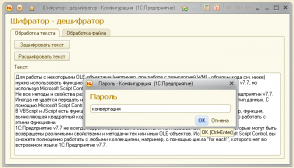



Когда-то придумал для студентов простенький алгоритм кодирования текстовых сообщений, через смещение символов ASCII. Реализовали его они его, как обычно, с частичным успехом, но любая практика им впрок:) А несколько месяцев назад возникла задача зашифровать отдельные элементы справочника для клюшки. Вот тут я и вспомнил про этот метод. Совсем недавно потребовалось обеспечить эксклюзивный доступ к обработке более надежный чем стандартная система паролей. Сделал и это и все через тот же алгоритм…
Ну а сейчас собрал все это вместе под одной, так сказать «крышей», перевел на 8-ку и отправляю в свободное плавание.
Обработки абсолютно равнозначные, по функционалу и используемым алгоритмам кодирования. Изначально все делалось в клюшке, ну, а для расширения и жаждущих перевел очень тупо на 8-ку.
Принцип кодирования заключается в использовании некоего ключевого слова или фразы, через позиции символов которого и смещаются байты исходного текста или файла, в результате получается эдакая приятная на вид кашица (при текстовом просмотре) из самых на первый взгляд неожиданных и несвязанных между собой буковок и прочих значков. Для восстановления этой каши нужно снова ввести ключевое слово и пересчитать все смещения в обратную сторону. Для особо желающих можно регулировать количество проходов кодирования глобальной переменной модуля, увеличение количества проходов, конечно скажется на сложности дешифровки, но и на скорости работы тоже…
Насколько вообще это надежно и как это можно взломать мне оценить трудно, скажу лишь, что я сам не возьмусь взломать бинарный файл кодированный хотя бы в два прохода по ключу не меньше чем из 8 знаков. Жалко тратить жизнь, хотя может быть и очень интересно:)
Термин пароля в обработках на самом деле не точен, это скорее ключ, который перестраивает все содержимое текста или файла, в определенном смысле его подбор сможет восстановить информацию, но его нельзя сбить редактированием файла, как, допустим, это можно сделать со стандартным паролем обработок.
Ограничения по размеру кодируемых файлов где-то в районе 2 Гб (предельный размер String типа) теоретическое, но на практике не советую кодировать файлы больше 10Мб — слишком долго, хотя использование прогресса в состоянии хоть чуть чуть веселит в процессе, все равно не дождетесь, лучше сначала сжать архиватором.
Ограничения по длине ключа 30 символов (так мне захотелось — программисты могут довести до тех же 2Гб), ограничений по символам, используемым в ключе нет. Все что есть в ACSII — все можно, в том числе и пробелы.
Ну а вот о практической пользе этого творения решать все таки Вам. Знаете часто бывает, что есть цель, а средства нет. Ну так вот Вам средство, а цели выбирайте сами:)
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Склонен согласиться с автором: средство есть, цели/задачи подберем
Скажите, а есть ли возможность шифровать отдельные справочники 1с? например физ.лиц? или контрагентов?
а то с этой защитой персональных данных…….
(2) itar59, Возможность конечно есть. Но эта обработка лишь инструмент шифрования — дешифрования в самой простой форме. Для более сложных задач нужны отдельные процедуры и встраивать в них эту обработку.
Например пишите шифрование справочника Сотрудники перебором всех сотрудников с передачей текстовых полей в обработку и возвратом результата. Но для практической работы нужно при открытии 1С или нужного справочника его дешифровать. Опять что-то пишите. Цепляете автоматическую процедуру шифрования при закрытии и т.д.
Но это, паллиатив…
В дбф базе клюшки можно это сделать проще шифруя при закрытии и дешифруя при открытии файлы нужных справочников, но никто не гарантирует, что их не сопрут в процессе работы. Короче это тема отдельной большой работы и публикации. В чистом виде от кражи персональных данных эти обработки Вас не спасут:)
Респект автору! Хорошо!
Однозначный плюс автору, вещь пригодится 🙂
Хорошая вещь!
Любопыная штука. Надо токо выбрать где ее использовать
Насколько я понял, этот способ называется ««. («…изобретался многократно…») Считается, что в эпоху компутеризации его достаточно легко расколоть, если иметь представление об исходном тексте. То бишь от агентов ФСБ, ЦРУ, ВЖМЗ — не спасёт. От неспециалистов — может помочь, но тут нужна отработанная технология работы, чтоб расшифрованные данные не оставались где-нибудь в месте, легко доступном для простого копирования. (См. коммент 3).
Насчёт количества проходов я не понял. Если они делаются по тому же самому ключу, то являются зряшной потерей времени.
PS Однако обработку я не качал, и основываюсь только на тексте публикации.
