый код будет для меня такой:
Показать
Первый плюс кода выше, использовать методику , суть которую уловил: начинать выражения И со строки ИСТИНА и каждое новое сравнение с новой строки, а выражения ИЛИ со строки ЛОЖЬ. Это позволяет каждую строчку закомментировать если в ней отпала необходимость или написать комментарий напротив.
Второй плюс это замечание коллеги (, который давно сказал, что читабельнее именно сравнение со значением а не просто «НЕ СоздатьКарточкуНоменклатуры()». Я с ним полностью согласен. Стал замечать, что мозг реально перестает меньше напрягаться при чтение таких выражений, когда явно написано ЛОЖЬ или ИСТИНА после знака равно.
А про красоту кода, ну она должна быть в меру. Иногда перегибают палку как Дмитрий Малюгин — когда за два пробела удар по яйцам :))) Всего должно быть в меру.
(19) А что жесть то?
Наименования соответствует пункту 6.5 приведенного вами же стандарта.
А про возврат булево в стандарте ни слова нет.
Да и как бы разрабы БСП иногда используют такой же прием, только в умеренных дозах, тут перебор офк, замучаешься дебажить такие цепочки.
(21) Тоже заметил, что условные выражения читаются легче с » = Ложь», чем с «НЕ», как ни парадоксально.
«Оператор И спотыкается на лжи, а оператор ИЛИ спотыкается на правде”. — Только за это плюс
(5) Многопоточность уже включена, просто не все об этом знают и помнят 🙂
(22) 6.5 подразумевает действие над объектом или формой, возвращая при этом успех операции, а в аргументе само значение. Как в примере — действия над формой и, в случае неудачи, ввернуть ложь.
В конкретно данном случае логичнее и читабельнее было бы использовать флаг отказа в аргументах функции.
В Вашем примере что должна сделать функция СоздатьКарточкуНоменклатуры()? Создать элемент справочника? А может в функции проверяется необходимость создания и в результате передать управляющий флаг на создание номенклатуры?
Например, неправильно:
Функция ВыполнитьПроверку(Параметр1, Рекв, ТЗ)
Функция ПолучитьМассивыРеквизитов(ХозяйственнаяОперация, МассивВсехРеквизитов, МассивРеквизитовОперации)
Правильно:
Функция РеквизитОбъектаЗаданногоТипа(Объект, ИмяРеквизита, ТипЗначения)
Функция ЗаполнитьИменаРеквизитовПоХозяйственнойОперации(ХозяйственнаяОперация, ИменаВсеРеквизиты, ИменаРеквизитыОперации)
Вакансия программиста 1С Киев 50 тыс грн
(23) А как вы читаете «Если НЕ Корректировка.Пустая() Тогда»? Пишете «ЗначениеЗаполнено()», что не одно и то же?
Я прекрасно читаю конструкции с «НЕ» и меня коробит от конструкций «Если ЭтоОшибка() = Ложь Тогда».
ps: начинал с asm’а, возможно, поэтому так.
Логические выражения более 3 х операндов — в функцию.
Это будет красивый и поддерживаемый код.
Те простыни что в статье, в том числе и результат — не красивый код.
Результат = НЕ СделатьЧтоТО();
Возврат НЕ Результат;
Функция СделатьЧтоТО()
Здесь линейные булевы вычисления
КонецФункции
(15) а чем не угодил цикл < Пока [Условие] Цикл >?
(26) Кстати да, Вы чертовски правы!
(30) обычный цикл Пока тоже есть… я в данном случае писал про операторы
ПрерватьЕсли что-то;
ПродолжитьЕсли что-то;
иногда приходится писать бесконечный цикл вида:
Пока Истина Цикл
для таких случаев я предусмотрел просто Цикл
(28)
В платформе есть метод(возможно несколько) которые исходя из названия должны возвращать булево, но при этом метод может возвращать как булево, так и ссылку.
Как то попался на этом….
(28)
То же начинал с Асма вот не увидел связи….
(28) Посыл вашего комментария понял, но не сами предложения.
Я, как и вы, привык не использовать «= Истина/Ложь», — лишь стал замечать, что для быстрого понимания оно лучше. Работаю не один, стараюсь писать без лишней вычурности. На сложных выражениях внутреннего языка или запросов иногда использую Истина/Ложь.
Мне больше вариант с «ЕСЛИ ТОГДА ВОЗВРАТ» нравится — может он и более громоздкий, но его набор легко упрощается шаблонами, а логические выражения (с корнями из функционального программирования) хорошо смотрятся только если они простые — как в данных примерах, но если логика более ветвистая — то нагромождение череды блоков ИЛИ/И может здорово всё запутать и усложнить дальнейшее редактирование этой логики.
Поэтому если в логике есть вперемешку И/ИЛИ и таких условий более 4-5, или условия состоят не только хз вызова проверочных функций, но и содержат сами проверочные выражения, то я однозначно за «ЕСЛИ ТОГДА ВОЗВРАТ». Да и отлаживать их удобнее.
Да, анпример, в других я зыках, имеющих поддержку функционального программирвования — логические блоки куда более красиво выстраиваются, чем в 1С -где большая часть красоты просто недоступна. Хотя бы потому-что тут, хотя бы, анонимных функций и/или произвольные блоки алгоритмов не являются выражениями.
Использование проверок через блоки «ЕСЛИ ТОГДА ВОЗВРАТ» в начале функции тяготеет к парадигме контрактного программирования. Когда все проверочные условия выделяются определёнными (обычно, но не всегда) синтаксическими конструкциями — и каждый контракт обрабатывается отдельно (обычно ещё до вызова функции с контрактами) — вот были бы контракты в 1С — было бы куда красивее.
Или наоборот — был бы в 1С продвинутый паттерн-мэтчинг с условиями — тоже можно было бы красиво писать проверки.
И вообще — лично я за более декларативное написание кода алгоритмов — применение «ЕСЛИ ТОГДА ВОЗВРАТ» как раз более декларативное.
Ну а параллельность…. выполнения инструкций в 1С — это вообще сказки и мечты о несбыточном! Другое дело — что при проверки условий как раз параллельность может быть боком — т.к. часто последующие условия могут операться на уже пройденную проверку предыдущих условий, или быть более затратными по времени выполнения, чем предыдущие, которые чаще отфильтровывают дальнейшее выполнение (и, соответственно, затратную проверку).
Тут много нюансов….
(25)Если Вы про фоновые задания — то это совсем другое дело…
Вдруг обнаружил ещё такой нюанс. Выделять в отдельную процедуру или функцию код стоит тогда, когда он используется более одного раза. В примере из статьи обсуждается целостный процесс, который делится на последовательно выполняемые этапы, но нет задачи, чтобы этапы могли вызываться произвольно. Поэтому я бы оставил это в одной процедуре, разбив комментариями её части.
(37) Я тоже раньше так думал. Если код не будет выполняться более 1 раза, то оформлять его как отдельную процедуру функцию не надо. Но потом в одной записи курса по java-core услышал мнение, что вместо комментария к блоку операторов лучше этот блок вынести в отдельную процедуру, а саму процедуру обозвать говорящим именем. Тогда и код читается легче, и комментарии не нужны. И нет громоздких процедур на много строк.
Попробовал для себя и понял, что это удобно. Запись кода получается короче. Расстояния между блоками Тогда и Иначе влезают в 1 экран и сразу видно, что будет если Тогда и когда Иначе. Плюсом на будущее такой код легче редактируется и развивается. Из готовых мелких операций потом легче собирать новые алгоритмы обработки.