(8) gaglo, Прочитал про шифр Виженера. Да алгоритм, если не вдаваться в детали похож. Но вот количество проходов это на самом деле смещение после смещения. То есть В один проход один символ смещается относительно ключа, при втором проходе полученный символ смещается относительно следующего символа ключа, при третьем новый символ смещается относительно следующего символа в ключе и т.д. То есть классические методы взлома нужно дополнить методами определения количества проходов кодирования (а ведь была мысль сделать количество проходов равным длине ключа или порядку сивола в ключе, но как оказалось независимая величина все же лучше).
По поводу специалистов ФСБ, ЦРУ и иже с ними скажу так: Если бы мне удалось создать шифр, с которым бы они не справились, то работал бы я не там где сейчас и, совсем за друге деньги:)
А вопрос о том на каждую ли «Энигму» найдется свой Тьюринг давайте оставим открытым, тем более что это очень интересный вопрос:)
Насколько я понял это простое гаммирование.
(10) alprk, Ну немножко усложненное количеством проходов. Считаем доказанным, что алгоритм не мой, хотя о шифре Виженера и гаммировании я узнал из комментариев. Да, это просто средство защиты информации от несанкционированного доступа. Но знаете, если бы я давал гарантии надежности шифрования и провел анализ криптографичекой стойкости, то публикация была бы уже платной:)
Добрый день.
Думал как же Вы это сделали стандартными средствами 1С?
А у Вас «vbscript»… я к сожалению в этом не силён.
Но смысл вижу тот же — с избыточным прибавлением-вычитанием через 255.
Тоже когда-то пробовал шифровать текстовые файлы стандартными средствами 1С 🙂
Через «открыть файл», «получить строку»… ага, в конце которой соответственно стояли непечатные символы «Симв(13)+Симв(10)» да и ограничение 1С на одну текстовую строку 500 символов (кажется). Для шифрования использовался исключительно цифровой ключ (с разрядностью 46-49, какая получится из исходного «пароля», алгоритм можно глянуть в прицепленом файле. А то у Вас до 30 символов, но пользователю такое запомнить весьма сложно. У меня из короткого пароля — обработкой делался длинный, за пользователя :-)).
И вроде всё было хорошо, НО просто цифровой ключ — показалось мало и слишком наглядно :-). Усложнил. Кроме символа ключа у меня использовался ещё и предыдущий символ текста.
И вот тут с ограничениями 1С случилась такая закавыка… после шифрования некоторых файлов при некотором пароле возникали строки более 500 символов, которые 1С при дешифровке (вот уж не помню) толи тупо обрезала, толи вылетала… короче информацию восстановить не удавалось. Да и при кодировке ASCI как выяснилось при одном и том же файле и ключе переносов строк возникало намного больше (или меньше уж не помню), чем при DOS… как ни странно.
Но при Вашем использовании «vbscript» это вполне возможно сделать.
(12) Kurt, VbS здесь выступает как средство обработки файлов, причем любых. Если Вы заметили то файл кодируется / раскодируется частями. Ничего не мешало сделать это целиком кроме скрипт контроля, который не видя отзыва от скриптовой процедуры начинал выкидывать предупреждения. Поэтому я разделил процесс на части с отзывам через 10 000 байт и получил возможность вывести состояния и скрипт контролю некогда включиться. Но это я к чему… Ваша проблема длинных строк вполне может быть решена ограничением считывания за раз тех же 500 символов. Если есть очень большое желание, я напишу вам функцию чтения и записи файла нужными порциями на VbS, а уж дальше можете попробовать вдохнуть вторую жизнь в свои идеи, мне они кажутся достаточно интересными.
Если что пишите в личку.
Такой механизм возможно действительно где нибудь пригодится. К сожалению из за использования внешних средств возникают вопросы о универсальности.
(14) karakozov, Вы о VBS? Сервер сценариев Windows стоит на всех Windows c 2000, если конечно на версии ниже винды работать, то его потребуется установить, но какая Win98, потянет восьмерку вопрос интересный…
Давайте тогда сразу и восьмерку назовем не универсальной, потому что она не на всех Windows работает:)
Надеюсь на вопрос об универсальности я ответил.
(13) ну это я делал (пробовал) «бантики» для удовлетворения собственного любопытства. Никакой практической цели я не ставил.
Из этих экспериментов у меня родился вердикт: «Эх нет в 1С инструментов для побайтной работы с любыми файлами». 🙂 ..а былоб хорошо.
Собственно на этом эксперимент и заглох.
Кстати в военной аппаратуре используется любопытный алгоритм «Сложение по модулю 2». В двоичной системе (т.е. побитно) исходная информация складывается с ключем. Повторное наложение ключа (опять же по модулю 2) возвращает исходную информацию в первоначальный вид 🙂
(16) Kurt, Это уже не столько в тему данной публикации, но как Вы думаете, 5-6 функций для работы с байтами и для бинарного доступа на основе VBS для 1С будут полезны сообществу? Может сделать еще такую публикацию?
(17) «Может сделать еще такую публикацию?» — если Вас не затруднит, если Вам это интересно. Это решать Вам.
dusha0020, я лично считаю, что любые инструменты расширяющие функционал 1С имеют место быть (или имеют право на жизнь :-)!
«будут полезны сообществу?» — это решит сообщество.
(19) barsa-05, Ну так работает же!:) Пользоваться нужно, если есть потребность, а понимают пусть другие. Я вот тоже не понимаю как Windows работает, но пока пользуюсь:)
Респект! полезная штука
(0) Простите, не могу понять, а нафига это?
Если для клюшек это еще как то можно понять, то для 8ки чем не устраивает стандартный пароль на текстовый модуль?
Текстовые модули никто не ломает, код замечательно восстанавливается из байт кода. То есть в данном методе относительно 1С защиты 0.
(22) WiseSnake, Так мы защищаем файлы, а не только текстовые модули. Любые файлы. И любой текст. О применимости, как говорилось в статье судить не мне.
(23) Ясно, но для защиты (кодирования) файлов есть очень много программ(способов), а вот для дельной защиты кода пока ни одного.
+(24) А а ломать Ваш закодированный файл тоже не нужно, надо просто сломать модуль где он раскодируется и взять уже готовый… так что вот так
Плохо что текст шифрвуется с использованием Юникод символов. Их в текстовых полях 1Ски не вставить
(25) WiseSnake, Модуля мало. Нужно еще знать ключ, который в модуле не хранится… Допустим при клюшечной реазизации, при вводе ключа пользователем раскодировался ert и запускался удаляя себя же (раскодированного) с диска. При неправильном вводе ключа он восстанавливался не правильно и, соответственно НЕ запускался. Код шифратора и дешифратора при этом остается абсолютно открытым, зачем его ломать если без нужного ключа он не сможет правильно восстановить обработку?
(28) То же самое что вы упакуете в архив с паролем (ключом).
(27) Kyrales, ??? В семерке прекрасно вставляется. Да и в восьмерке где же вы получаете результат как не в текстовом поле формы? Если не трудно, опишите Вашу проблему подробнее — я постараюсь решить.
занятно
Нормально ,давно искал такую штуку.Спасибо.
Благодарю исползую правда немного для других целей.
(33) massqwest, А если не секрет для каких? А то меня WiseSnake мучает нафига ЭТО нужно. Вот и ответ будет:) Да мне и самому интересно.
Спасибо, интересная разработка.
«Жалко тратить жизнь, хотя может быть и очень интересно» мемовская фразаЭ, а так впечатлило Спасибо
(26)(30) А может при шифровании возникнуть ситуация возникновения в строке не печатных символов?
Таких как «Конец строки», «Перевод строки», «Символ табуляции» и пр. При шифровании файлов как бы и бог с ними. Но как их будет воспринимать 1С в обычных текстовых полях?
У нас при тестировании и исправлении базы на 7.7 1С бывает редко, но ругается на некоторые поля, что мол в них присутствут Запрещенные символы. Это при обычной работе (без шифрации). Показывает содержимое «плохого» поля — а там какая-то непечатная «кроказябра»…
(37) Kurt, Может и возникает, но Вы же используете в 1С: «Вова — «+СимволТабуляции (РазделительСтрок, РазделительСтраниц и т.д.)+»корова» и все нормально. Если Вы кодировали многострочный текст, то замечали что строки в нем разбивались по другому, а потом восстанавливались. Единственный символ, который, по моим наблюдениям, 1С не может включить в строку это Симв(0) — то есть нулевой байт.
При установке признака «Многострочный» для поля текста 1С просто вместо козявок на месте разделителя строк начинает новую строку, а в остальном это такая же строковая переменная.
На картинке образец того как выглядят в строке непечатаемые символы.
Интересный подход. Надо попробовать. Спасибо за разработку
интересаня обработка, очень пригодится если в большой организации не все письма для общего доступа то очень нужная вещь
(38) с текстом это мне всё понятно.
Я про (2). Тут-то 1С у нас (при тестировании и исправлении базы) и выдавала сообщения о «плохих» полях справочника (например).
«Многострочный» — он-то проглотит.
А как поведёт себя реквизит просто «Строка»?… а уж тем более «Число», «Дата» О_о … если кто-то попытается применить шифрацию ко всем реквизитам справочника.