(17) не слишком-то и вырастут затраты времени на отладку…
— устанавливаем точку останова на Возврат
— нажимаем F10 — мы выполнили первую функцию, если мы стоим на второй, то с первой все в порядке, а если сразу вышли, значит функция вернула Ложь и в ней ошибка…
… повторяем для всех функций…
для последней функции анализируем возвращенное значение…
узнав функцию в которой ошибка, ставим точку останова в ней (или заходим по F11) и отлаживаем… времени надо совсем чуть-чуть больше, чем на обычный код…
(38) у такого подхода тоже есть минусы… я, например, очень не люблю перемещаться туда-обратно между кучей мелких процедур, когда ищу где-же делается то, что мне надо найти…
гораздо приятней просто крутить длинную процедуру до конца…
«говорящее» имя может оказаться только для вас говорящим… а для читающего ваш код впервые оно может только приблизительно намекать на то, что там внутри…
А ещё, когда в модуле только большие процедуры, то открывая список процедур быстро понимаешь, как устроен модуль… а если там десятки процедур с самыми разнообразными названиями, то уже трудно понять с чего начать, какие процедуры и функции важные, а какие просто обслуга… да и с точки зрения производительности вызов процедур не бесплатный, особенно в циклах и в рекурсии…
так что надо творчески подходить, где-то разбивать код на мелкие процедуры, а где-то и нет…
(36) А как Вы себе представляете «истинную» много поточность в 1С. Давайте там ещё и «классическое» ООП поищем 🙂
Как смогли так и реализовали. Исполнение параллельных вычислений есть — есть. Семафоры есть — есть. Ну а дальше «не шмогла» 🙂
ИМХО, всю концепцию 1С не плохо бы перетрясти. А то кусок «правого» похода, кусок «левого», и ещё до кучи пара-тройка технологий » авось кто придумает как использовать» 🙂
ЗЫ: Сейчас перечитал, и понял насколько у меня был узок и зашорен подход к программированию, когда я писал на C и Prolog 🙂
(41)В том то всё и дело — что я никак не представляю многопоточность в классическом 1С 🙁
И согласен с тем, что всю концепцию языка (и платформы) 1С надо перетрясти. Но, не уверен, что на это хоть когда-нибудь пойдут братья Нуралиевы. Но они не вечны (как и мы) — возможно на анонсирование принципиально иного 1С Предприятия 9 решится тот, кто придёт после них… но, как говорится, не в этой жизни 🙁
Но ведь это Вы написали «Многопоточность уже включена» — а её реально-то и нет.
А непосредственно, в рамках данной концепции — многопоточность подразумевалась такая — что код алгоритма пишется линейно — а платформа сама решает как его можно распараллелить и вообще — нужно ли это делать. Сама определяет части кода, которые можно выполнить независимо от других и какие части будут зависеть от выполнения других, чтобы сначала дождаться их выполнения. Конечно, программист тут может давать платформе «подсказки» и задавать ограничения такого распрараллеливания.
Такое возможно — если язык программирование будет гораздо более декларативным, чем сейчас — т.е. он будет говорить — что надо сделать (и при каких условиях), а не детально описывать — как это надо сделать, задавая чёткую и избыточную последовательность инструкций (подразумевается что — это другой уровень алгоритмов — нижестоящий, где описываются алгоритмы с высоким уровнем абстракции и универсальности и с применением кодогенерации, а верхний уровень, пройдя через аналитическое горнило платформы, обращается к нижнему ежё определившись как он его будет использовать).
Более того — при таком подходе часть вычислений и проверок вообще, по-возможности, нужно выносить за рамки runtime — выполняя их ещё в конфигураторе, на стадии первичной компиляции (и проверки конфигурации).
(42) мне бы, например, на первых порах, хватило бы что-то типа ЗапуститьПараллельно(х) и ОжидатьИсполнения(х) без запуска фонового задания
(40)
По сути, это лишь проблема IDE 1С «Конфигуратор» — которая не умеет эффективно просматривать вызываемые функции, вроде как в EDT сейчас это потихоньку оптимизируют.
Обычно в таких больших процедурах очень быстро можно потерять суть в них происходящего и запуаться вблоках ветвления и циклов
Ну это уже претензии к тому кто как называл процедуру — если придерживаться мировых рекомендаций — то обычно больших проблем с пониманием не бывает — тем более, когда IDE умеет показывать быстрые подсказки к процедуре (при наведении на неё мышь) из заголовка комментария этих процедур.