(41) Kurt, Со строкой все нормально, а с реквизитами число и дата я даже не пытался пробовать. Результат шифрования и дешифрования — всегда строковая величина и сохранить ее в поля типа Число, Дата и тем более объекты метаданных нельзя. Название публикации
Заметьте, что ни о датах, числах речи не идет. На практике чтобы сделать содержимое справочника непонятным достаточно закодировать все его текстовые поля.
Если же не достаточно то нужен другой способ кодирования, основанный на 10-тичном а не 256-ричном алфавите.
Так что при шифровке справочника я просто обхожу не текстовые поля.
Уже встречал года три назад подобное решение.
Идея понравилась и в закладке текст она работает! Но, поигрался файлами с расширением .doc… НЕ работает расшифровка. Может дело, конечно, в OpenOffice (нет у меня MSOffice). Т.е очевидно еще есть над чем работать…
(44) Vitaly, Вот сейчас скачаю и сам попробую:) От расширения не должно ничего зависеть, да и от офиса тоже…
(44) Vitaly, Вот этот файл создан шифратором для семерки. У меня он прекрасно раскодировался. Попробуйте сами. Ключ — Ваш логин, с большой, конечно буквы:)
Установите его как источник, выберите, а лучше создайте файл-результат по кнопке выбора результата и «расшифровать». Ключ см. выше.
Насколько я понимаю «в взломах» (как говорила одна мадам: «я отлично разбираюсь в живописи: я 7 лет замужем за художником была»), так вот, сам файл никто взламывать не будет. Будут работать над механизмом, который шифрует/дешифрует этот файл.
Все работает. Зашифровал doc файл семеркой, вывесил здесь, скачал, расшифровал восьмерочной обработкой и читаю бувы вижу все форматы. TCmd пишет файлы идентичны.
(46) Действительно работает! Или глюк какой-то, или руки не из того места :)… Плюсую..
margo2007, насколько я понимаю, Вы не совсем в теме. Как и человек из (25). Зачем ломать механизм? Что это Вам даст, если у Вас нет ключа, с помощью которого была зашифрована информация? Алгоритм работы вообще может быть выложен(описан) в открытом доступе. Толку-то?
Попробуйте сломать WinRar, чтобы вскрыть запароленный архив… сильно Вам это поможет без знания пароля?
Не путайте «пароль для доступа» — где сама информация хранится в исходном виде (например Word). Или «ключ шифра» — где информация переработана и зашифрована на основе ЭТОГО ключа. ДРУГОЙ ключ не поможет, как и «взлом» механизма.
Это всё равно как пытаться дозвониться до кого-то НЕ ЗНАЯ его номера телефона 🙂 Даже если Вы вломитесь на АТС и «поломаете» её — то с нужным абонентом АТС Вас всё равно не соединит. Нужно знать номер абонента 🙂 Так что «механизм» тут совсем не причём.
Согласна, интересаня обработка, очень пригодится если в организации не все документы для общего доступа, то очень нужная вещь. Плюсую. Спасибо.
Спасибо за разработку. ее можно использовать кстати в 7-ке для шифрования внешних процедур которые могут храниться в текстовых файлах…
Интересный вопрос тут подняли надо будет посмотреть.
Надо обязательно попробовать! Спасибо!
в хозяйстве все пригодится. спасибо
Однозначно спасибо!! Пригодится наверняка.
хорошая тема, спсибо
(0)Здравствуйте. Придумываю средство искаженного представления строковых данных. Что-то вроде Вашего. Читаю Вики и проч…
А в Вашем алгоритме, правильно ли я понимаю, количество проходов применяется одинаковое для всех символов исходной строки? По логике результат — смещение кода символа будет одинаков у всех символов другой результирующей строки? Вот если мы к примеру шифруем поле наименование справочника Организации и ИНН организации, то если злоумышленник 🙂 знает ИНН, ему будет все равно, сколько проходов совершил алгоритм? Он может вычислить ключ по алгоритму и смещению вроде бы? Первый символ наименования будет одинаково смещен, как и первый символ ИНН? Второй символ наименования будет одинаково смещен, как и второй символ ИНН? Я правильно понял?
Я вот голову ломаю,алгоритм шифрования я закрыть не смогу, вероятно, что и некоторые исходные строки будут известны, типа ИНН. Тут скорее всего придется как-то использовать соседние символы, потому что если ограничиваться смещением, то в общем-то алгоритм не важен, если знаешь исходную строку…
Я тут подумал, что возможно, чтобы количество проходов сыграло свою роль, его тоже нужно менять каким-то образом…
Идеал — это . Но как это на «человеческом» языке выразить в 1С, к своему стыду не знаю… 🙁
Будем искать, или учиться, еще не решил 🙂
(61) samamoiloff, Да в общем-то. Количество проходов это количество смещений. Один проход — смещение относительно порядкового символа ключа, второй проход — результат предыдущего смещения мы смещаем относительно следующего по порядку символа и т.д. Например при трехпроходном кодировании первый символ текста шифруется через первый второй и третий символы ключа, второй символ текста через второй третий и четвертый символы в ключе и так далее. То есть если алгоритм шифрования открыт и количество проходов известно, то по известному слову подобрать ключ не так сложно. Если же количество проходов такой же независимый параметр шифра как и ключ, то подбор ключа будет сложнее, но нужно всего лишь пронализировать все практически возможные количества проходов. А их едва-ли из соображений быстродействия может быть больше 6-8.
А вообще Шеннон уже давно математически вывел требования к абсолютному шифру, дешифровка которого действительно невозвможна, но длина ключа для него равна длине шифруемого текста!
Так что при наличии знания и желания любые наши потуги на основании короткого ключа теоретически могут быть расшифрованы:)
(61)
Я в (12) вскользь коснулся этой темы. При этом могут возникнуть «не печатные» символы… А при кодировании числовых полей (где кроме цифр ничего использовать нельзя) возможно использование только десятиричного ключа, с избыточным прибавлением НЕ через 255 (таблицу символов), а через 10, чтобы на выходе также получить цифру.
Насчёт ИНН… Так как скорее всего большинство ваших клиентов из Вашей местности, то начальные 3-4 цифры у всех одинаковы и соответственно известны, таким образом и первые 3-4 знака ключа будет легко определить 🙂
Вот ещё один не безинтересный метод:
Первое наложение ключа шифрует информацию, повторное наложение возвращает её к исходному виду (в разделе «Булева алгебра» обратите внимание на первую таблицу a, b, a+b). По секрету 🙂 используется у наших военных с ключём 256 бит. И говорят стойкость шифра умопомрачительная. Но это при том условии, что передается речь (в цифре, например) и вычислить исходную информацию, а тем более её начало передачи очень затруднительно (потому как в отсутствии сигнала всё-равно что-то передается — мусор). Но для использования этого метода нужно байт разложить на биты… воооотъ.
(64)
А вот я тут подумал… почему нет? Мы можем ключ сам на себя со сдвигом наложить нужное количество раз… и уже использовать готовый и длинный, за один проход. Как-то так. Если не прав, то поправьте. 🙂 …да будет там заморочка с «концом» ключа, но помоему она решаема, типа ключ «начало» и ключ «дальнейшее продолжение».
Генерируем случайное число N;
генерируем N случайных значений.
Далее N проходов со смещением на N-ое значение
(66) Kurt,
Хорошая идея — удлиннение ключа. Но опять же, если смотреть с позиции теории информации степень энтропии шифра не увеличится, так как мерой увеличения длины выступает число проходов. Чем больше внешних и случайных параметров используются при шифровании, тем выше стойкость шифра, а в данном случае при открытом алгоритме все манипуляции с ключем видны и не усложняют дешифровку. Если же алгоритм кодирования закрыт, то сам алгоритм становится источником информации закрывающим исходный текст и увеличение сложности алгоритма, безусловно приведет к повышению стойкости шифра.
В идеале, мне кажется, эффективнее все-таки повышать криптостойкость делая вероятность появления каждого символа в зашифрованном тексте одинаковой (максимизация энтропии). Задумывался над такими алгоритмами вроде кода Шеннона-Фано, но здесь нужен предварительный анализ шифруемого текста и какая-то увязка этого анализа с будущим ключем. Самое противное здесь то, что исходные частоты символов — являются мощным источником информации для шифрования, но после шифрования теряются и шифрованный тест становится однородным, а значит мы потеряем эту информацию при передаче и не сможем расшифровать.
(67) А расшифровывать потом как?
(66) Да-да, мне тут такая мыслишка пришла. Если поделить ключ пополам и шифровать первую половину второй. Злоумышленник 🙂 знает кучу ИНН, но расшифровывает каждый раз очередной ключик, который опять-таки зашифрован и не подходит для других полей, потому что исходника он УЖЕ не знает! Уже можно ему рыдать…
(65) Kurt, Сложение по модулю 2 — действительно криптографически весьма интересная штука. Дело в том, что в отличие от букв 1 и 0 распределены в произвольном потоке практически равномерно, а это значит, что при столь же случайном ключе уловить систему в шифрованном потоке практически impossible:)!
Это то как раз таки не сложно. КодСимв() — возвращает номер байта десятичным числом, ну а перевод десятичного числа в двоичное задача хрестоматийная… Ну а дальше шифруем сложением по модулю 2 поток нулей и единичек и переводим по 8 штук в десятичное число — тоже банальная задача. А там Симв() — и получаем зашифрованный поток.