Опять-таки — это скорее претензии к IDE и к плохо организованной структуре кода — плохое разбиение на модули и области. Ну и без ООП — в чисто процедурном языке действительно очень-очень много может накапливаться плохо упорядоченных процедур.
Это претензии к платформе — что она не умеет оптимизировать вызовы мелких процедур в циклах (автоинлайн) и рекурсию (разворачивание в циклы)
Замечу обратное, важное для 1С — что если бы типовая конфигурация была более мелко разбита на процедуры — то её обновлять было бы гораздо проще.
Но это справедливо и для рефакторинга своего/чужого программного кода.
А будь в 1С ООП — так разбиение на процедуры ещё и повысило бы эффективность применения полиморфизма.
(43) что мешает сделать это в бсп?
(43)Даёшь корутины в 1С!
Вообще — для начала дали бы возможность писать свои собственные асинхронные методы — а то встроенные есть — хочется и свои, и чтобы можно было их и в серверном контексте использовать. Но… как мне кажется — это не техническое, а чисто идеологическое и коммерческое ограничение — так что не будет этого в 1С. По крайней мере, до 9-й платформы, а там уже можно будет кардинально лицензионную политику пересмотреть и цены на разные версии платформы по-разному привлекательно обосновать. Только 9-ку я бы вообще в обозримом будущем не ждал бы. в лучшем случае — к середине века…
(45)То, что платформа не поддерживает параллеьность для пользовательского кода. ФоновыеЗадания не в счёт — это отдельные процессы, а не простые потоки — с кучей своих недостатков, ограничений и издержек, да ещё и доступные только для серверного контекста.
(47) а что вы понимаете под клиентским контекстом и как представляете себе параллельность в нем? Особенно в режиме терминала и десятке веб браузеров..
Представим себе на минуту, что в обсуждаемом логическом выражении платформа будет вычислять каждый результат в отдельном потоке на разных ядрах процессора.
То, что они вычисляются в 8 ке последовательно и вычисление прерываются при бессмысленности продолжения это допущение платформы 8, оптимизирующее ее же ограничения.
Я бы не стала строить на этом костыле работу такого количества людей.
(40) Если бы любой код выполнялся линейно, то конечно приятнее просто листать сверху внизу и читать как книгу. Так можно залипнуть, и рабочий день кончился) Но почти всегда при анализе кода приходится скакать как сумасшедший в разные места и в разные модули. Сначала ищешь точку входа: ПриОткрытии(), ПередОткрытием(), обработчик кнопки Выполнить(), а потом ходишь по вложенным вызовам через F12, не забывая при этом ставить закладки в коде (F2), чтобы вернуться в то место откуда перепрыгнул.
Уже давно воспринимаю программный код не как свиток текста, а как древовидную структуру. И если код хороший, то от этого дерева можно «отрезать ветку» и использовать в другом месте практически без допиливания. Захотел, перенес часть функционала в модуль объекта и можно обработку подключить как фоновое задание. Захотел, вынес кусок в общий модуль — и твой код используется другими объектами. С большими процедурами, которые выполняют кучу операций, которые надо сделать здесь и сейчас именно так, все что написано выше практически невозможно. Это как будто на то дерево надели чехол и ты его можешь использовать либо целиком, либо никак.
(48) Разумеется сервер имеется ввиду. «Десяток веб-браузеров» тоже можно покритиковать, но это отдельная тема. Смысл вот в чём — главная задержка это почти всегда запрос. Пока он исполняется много чего можно было бы сделать 😉 Фоновое задание — это ядерная бомба, бомбить ей воробъёв чтота как-то некошерно. нет ?
Опять же коллега вам абсолютно правильно указал — потеря контекста — это очень большая потеря 😉
(46) Техническое, думаю. Когда, в своё время, вышла первая FastReport с мултисредингом, то, помучавшись полгодика, вернули её назад в синхорон… Следующая попытка случилась только через пару лет ;)) А тут, имхо, основной момент, как я выше уже написал, — заполнить паузы при ожидании запросов. А это, как минимум, переделка обмена с SQL, а их — 3 модели + файловая и всё в этом тонет… 🙁
(51)Добавление параллельности в платформу — дело сложное. Но такова тенденция XXI века в IT технологиях — и сейчас постоянно появляются всё новые и новые идеи как эту параллельность сделать наиболее простой для программиста. Более того, я думаю будущее — за интеллектуальными компиляторами — которые буду сами решать как распараллелить написанный алгоритм (и вообще — нужно ли это делать; вообще интеллектуальные компиляторы будут много чего уметь делать за программиста, а не только оптимизировать алгоритмы).