(70)dusha0020,
как думаете, вроде все логично, я про шифр ключа еще одним ключом? Зная зашифрованное и алгоритм, мы узнаем ключ, но он будет так же — результат шифрования, где будет известен только алгоритм и неизвестны исходная строка и ключ.
Не совсем. Чтобы расшифрованный ключ был разный, его каждый раз нужно шифровать по-разному. Или в разное количество проходов.
(68)
Таки этого можно достичь шифруя текст самим себя со сдвигом, с каким-либо шагом, или же куском этого текста (размер куска допустим зависит от первой буквы текста, которую мы шифруем только ключём, или от второй :-), которую мы шифруем уже и ключём и первой буквой текста). Одна буква поделится своей вероятностью с другой буквой, при нескольких наложениях (со сдвигом вперёд обязательно, иначе не расшифруешь), и не раз. Вероятность в тексте должна выровниться + ключем пройтись напоследок (и можно сзаду наперёд). Правда начало текста, ввиду малой энтропии, всё-таки остается под угрозой, и возможностью разматывания этого клубка (т.е. дешифровки).
(70)
..ээээ. Я тогда в школе болел :-))))))))) …и подозреваю, что на 1С это будет далеко не Формула-1. Но результат должен быть весьма «прикольный».
(73) В общем, я пробую ключ делить пополам и шифрую 2-х уровнево.
(0) Использую Вашу обработку для эксперимента?
(74) samamoiloff, Конечно используйте. Никаких ограничений на использование в целом и по частям для данной обработки нет. Мне даже интересен будет Ваш опыт, если поделитесь:)
(73) Kurt,
Это не получится. К моменту расшифровки Вы не сумеете восстановить первую букву только из ключа. Ключ и количество проходов — это источник информации для расшифровки. Если Вы будете шифровать еще какой-либо информацией, то ее также нужно будет передать (или иметь заранее) для успешного дешифрования. Функцию перевода десятичных в двоичные и наоборот я напишу и выложу. Очень все таки любопытно сложение по модулю 2 использовать… Если возьметесь с удовольствием оценю результаты.
(75)dusha0020,
Конечно! Почту за честь, как говорится. Сейчас, дорисую…
(73) Kurt, Ну и обещанные функции. Действительно коротко и по ресурсам системы не очень напряжно:
Показать
(75)dusha0020,

Вот, что получилось:
Я в качестве эксперимента оставил только 2 процедуры ОбработатьТекст и Кодировать, ну и вызов по кнопкам —
Передаю сразу оба текста, 1 и 2. В дальнейшем каждому текстовому элементу-очередной единице шифрования надо присваивать очередной номер. От этого номера будет зависеть количество проходов для шифрования самого ключа.
2. На исходную!
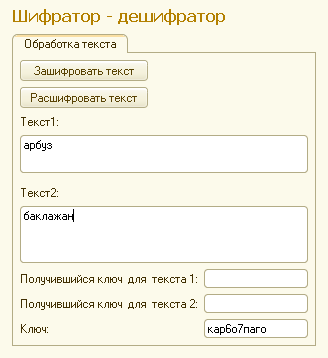
Вызываем процедуру ОбработатьТекст(Действие,НомерТекста) для каждого номера.
И для каждого номера на форму выводим получившийся ключ — результат шифрования первой половинки самого ключа им самим (второй его половинкой). Они естесственно разные.
Ну и результат шифрования разный :), конечно.
Вот процедурка:
Расшифровываем
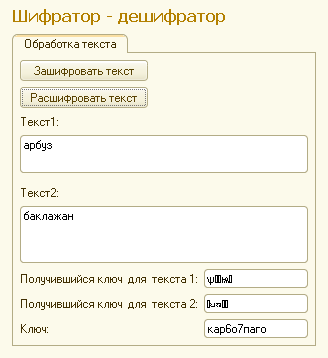
Тело кодирования я упростил. Ведь если известна исходная строка, которая кодируется и алгоритм будет открыт, то сильно упираться в нем смысла вроде нет…

Если знать, что 1 значение арбуз, а второе баклажан на 100%, можно ли узнать третье значение, зашифрованное таким способом?