Но даже сейчас — я не вижу большой сложности добавить в язык 1С возможность делать асинхронные методы. Самое простое — это наложить на них ограничения как на вызов серверного контекста — т.е. на мутабельность передаваемых и возвращаемых значений, ну и можно ограничить доступ к глобальным переменным и параметрам сеанса (вернее — с глоьбальными переменными сделать как с серверным контекстом — существуют только пока идёт асинхронный вызов, а вот доступ к параметрам сеанса сделать с блокировками и синъхронизацией — как это делают в асинхронном программировании).
Всё, иных проблем с доступом к базе не должно быть — ибо СУБД вполне нормально поддерживают параллельную работу (но внутри полатформенного внутреннего контекста кое-что наверняка переписать придётся, особенно если там много статических классов, которые обычно мало пригодны для параллельной работы).
Я всё-таки считаю что асинхронность в программировании нужна не столько для заполнения пауз между длительными операциями, сколько для оптимизации этих длительных операций, когда фоновые задания слишком тяжелы или невозможны — Клиентский контекст. Но, конечно, это, скорее исключение, в первую очередь — это серверный контекст — но, там, кто-то может заметить, что параллельность не нужна — т.к. там и так идёт многопользовательская работа — и процессоры и так постоянно параллельно нагружаются разными клиентскими сеансами-процессами и фоновыми заданиями. Но, всё-таки параллельность к формированию таки алгоритмов позволила бы платформе более эффективно и равномерно распределять нагрузку процессоров, особенно для не постоянно выполняемых но очень тяжёлых операций обработки данных — создающих пиковые нагрузки на один процесс-сеанс.
Офигеть, целая статья про Если Иначе КонецЕсли и куча вскукареков за параллелизм в 1С. Ну такое себе. От себя добавлю, что все написанное в статье уже было у Стива Макконнелла в книжке про совершенный код. Не придумывайте велосипеды.
(48)Я об этом написал — параллельность — это не панацея. Но я за то, чтобы платформа сама решала (при содейситвии программиста) — что ей расспаралелить. Если у неё дефицит мощности — то распалить нет смысла — если избыток — то почему бы не рапараллелить — не понадобятся вычисления — да и фиг с ними — не убудет.
Соглашусь, что распараллеливание в клиентском контексте дело не особо важное — но, порой и тут возникают такие задачи. Опять-таки — тут платформа должна решать — есть ли избыток мощности или нет — чтобы параллелить или вычислять последовательно.
А, вот в серверном контексте, распараллеливание вычислений — дело очень важное.И Фоновые задания тут не панацея — очень тяжёлые они в использовании (затратные по ресурсам). Даже в современных ящыках программирования уже стараются отойти от иидеюю создания параллельных потков (шредов) в пользу других концепций управления ассинхроностью выполнения — вот и возникают асинхронные функции и корутины, где программист не отвечает за создание и управление потоками, а за это отвечает внутренние библиотеки языка — по необходимости, и сами потоки тоже кешируются в пул.
Например параллелить очень эффективно и правильно заполнение и сопоставление таблиц (да и вообзе — обработку любых коллекций и результатов запросов), проведение по регистрам, или формирование сложных отчётов/печатных форм (где есть пред/пост обработка данных), или управление интерфейсом отображения, или разборы текстов.
Да и просто — выполнять какие-то фоновые процессы — с ожиданиями, которые в периоды выполнения алгоритма не должны мешать основному процессу.
Вот, кстати, и главная потребность для клиентского контекста — это необходимость в нём выполнять фоновые процессы, которые, напрямую не связаны основным клиентским контекстом и не должны его тормозить, но периодически они должны выполнять какие-то инструкции (пуская даже с серверными вызовами — где и будет основная нагрузка — но с ожиданием результата) — сейчас это не возможно — ибо такие даже небольшие алгоритмы будут создавать фризы в клиентском контексте — это плохо. Да и банальное открытие форм длокументов или их проведение — тоже не должны, по хорошему, фризить клиентский контекст — т.е. весь процесс должен идти в клиентском фоне (с серверными вызовами и ожиданиями на них, а часть алгоритма — всё-равно выполняется в клиентском контексте).
Так что — параллельность нужна и в серверном и в клиентском контекста — но нужно сделать её максимально удобной для программиста и максимально незаметной для пользователя (вернее как раз заметной — как отсутствие фризов). Вот, ассинхронные функции и фоновые потоки (в рамках текущего сеанса) — были бы очень кстати.
(54) вы имеете ввиду нечто вроде «начатьвыполнениезапроса», процедураобработчикрезультатазапроса?
(44) конфигуратор, конечно, не супер IDE… но я и не писал конкретно про конфигуратор…
я работаю на разных языках и проблемы везде одни и те же, программисты не идеальны, вне зависимости от того, выносят они код в отдельные процедуры или нет…
когда-то, когда еще не были осмеяны и затоптаны операторы GOTO и GOSUB, мы называли код некоторых товарищей взрывом на макаронной фабрике, именно из-за необходимости бегать по этим переходам туда-сюда-обратно, что бы понять написанное… в варианте разбиения на мелкие процедуры многие добиваются такого же взрыва на макаронной фабрике… эти люди просто переоценивают свои способности к декомпозиции и способности давать осмысленные имена… давать осмысленные имена это вообще достойно отдельной дисциплины…
(49)
закладки уже можно не ставить… с некоторых пор в конфигуратор добавили сочетания Ctrl+- и Ctrl+Shift+- позволяющие перемещаться назад и вперед…
однако, прыгать все же утомительно… особенно, когда перепрыгнув, обнаруживаешь там всего пару строчек…
«отрезать ветку» это конечно хорошо, но на самом деле это большая редкость, т.к. эти ветки чаще всего специализируются на задачах, которые больше ни где и никогда не понадобятся…
в синтакс-помощнике 1С описано не так уж много объектов, однако найти программистов помнящих все свойства и методы этих объектов найдется совсем не много, если вообще найдется… разбивая большую процедуру на множество мелких вы дополнительно увеличиваете поле методов, в котором придется ориентироваться программисту… главное не перестараться с этим…
я всего-лишь призываю к разумной достаточности… если вы сами в своей длинной процедуре чувствуете себя уверенно, то скорее всего и другие будут чувствовать то же самое… а если через неделю вы в ней потерялись, перепишите ее…
(27) какие требования? огласите весь список
(38)все должно быть в меру, такой подход используется в документообороте, и очень напрягает бегать отладчиком по 10 модулям с вызовом 100500 функций туда сюда
(56)Ну про снижение дисциплины среди программистов ещё Боб Мартин (автор книги «Чистый код») говорил. Но это уже другой вопрос. В остальном — современная IDE вполне должна оказывать достойную помощь в вопросах быстрого написания, анализа и рефракторный кода. Увы, конфигуратор 1С к таким IDE не относится 🙁
(55)Методологий создания асинхронного кода нынче напридумывано много. Но как вариант — да — как Вы написали — через объект «ОписаниеОповещения», но он, во-первых должен быть доступен в серверном контексте, а во вторых — я за то, чтобы можно было и свои асинхронные функции объявлять.
В своём комментарии (52) я сравнил это с клиент-серверным вызовом. Хотя, лично мне больше нравится синтаксис фоновых заданий — можно использовать и такую модель — когда асинхронный вызов функции возвращает дескриптор вызова и там уже можно проверять статус выполнения, входить в ожидание и получать результат выполнения.
На самом деле — нужно реализовывать обе модели — т.к. они подходят для разных задач.