(85) samamoiloff, Принцип работы я понял. Ключ шифрующий сам себя, а номер текста управляет количеством проходов. Интересно получилось, вариант очень хорош тем, что не позволяет брутальной атакой вести посимвольный подбор ключа на известных данных. Если при 2-х проходном кодировании ключ можно ламать двойками, при трех проходном — тройками символов то здесь бесперспективняк, ключ нужно знать целиком:)
Признаю, что Вы улучшили мой алгоритм настолько, что перспективы взлома по известным значениям превосходят мои скромные познания в криптографии:) Могу сказать что узнать 3 значение по известным первым двум при неизвестном алгоритме шифрования -практически не реально. Также не реально, если длина ключа превосходит общую длину известных значений. При невыполнении этих условий — взлом возможен, а вот насколько он сложен не могу сказать точно. Просто скажу что очень-очень-очень сложно и дорого.
Дешевле и быстрее взять паяльник и попросить Вас сказать ключ:)
(73) Kurt, Провел частотный анализ текста пояснения к этой разработке до и после шифрования. В чем-то Вы правы — после шифрования частоты выравниваются, но не так сильно как хотелось бы.
Графики исходного текста и результата 3-х проходного кодирования.
А вот так ли эффективно выравниваются частоты на глаз не определить:)
dusha0020,Kurt,
Спасибо огромное за анализ и за совместное творчество, мне тут надо в одной разработке применить это дело, а сам я не занимался такими вещами. Если что-то создам (речь про выгрузку данных через Конвертацию Данных 2.1 для аутсорсинга, на доработки, фрилансерам), то вам свою разработку вручу бесплатно (если нужна будет, конечно :-).
Благодарю.
(76)
Ну да. Я всё, что можно на вскидку, в кучу намешал..
Если мы шифруем ключём, то первую букву мы легко получаем — ибо она только ключем и шифруется (это я такой вариант предлагаю). К моменту расшифровки второй буквы — первую мы уже получили, к моменту расшифровки третьей — у нас уже есть вторая… не понял в чём проблема? Если 6 наложений ключа, то 5 снимаем, а уж потом берёмся за сам текст. — И это ещё не шифровка, так сказать текстом… это шифровка предшествующей буквой. Хотя можно и все 6 сразу снять. А потом восстановить последующий текст, ибо первая буква уже есть — а вторая, третья и т.д. зашифрованы предшествующей.
Если примешивали сюда и сам текст (НО с обязательным условием со сдвигом, т.е. не с первой позиции начинаем накладывать) — то и в процессе расшифровки начального куска — начинаем и получать текст (может быть и просто КУСОК — длина которого допустим зависит от пятой буквы ключа :-), или суммы 2,5,7 символа ключа), который уже с каким-то шагом, например с 8 позиции (тоже может зависить от символа ключа) — так же накладывается на исходный текст. Но это конечно исключительно для больших текстов, а не для полей 1С длиной 10-15 символов.
«..источник информации для расшифровки..» — но мы же не будем всем рассказывать какой у нас ключ? :-)))
(86)
Вспомнил. У военных ключ (тот который 256 бит) тоже получался не просто так. А наложением двух перфолент (да, да. там до сих пор так всё «сложно», а на самом деле получается проще некуда… легко считывается и уничтожается перфолента просто), ну не буквально, а так же «Сложением по модулю 2». Так что если враг и умудрится заполучить хоть одну перфоленту (а там с этим ОООЧЕНЬ строго) — ему это не поможет, нужна вторая. А и за первой и за второй глаз да глаз.
(87)
Главное, я думаю, что такое шифрование даёт перекос частот! Т.е. если буква «П» в исходном варианте имела порядка 50 штук (или в чём там?).
То после шифрования мы имеем знак «<» в количестве 50 штук — который в свою очередь «по стечению обстоятельств» ранее мог быть и «А» и «Г» и «Ь»… )))))))))))))
К тому же.. а вы обратили внимание на ЛЕВУЮ шкалу? Помоему результат более чем хорошь. Максимальные повторения 82 против 400! Выравнивание так сказать в 5 РАЗ.
Пропустил возврат счетчика «ы» перед началом второго цикла. Хотя в первом цикле при условии, что длина второй половины будет равна длине первой, то «ы» будет возвращаться и так в «1». Ну уж на всякий случай выложил новую версию :))
(78) Ну вот тогда Вам и функции «Сложение по модулю 2» :-). Тоже думаю не очень напряжно:
Показать
Не проверял. Если есть косяк — намекните.
(93) Kurt, Косяков не вижу. А вот сложение по модулю 2 можно делать проще:
БитСМ2 = (БитТ+БитК)%2;//Если оба бита числовые, или перевести в числа перед сложением.
Для 1С-ки здесь возникает еще один трабл. Проблема нулевого байта. Если в результате шифрования у нас получится байт целиком из нулей, то Симв(0) ничего не вернет. Ничего не запишет в строку и с этого места мы потеряем способность расшифровывать.
У меня обязательно через n символов попадается нулевой байт и с него дешифровка становится невозможной. То есть нужно как-то обходить эту ситуацию при текстовом кодировании.
У меня такой код все делает. Переменная действие вроде бы утрачивает смысл, так как одним сложением кодируем, а другим декодируем, но с учетом того, что требуется особая обработка нулевых байтов может в ней и будет смысл.
Показать
(93) Kurt, однако… при взломе «Сложения по модулю 2» на последовательности «нулевых» символов — мы сразу получаем ключ (на бинарной последовательности единиц — инвертированный ключ). Таки всё равно надо будет извращаться с несколькими проходами 🙁 Или искусственным удлиннением и трансформированием ключа из исходного… хм.
С другой стороны ключ даётся только тем людям которые будут шифровать или расшифровывать — и он и так выходит в открытом виде, а остальным этот ключ давать ниизяяя.
(88) samamoiloff, Не за что. Тем более, что общение принесло взаимное обогащение опытом и идеями!:)
(94)
Я конечно дремучий… Я не знаю что это за конструкция (%), я не знаю как оно работает. Я видел в модулях 1С, что программисты 1С используют % — но ничего не нашел про это в Книжках по 1С 🙁 …как будто это само собой разумеющееся. (развожу руками)
(95) Kurt,
Если вообще говорить о шифрах — то у них две слабости: алгоритмы шифрования — дешифрования и ключи.
Причем потеря ключа отнюдь не так страшна, если не утрачен алгоритм — просто не зная как ключ применить к шифру мы ничего не добьемся. Потеря алгоритма — намного страшнее, понятно что в этом случае дешифровка становится вопросом времени, но какого времени также зависит от сложности алгоритма. Допустим расшифровка «Бомбой» приказов немецким подводным лодкам не имела ценности, пока на дешифровку уходили недели.
Только усовершенствовав саму машину и алгоритмы криптоанализа Тьюринг добился приемлемой скорости дешифрования.
А ключей англичане не знали никогда — захватили «Энигму» и узнали алгоритм.
(94)
Т.е. насколько я понял представленный код этой проблемы не решает? (Или я не понял?)
(98) Kurt, (99) Kurt, % Это остаток от целочисленного деления. Целочисленное деление это сколько раз (именно целых раз) знаменатель помещается в числителе.
В случае с битами:
(0+0)/2 = 0 (без остатка или остаток 0)
(1+0)/2 = (0+1)/2 = 0 (и 1 в остатке!)
(1+1)/2 = 1 (снова без остатка то есть остаток 0)
Представленный код, действительно не решает проблемы нулевых байтов. Кстати и в исходном коде обработки была подобная проблема, там было написано так:
То есть когда при сложении кодов символа и ключа за минусом 255 мы получали 0 то присваивали кодированному символу 255 номер, а при расшифровке
Делали нечто обратно, чтобы избежать появления симолов с нулевым кодом.
(100) спасибо за разъяснение по %.
Да. С Симв(0) действительно проблема, да и с КодСимв(«») — тоже, ничего нет, а он выдаёт 0.
(может в своё время моя «расшифровка» именно по этой причине сыпалась, что при шифровке были выкинуты нулевые значения, а не из-за ограничения на длинну строк? Я в то время про ноль и не задумывался)
Да и у Вас этот метод не спасёт, потому как если был 0, то он превращается в 255, а если был 255 .. то и нехай 255. А это были разные «символы»… при расшифровке напутает.
Вот сижу читаю
И опять же выход предлагается через всякие «внешние» вещи. 🙁
Вот ещё приблизительно на ту же тему
(101) Да и вообще подумал.. у нас же эта система счисления 255 выходит искусственная. Мы сами контролируем верхний порог (или 0, как Вам будет угодно).
Т.е. если исходить из того, что Символа «0» нет и он вообще не используется (его нельзя использовать), то нам нужны значения с 1 до 255.
От 0 мы отказаться не можем так как в результате избыточных вычислений мы всё равно будем его получать. Но мы можем ограничить верхний порог контроля. В таком случае он должен быть 254! У нас на выходе будут числа 0-254… да? А потом мы делаем Симв(х+1) и получим символы с 1 до 255, что и требовалось. И никаких нулевых значений.
Вот до такого я додумался.
(102) Kurt, Думаю и так можно. У меня
Если ПК<1 тогда
КодШифр = ПК + 255;
Множество значений ограничено снизу, Вы выбрали ограничить сверху. Почему бы и нет?:)
Самое интересное то, что в большинстве языков программирования (ну тех в которых я хотя-бы немного писал) проблемы с нулевым байтом нет. Поэтому любой даже скриптовый язык, легко запишет и прочитает нулевой байт, и кодирование методом СМ2 файлов не требует таких заморочек, потому что для бинарной обработки нам полюбому нужен другой язык, отличный от 1С.