Ну и асинхронные циклы, хотя бы по коллекциям (и в т.ч. выборкам) — это тоже очень хорошо — но это отдельный паттерн.
красивой может быть баба, а пытаться делать красивым код — это все равно, что мужику красить губы.
ничего личного, просто мысль.
(57) Я пытался донести несколько другую мысль. Как-то я заметил, что во многих задачах используется код, который я когда-то писал. Писал в разное время, используя разные стили, под разные задачи клиентов. И часто приходится рыться в завалах из внешних обработок и искать где та или иная задача реализована максимально удобно и без ошибок, затем копипастить, а затем… дописывать и править. Нельзя было просто вытащить кусок из старой обработки и вставить в новую. Он отчаянно цеплялся за элементы на форме этой обработки, за другие ненужные мне процедуры и функции. И решил, что хватит это терпеть. Потратил день и собрал st-шник из часто используемого кода. Так вот чтобы код не цеплялся за переменные или поля на форме обработки пришлось дробить и добавлять новые функции. Если раньше код для подключения к ФТП содержал в себе ссылки на поля: Адрес, Порт, Логин, Пароль, Папка. То теперь в этом коде добавились функции пустышки ФТП_Адрес(), ФТП_Порт() и т.д. И теперь в этих функциях можно реализовать чтение параметров откуда угодно: хочешь из полей на форме, хочешь из конфигурационного файла, хочешь из сохраненых настроек. Вместо простого Сообщить() в процедурах появилась ВывестиВЛог() и к ней процедура-пустышка ВывестиВЛог(), которая по умолчанию просто вывдит сообщение, но при желании можно вставить из st-шника блок процедур по сохранению логов и заменить функцию-пустышку. Как-то так. Решайте: перебор ли это, или наборот попытка упорядочить наработки.
Если в главбухи снова пойдут мужчины (как до и после революции), уверена, женщины программисты будут заботиться о красоте кода даже спустя десятилетия промышленной эксплуатации.
Ничего личного.
(63) 8ка с ее контрол пробелом как бэ должна была избавить мир от шаблонов, но походу они стали сложнее.
На разработку своих шаблонов надо тратить драгоценное время. И постоянно их модифицировать.
(65) Классическое противоречие тут получается — стоимость поддержки не окупает стоимость новой разработки. Платформа такова.
(66)Есть спрос — есть предложение. Если в поддержку не закладывают стоимость нового значит считают что ничего не надо.
(57) Кстати, спасибо за Ctrl + — и Ctrl + Shift + -. Реально удобно.
(63) то, что вы сейчас описали, старо как мир.. время от времени каждый программист пытается организовать себе свою библиотеку шаблонов… это разумно…
собственно и наследование в ООП, и библиотеки DLL, и разные компонентные технологии, преследуют в первую очередь ту же цель, повторное использование кода… однако, библиотеки сниппетов часто решают эту проблему не хуже, сегодня проблема памяти не стоит так остро, как в 90-е… поэтому копипаст тоже вполне допустим, особенно, если у вас есть возможность быстро находить нужный фрагмент кода…
но выше мы говорили о другом, о том, что разбивать большие процедуры на мелкие не может быть ни самоцелью, ни стандартом…
кстати, в старых книгах, написанных до появления ООП, можно почерпнуть много полезного о структурировании кода… ведь тогда как раз и было модным течением структурное программирование… сегодня структурное программирование это как раз уровень процедуры…
не люблю конструкции вида
Возврат СоздатьКарточкуНоменклатуры()
И СоздатьЕдиницыИзмерения()
И ЗаписатьБазовуюЕдиницуИзмерения()
И ЗагрузитьШтрикоды()
И ЗагрузитьЦены();
Когда я отлаживаю сложные случаи, то не могу на лету изменить возвращаемое значение.
При коде
Результат = ….;
Возврат Результат;
Я могу присвоить любое значение переменной Результат. В последних платформах это типовой механизм, в более ранних с использованием Инструментов разработчика.
Так что. По возможности думайте немного шире нежели исключительно крастоа кода.
(18)Тоже так подумал. НЕ надо избегать.